- The paper introduces cautious optimizers, a one-line modification that refines momentum-based methods by ensuring directional alignment and monotonic loss reduction.
- It employs a sign-based masking strategy integrated with Hamiltonian dynamics to reduce overshooting and oscillations during training.
- Empirical results on LLaMA models and ImageNet tasks demonstrate improved sample efficiency and lower validation loss compared to standard optimizers.
Cautious Optimizers: Improving Training with One Line of Code
The paper "Cautious Optimizers: Improving Training with One Line of Code" introduces a novel approach to enhance momentum-based optimizers by introducing a simple modification. This modification, termed "cautious optimizers," aims to accelerate convergence and stability in training large models with minimal implementation effort, notably only requiring a single line of code change.
Introduction and Proposal
Optimizers like AdamW and Lion have been critical in training LLMs and other neural networks. However, despite numerous attempts to surpass AdamW, its status remains largely unchallenged due to complications in hyperparameter tuning and computational overhead associated with alternatives. The paper proposes a family of cautious optimizers, such as C-AdamW and C-Lion, which implement a sign-based masking strategy to ensure alignment between proposed updates and current gradients.
The key insight is in preserving the convergence properties of existing optimizers while promoting a monotonic decrease in loss functions. The modification works by introducing an element-wise mask that adjusts updates based on sign consistency between update directions and gradients.
Theoretical Framework
The theoretical foundation of cautious optimizers is rooted in Hamiltonian dynamics and Lyapunov analysis. For continuous-time momentum-based algorithms, the authors provide a framework ensuring convergence towards local optima without compromising the inherent descent properties found in the original algorithms.
Hamiltonian Dynamics
The continuous-time system underpinning momentum methods can be described by a Hamiltonian that combines potential (loss) and kinetic (momentum) energy, ensuring the total energy is decreasing. The cautious optimizer modifies this dynamic by enforcing alignment conditions on updates, preserving a decentralized structure conducive to stable convergence:
$\bw_{t+1} \gets \bw_t - \epsilon_t \bu_t \circ \phi(\bu_t \circ \bg_t),$
where ∘ denotes element-wise multiplication, and $\phi(x) = \ind(x > 0)$ acts as the masking function. This guarantees that updates reduce loss monotonically, avoiding the oscillations typical of conventional momentum dynamics.
Empirical Results
The empirical evaluations demonstrate the practical advantages of cautious optimizers in both toy and large-scale settings.
Toy Experiments
The minimal setup using gradient descent with Polyak momentum (GDM) and its cautious variant (C-GDM) shows that cautious masking significantly curtails overshooting and oscillations, ensuring smoother and faster convergence to minima.
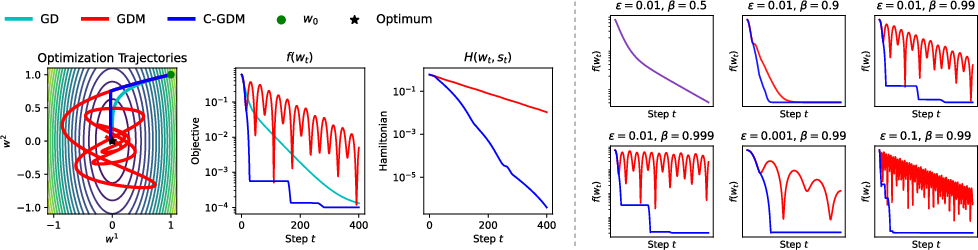
Figure 1: Left: We compare gradient descent with Polyak momentum (GDM) against its cautious variant (C-GDM).
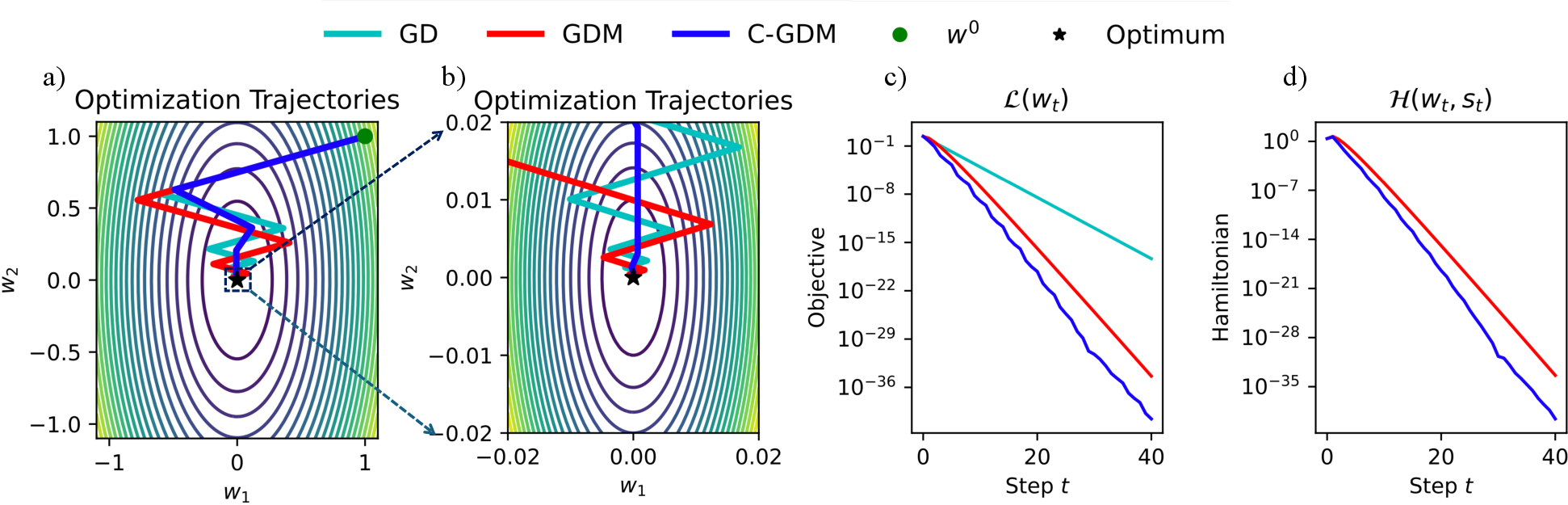
Figure 2: We compare gradient descent with Polyak momentum (GDM) and its element-wise cautious variant (C-GDM).
Large Scale Pretraining
Pretraining experiments on LLaMA models across sizes from 60M to 1B parameters reveal that cautious variants are more sample-efficient than their standard counterparts, especially in larger models. This efficiency translates into better convergence rates and lower final perplexities on validation datasets.
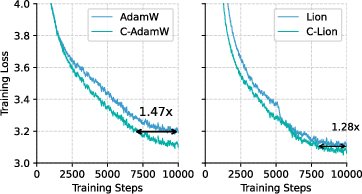
Figure 3: Training Loss Curves on LLaMA 1B, using AdamW / Lion and their cautious variants.
In the context of image recognition via Masked Autoencoders (MAEs) on ImageNet, C-AdamW achieves lower evaluation loss compared to baseline AdamW, highlighting its capacity for superior representation learning.
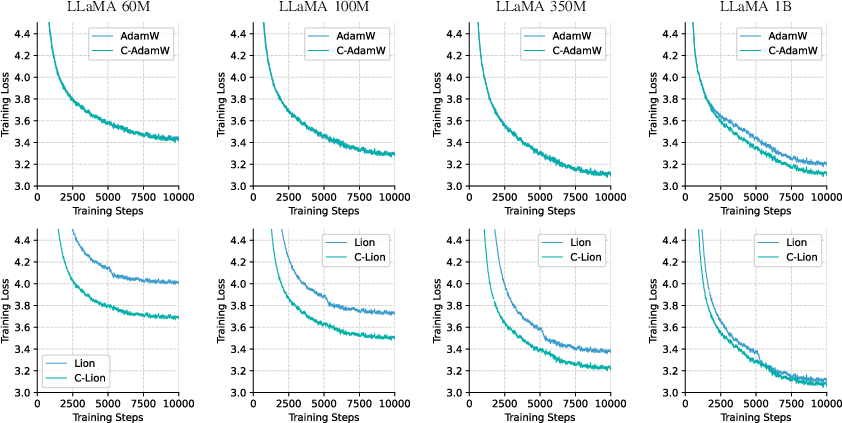
Figure 4: Training loss curves for AdamW, C-AdamW, Lion, C-Lion on LLaMA with 60M, 100M, 350M, and 1B parameters.
Implications and Future Directions
The introduction of cautious optimizers offers significant implications for the field, providing a straightforward technique to enhance existing optimization frameworks without convoluted strategies or hyperparameter modifications. This flexibility allows broader applicability across different domains of AI, potentially fostering further advances in training efficiency.
Future research could explore alternative masking functions or scaling cautious optimizers for eigenspace convergence rather than purely parameter space adjustments. Moreover, a detailed analysis of convergence rate improvements could offer deeper insights into the foundations laid by cautious optimizers.
Conclusion
Cautious optimizers present a scalable, practical approach to accelerate the performance of momentum-based optimizers with negligible computational cost. The paper suggests promising avenues for optimization improvements, potentially reshaping the landscape of training methods in deep learning. Such enhancements signify a step forward in the continuous quest for more efficient and reliable AI systems.

