MMGraphRAG: Bridging Vision and Language with Interpretable Multimodal Knowledge Graphs
Abstract: Retrieval-Augmented Generation (RAG) enhances LLM generation by retrieving relevant information from external knowledge bases. However, conventional RAG methods face the issue of missing multimodal information. Multimodal RAG methods address this by fusing images and text through mapping them into a shared embedding space, but they fail to capture the structure of knowledge and logical chains between modalities. Moreover, they also require large-scale training for specific tasks, resulting in limited generalizing ability. To address these limitations, we propose MMGraphRAG, which refines visual content through scene graphs and constructs a multimodal knowledge graph (MMKG) in conjunction with text-based KG. It employs spectral clustering to achieve cross-modal entity linking and retrieves context along reasoning paths to guide the generative process. Experimental results show that MMGraphRAG achieves state-of-the-art performance on the DocBench and MMLongBench datasets, demonstrating strong domain adaptability and clear reasoning paths.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces MMGraphRAG, a new way for AI to answer questions using both text and images. Think of it like a smart student who, before answering, looks up facts in a well-organized library and also checks pictures for clues—then clearly shows how it found the answer. The key idea is to turn both words and images into a connected “map of knowledge” so the AI can reason across them step by step, instead of guessing.
What questions are the researchers trying to answer?
The paper focuses on three simple questions:
- How can we make AI use both text and images together, not just one or the other?
- How can we help AI understand the structure of information—who is related to what—so it can reason better and avoid making things up (hallucinations)?
- Can we build a system that works well across different topics without special training, and that explains its reasoning?
How did they do it?
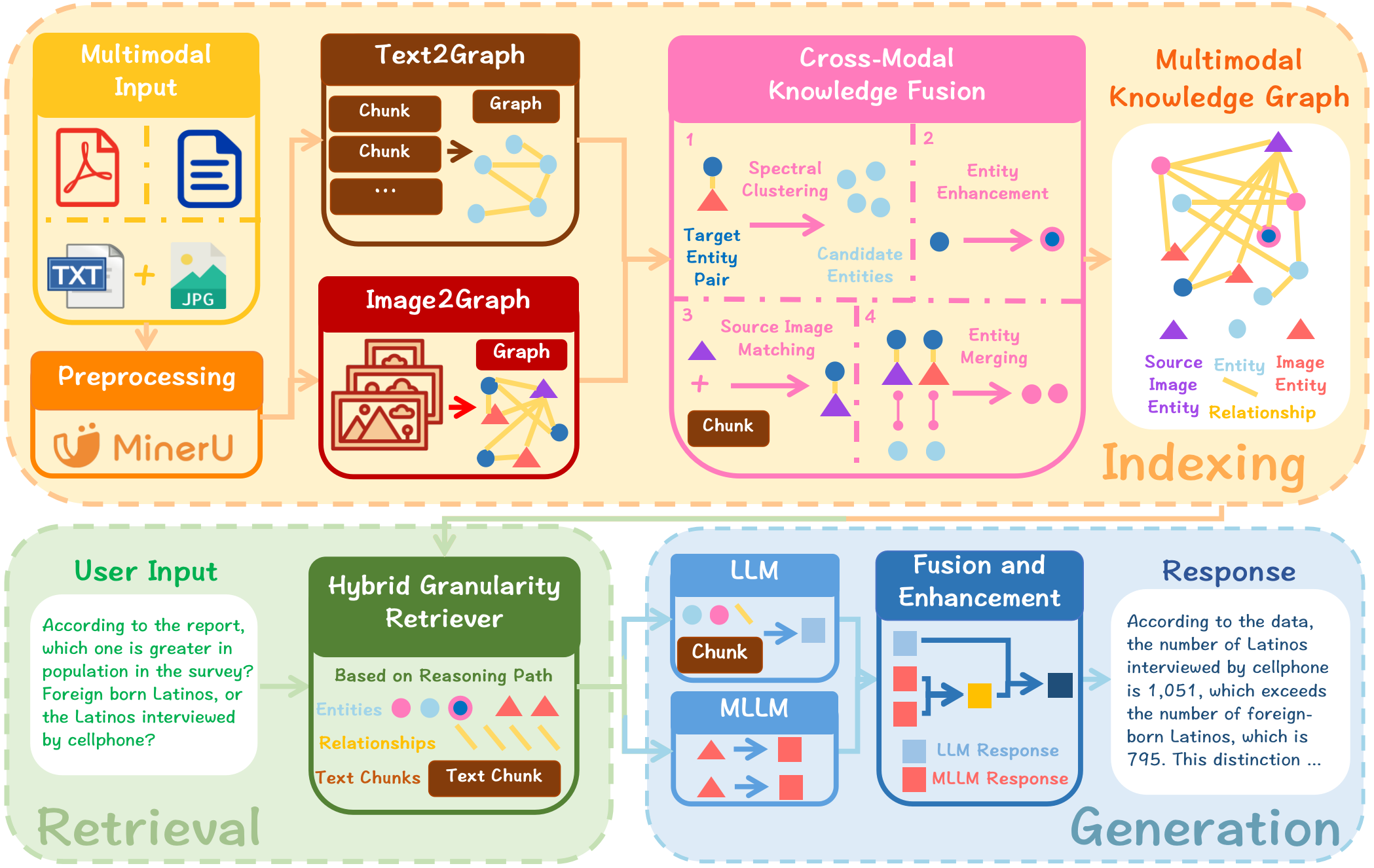
To explain the approach, imagine building a city map where words and pictures are buildings, and the roads between them show how they’re connected. The AI uses this “map” to travel along meaningful paths to find answers.
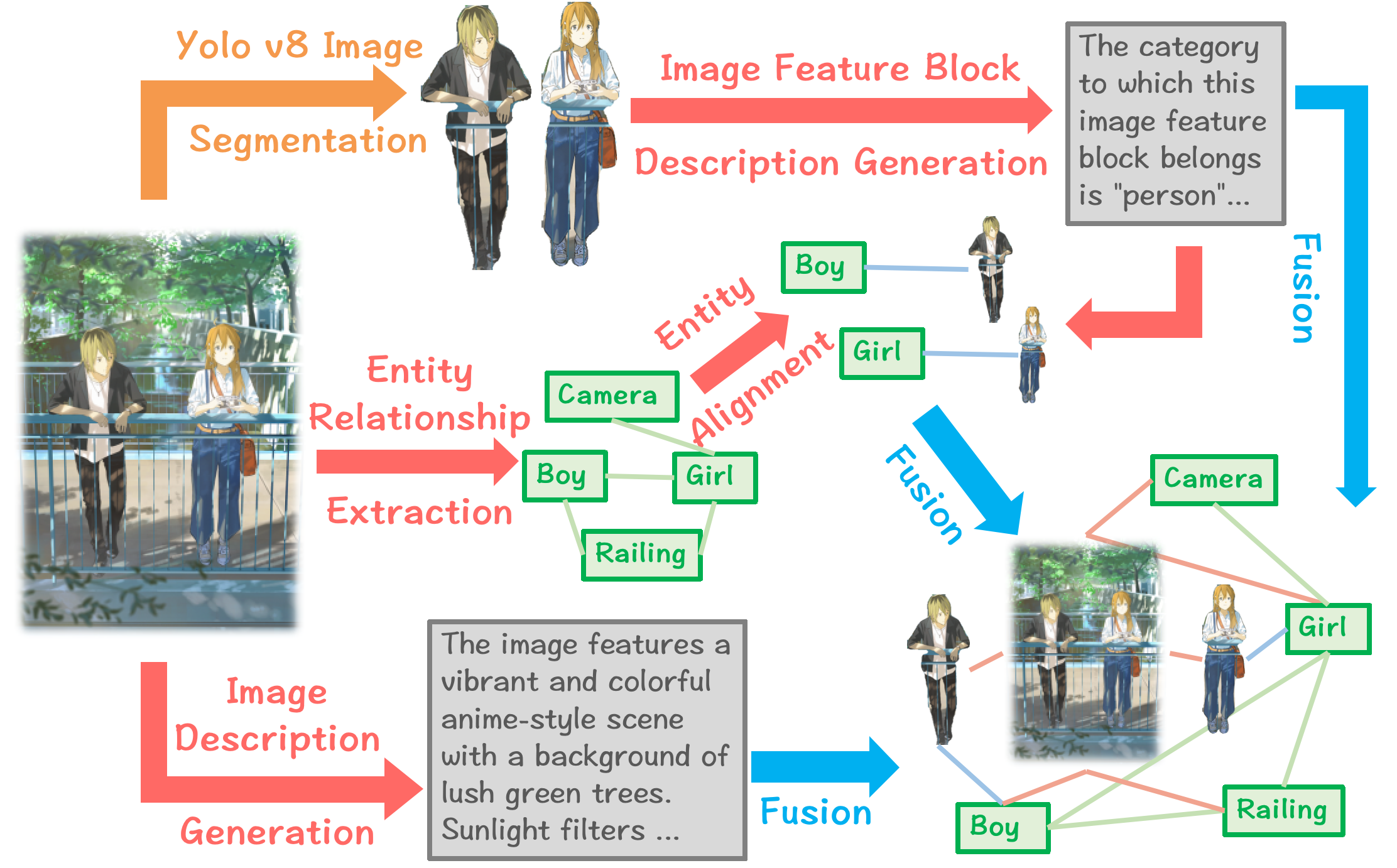
Turning images into graphs (scene graphs)
- A scene graph is like labeling a picture with “objects” and “relationships.” For example: “girl holds camera,” “boy stands next to girl.”
- The system breaks an image into parts (like cutting a photo into meaningful regions), describes each part in words, picks out the important objects, and connects them with relationships. This turns a picture into a small knowledge graph.
Linking images and text (cross-modal entity linking)
- Problem: The same thing can appear in text and images (e.g., a chart in a report and the words describing it). We need to match them.
- Solution: The system matches items from images to items in text by grouping related candidates smartly using a method called spectral clustering.
- Simple analogy: Imagine grouping students not just by how they look similar (appearance), but also by who they hang out with (connections). Spectral clustering uses both “how similar” and “how connected” information to form better groups.
- After grouping, a LLM picks the best match between a visual thing (like “flooded street” in an image) and a text thing (“Hurricane Ian damage in Florida”).
Building one big multimodal knowledge graph (MMKG)
- After linking, the system fuses the image graph and the text graph into one larger, cleaner knowledge map that covers both types of information. It also enhances leftover image descriptions using related text (e.g., adding “in Florida” to “a flooded neighborhood” if the text says so).
Finding and using information (retrieval)
- When asked a question, the system follows paths through this graph to pull the most relevant bits—like traveling along roads on the map from one clue to the next.
Generating the final answer
- The system first drafts an answer with a text model.
- Then it asks a vision-LLM to consider both images and text and add multimodal details.
- Finally, it merges these into one clear, consistent answer—with a reasoning path that’s easier to trace.
What did they find, and why is it important?
- MMGraphRAG beat other strong methods on two tough test sets for question answering with documents:
- DocBench (documents across fields like academia, finance, law, government, news)
- MMLongBench (long, mixed-format PDFs with text, tables, charts, figures)
- It was especially strong on:
- Questions that need both text and images to answer
- Complex, multi-step reasoning across pages and formats
- Identifying unanswerable questions (so it’s less likely to “make things up”)
- It worked well without extra task-specific training, showing good generalization.
- It provided clear “reasoning paths,” which makes its answers more interpretable—you can “see how it got there.”
They also created a new dataset and method for cross-modal entity linking (matching image things to text things):
- CMEL dataset: A benchmark for testing how well systems match entities across text and images in realistic documents (news, papers, novels).
- Spectral clustering method: Improved the candidate matching step by considering both meaning and connections, leading to higher accuracy than other clustering or embedding-only methods.
Why does this matter?
- Better use of multimodal information: Many real documents mix text, pictures, tables, and charts. This approach helps AI truly combine them, rather than treating images as an afterthought.
- Fewer hallucinations: By following reasoning paths on a knowledge graph and checking both text and images, the system is less likely to produce confident but wrong answers.
- Works across domains: Because it doesn’t require heavy retraining for every new topic, it’s useful in areas like finance, law, science, and news.
- More transparent AI: Showing the reasoning path makes answers easier to trust and verify.
- Helps future research: The new dataset (CMEL) and the linking method give others tools to build better multimodal systems.
In short, MMGraphRAG is like giving AI a well-organized, cross-linked map of both words and pictures, helping it find answers more accurately, explain its thinking, and handle real-world, mixed-format documents with confidence.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues, missing analyses, and open research questions raised by the paper that future work could concretely address:
- KG schema and ontology design are unspecified: entity/relation types, normalization rules, and cross-modal schema mapping are not formalized, making replication and extension difficult; evaluate how different schemas impact retrieval and reasoning quality.
- Spectral clustering hyperparameters and sensitivity are underexplored: no details on choosing the number of eigenvectors , DBSCAN parameters (eps, min_samples), or stability across document sizes; provide systematic tuning guidelines and robustness analyses.
- LLM-determined relation weights in the adjacency matrix lack reproducibility and rigor: quantify variability across prompts/models, study deterministic alternatives (rule-based, learned scalers), and assess their effect on CMEL accuracy.
- Candidate set restriction to a local textual window ( to ) may miss long-range or cross-page links: measure recall loss and develop global or hierarchical candidate generation strategies for cross-document alignment.
- Visual features are not explicitly leveraged in CMEL (alignment appears to rely on MLLM-generated text descriptions of image regions): compare to methods that incorporate native vision embeddings (e.g., CLIP, SigLIP, ViT features) and hybrid text+vision aligners.
- Scene graph quality is not evaluated: benchmark entity/relation extraction against standard datasets (e.g., Visual Genome variants), report precision/recall, and quantify hallucinated “implicit relations” introduced by MLLMs.
- YOLO is used for “semantic segmentation,” but YOLO performs detection (bounding boxes), not semantic segmentation: clarify the vision pipeline, evaluate segmentation/detection accuracy on document-specific visuals (tables, charts, diagrams), and test domain-specific detectors.
- Retrieval module specifics are missing: define the hybrid-granularity retriever’s scoring, path ranking, maximum hop depth, and k-values; provide ablations to show their contributions to end-task accuracy.
- Hybrid generation strategy lacks ablation and conflict-resolution details: quantify the incremental benefit of each stage (LLM draft, MLLM multimodal responses, LLM consolidation), and formalize how contradictory outputs are reconciled.
- Interpretability claims are unmeasured: propose metrics for reasoning-path fidelity (path relevance, coverage, minimality), human evaluation protocols, and automatic measures (e.g., path overlap with gold evidence).
- Unanswerable-question handling is not mechanized: define an abstention criterion calibrated to MMKG signals (e.g., path evidence sufficiency), measure calibration (ECE/Brier), and analyze failure modes on unanswerable cases.
- Scalability and efficiency are unreported: provide indexing and retrieval time/memory profiles, eigen-decomposition complexity on large KGs, cost per document for LLM/MLLM calls, and optimization strategies (caching, batching, model distillation).
- Error propagation across the pipeline is unquantified: analyze how detection errors, description generation noise, entity extraction mistakes, and alignment mislinks affect downstream QA; add uncertainty tracking and error-correction mechanisms.
- Baseline fairness and comparability need strengthening: GraphRAG was modified (community detection removed), MRAG comparisons used different model sizes across experiments; re-run baselines with matched settings/model sizes and include more MRAGs (VisRAG, MuRAG, ColPali) for comprehensive comparison.
- LLM-as-judge evaluation may introduce bias: complement with exact-match metrics where applicable, human assessment, and consensus grading; report inter-rater reliability and sensitivity to grader choice.
- CMEL dataset limitations require documentation: small size (1,114 instances), unclear annotation guidelines, inter-annotator agreement, negative examples, and label quality; publish detailed construction protocols, IAA statistics, and license/usage constraints.
- Generalization beyond three domains is untested: evaluate on scientific plots, engineering drawings/CAD, medical images, legal forms, and multilingual documents; study cross-lingual CMEL and MMKG construction.
- Global image entity alignment and “remaining entity enhancement” steps risk text-to-image leakage/hallucination: quantify how text-derived enrichment changes entity fidelity, and add safeguards (evidence tagging, provenance tracking).
- Cross-document MMKG construction and entity resolution are not addressed: design methods for deduplication, cross-document linking, and corpus-level reasoning; evaluate benefits for multi-document QA.
- Incremental/streaming updates and temporal reasoning are missing: develop online MMKG maintenance with versioning, time-aware entities/relations, and assess effects on up-to-date QA.
- Security and privacy considerations are absent: articulate policies for handling sensitive PDFs, PII redaction, and secure MMKG storage; evaluate attack surfaces (prompt injection via document content).
- Theoretical justification for spectral clustering choice is limited: provide formal analysis or bounds on clustering quality given mixed semantic+structural weights, and compare against alternative graph matching/alignment methods (e.g., spectral matching, GNN-based alignment).
- Hyperparameter defaults (e.g., k retrieved entities, token limits, chunk sizes) are not justified: include a principled tuning study and practical guidelines for different document types and lengths.
- Reproducibility assets are not detailed: release full code, prompts, model versions, preprocessing configs, seeds, and end-to-end pipelines to enable independent replication and extension.
Collections
Sign up for free to add this paper to one or more collections.