- The paper demonstrates that RLVR, contrary to expectations, shrinks the reasoning boundary by favoring high-likelihood solutions, reducing overall problem coverage.
- Empirical analysis reveals that increasing negative interference and winner-take-all effects lead to marked declines in Pass@k performance on diverse problem sets.
- The proposed SELF algorithm mitigates these issues by targeting low-likelihood problems and using forward KL regularization, thereby preserving reasoning diversity.
The Reasoning Boundary Paradox: How Reinforcement Learning Constrains LLMs
Introduction and Motivation
This work provides a rigorous analysis of the learning dynamics of Reinforcement Learning with Verifiable Rewards (RLVR) in the context of LLMs for mathematical reasoning. Contrary to the prevailing assumption that RLVR expands the reasoning capabilities of LLMs, the authors demonstrate that RLVR can in fact shrink the set of problems solvable within a fixed sampling budget (Pass@k), a phenomenon they term "reasoning boundary shrinkage." The paper identifies two key mechanisms underlying this effect: negative interference and a winner-take-all dynamic induced by on-policy RL objectives. The authors further propose SELF, a data curation and regularization strategy that mitigates these issues and empirically improves coverage.
Negative Interference and Winner-Take-All in RLVR
The central finding is that RLVR, when applied to LLMs, does not operate in a single, stationary MDP but rather across a collection of problem-specific MDPs, each with distinct reward landscapes. This leads to cross-problem interference: optimizing for one problem can degrade performance on others due to shared model parameters and correlated gradients.
The authors formalize this with a per-step influence metric, quantifying how updates for one problem-solution pair affect the log-likelihood of correct solutions for other problems. Empirically, they show that as RLVR training progresses, the magnitude of negative interference increases, leading to a monotonic decline in Pass@k for large k (i.e., the model's ability to solve a diverse set of problems within k attempts decreases).
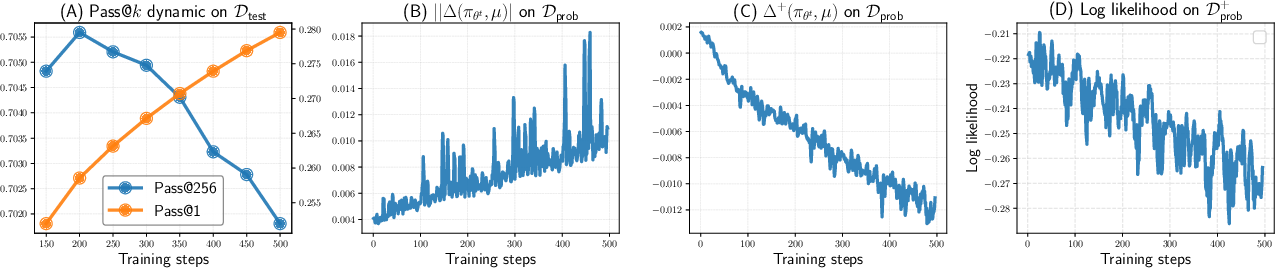
Figure 1: RLVR improves average accuracy but reduces coverage (Pass@256), with increasing negative interference and declining model confidence on previously correct solutions.
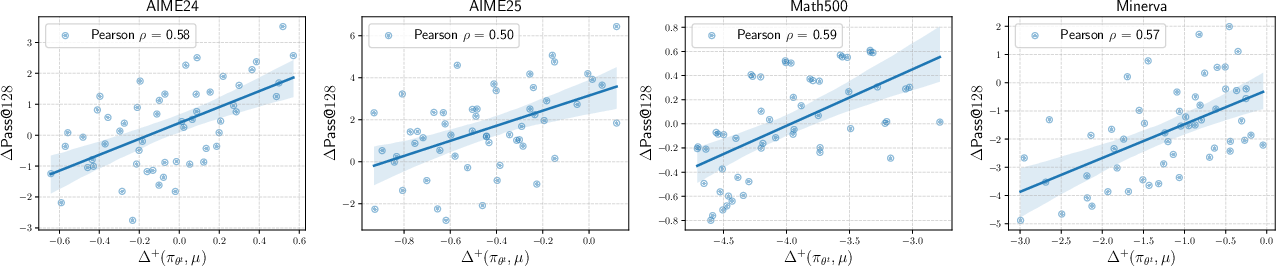
Figure 2: Strong correlation between negative interference and Pass@k decrease across benchmarks.
The winner-take-all effect is a direct consequence of on-policy RL: problems for which the base model already assigns high likelihood to correct solutions are further reinforced, while problems with low initial likelihood are neglected or actively suppressed. This is exacerbated by the vanishing gradient problem for low-likelihood solutions in REINFORCE-style updates, and by the fact that on-policy sampling provides no learning signal for problems where the correct solution is rarely sampled.
Empirical Analysis of Learning Dynamics
The authors conduct extensive experiments on Qwen2.5-Math-1.5B/7B and Llama-3.2-3B-Instruct models, using mathematical reasoning benchmarks (AIME24/25, Math500, Minerva). They track Pass@k, per-step influence, and perplexity metrics throughout RLVR training.
Key empirical findings include:
- Pass@k declines with RLVR: While Pass@1 (greedy accuracy) improves, Pass@k for large k consistently declines, indicating reduced coverage.
- Influence strength increases: The model's updates increasingly affect unrelated problems, indicating loss of problem-specificity and diversity.
- Negative interference is predictive of coverage loss: The per-step influence metric is highly correlated with Pass@k degradation.
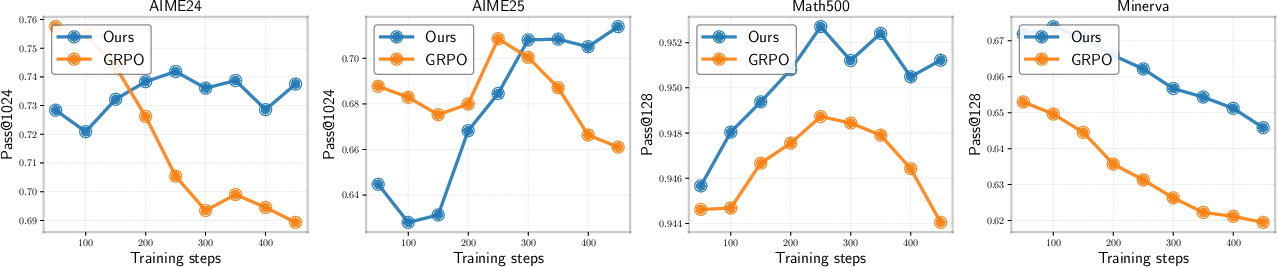
Figure 3: Pass@k evolution during RLVR training. GRPO objective leads to declining Pass@k, while SELF maintains or improves coverage.
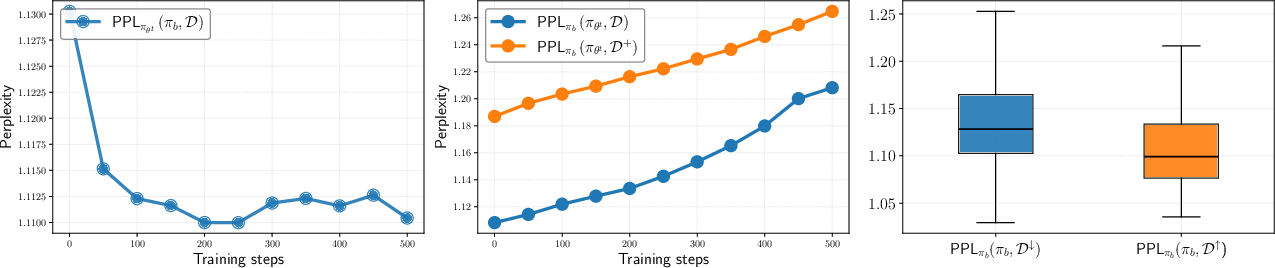
Figure 4: Perplexity analysis shows RLVR increasingly generates responses with high base model likelihood, while initial diverse solutions become less likely.
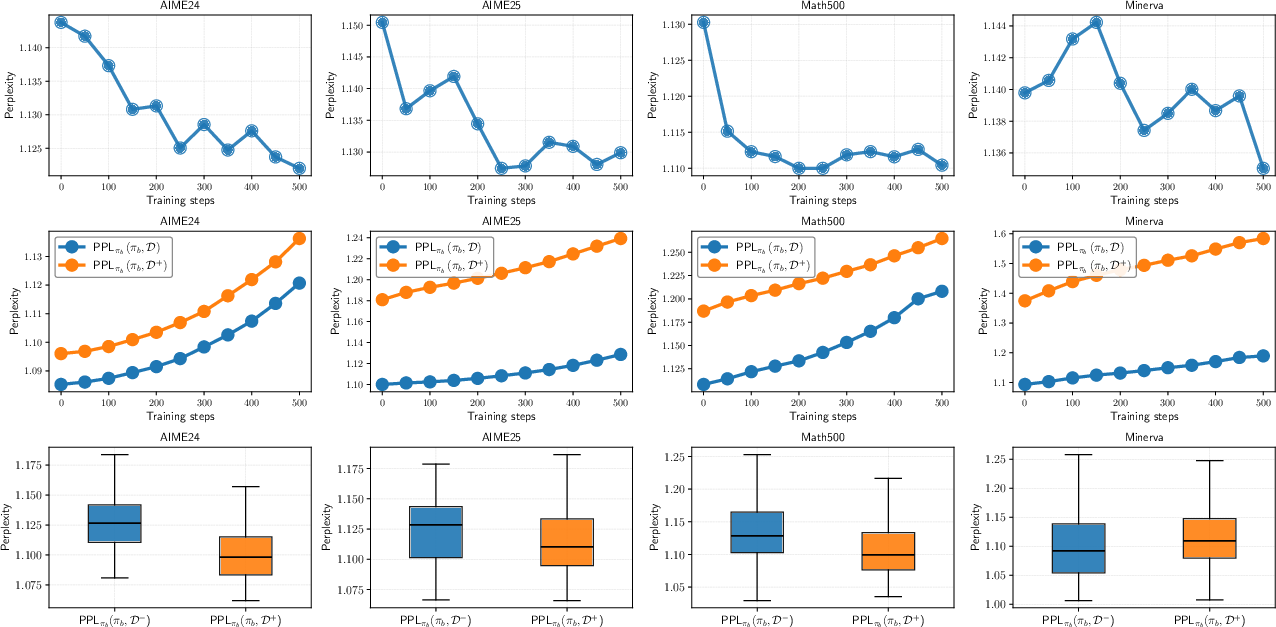
Figure 5: RLVR collapses to high-likelihood regions, improving problems already easy for the base model and degrading others.
On-Policy RL and the Collapse of Reasoning Diversity
The theoretical analysis, supported by toy bandit experiments, shows that on-policy RL objectives (e.g., REINFORCE) inherently favor high-likelihood actions, leading to mode collapse. In the LLM context, this means the model increasingly concentrates on a narrow set of reasoning strategies, often those already favored by the base model.

Figure 6: On-policy learning dynamics: correct responses in low-likelihood regions receive minimal updates, while high-likelihood responses are reinforced.
This effect is further illustrated by the collapse of code-based reasoning in the Minerva benchmark: RLVR training causes the model to abandon code reasoning in favor of natural language reasoning, even when the former is initially more effective.
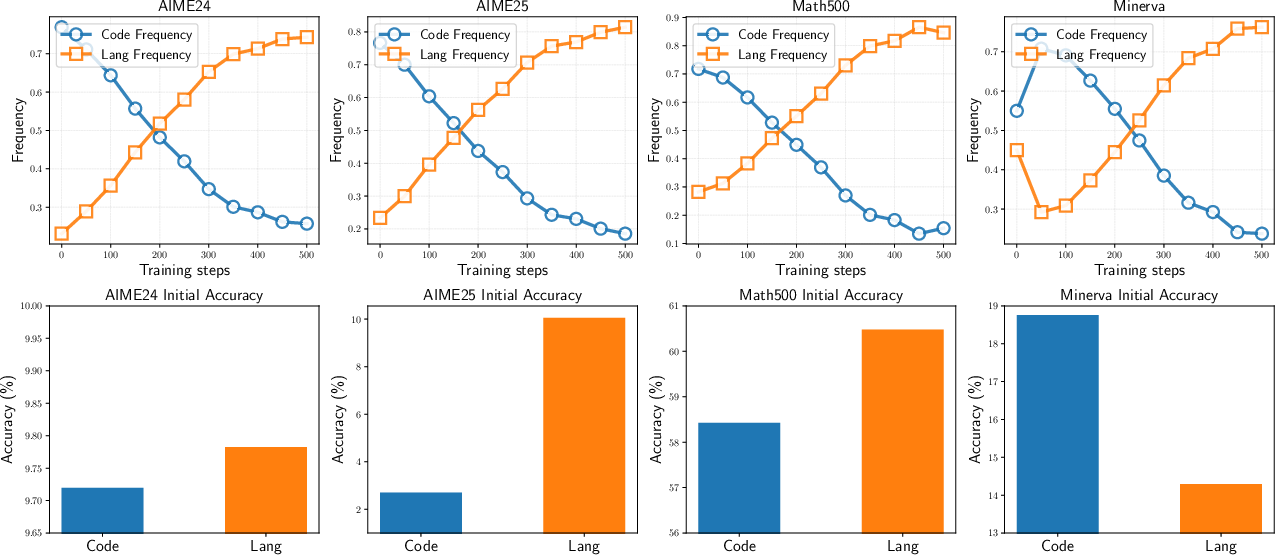
Figure 7: RLVR induces a shift from code to language reasoning, reducing diversity and degrading performance on benchmarks where code reasoning is advantageous.
Limitations of Standard Regularization
The authors show that standard regularization techniques, such as PPO-style clipping and KL penalties, are ineffective at preventing coverage shrinkage. Clipping only constrains updates on the training batch, not on the broader distribution, and reverse KL regularization is inherently mode-seeking, further exacerbating collapse.
The SELF Algorithm: Selective Learning for Coverage Preservation
To address these issues, the authors propose SELF (Selective Examples with Low-likelihood and Forward-KL), a data curation and regularization strategy. SELF filters out problems that are already highly solvable by the base model (as measured by greedy decoding), focusing RLVR updates on low-likelihood problems. Additionally, it replaces reverse KL with forward KL (SFT loss) to penalize forgetting of previously learned behaviors.

Figure 8: SELF focuses on low-success-rate problems, maintains higher diversity, and mitigates negative interference compared to GRPO.
Empirical results show that SELF achieves comparable or better Pass@1 and consistently superior Pass@k for large k across all benchmarks and model sizes. Notably, SELF's computational overhead is negligible relative to standard RLVR.
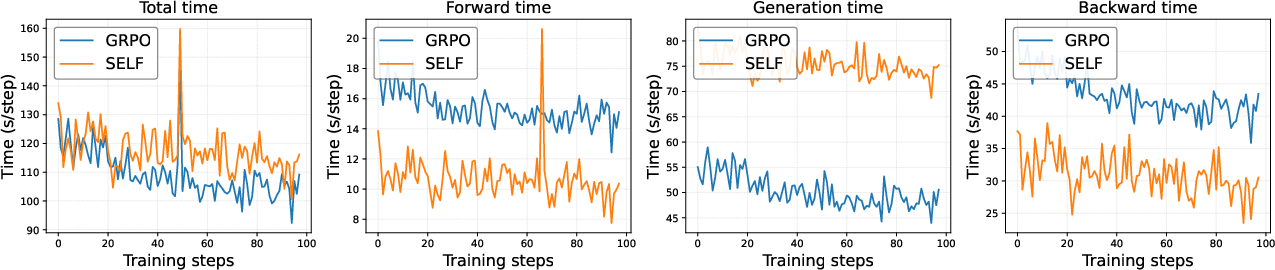
Figure 9: SELF incurs minimal additional computational cost compared to GRPO.
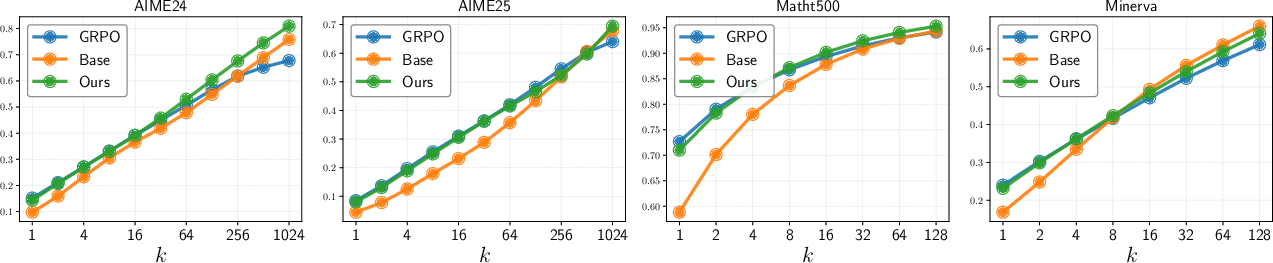
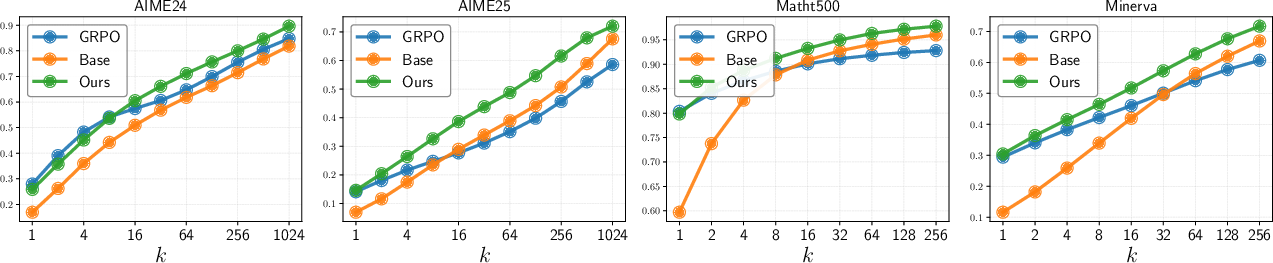
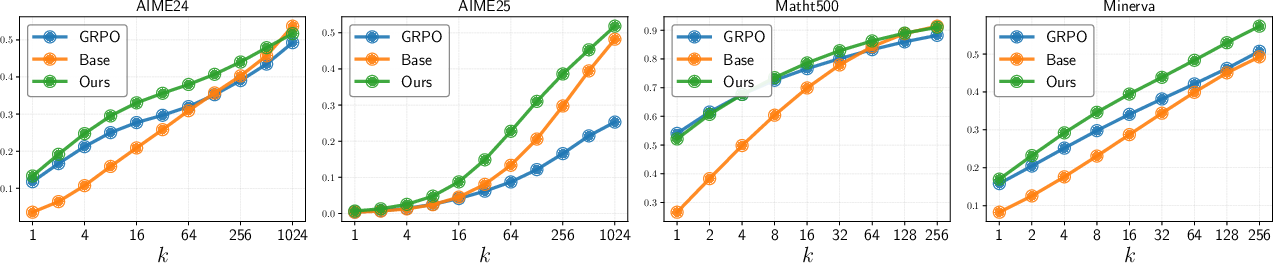
Figure 10: Pass@k curves: SELF outperforms both base and RLVR models at large k.
Implications and Future Directions
This work provides a comprehensive diagnosis of the limitations of RLVR for LLM reasoning, challenging the assumption that RLVR inherently expands reasoning boundaries. The identification of negative interference and winner-take-all dynamics has significant implications for the design of RL objectives and data curation strategies in LLM training.
Key implications:
- RLVR can reduce, not expand, the set of solvable problems unless care is taken to mitigate interference and mode collapse.
- On-policy RL objectives are fundamentally biased toward reinforcing existing model strengths, making them ill-suited for expanding coverage without explicit intervention.
- Data curation and regularization are critical: focusing updates on low-likelihood problems and penalizing forgetting are effective strategies for preserving and expanding reasoning diversity.
Future research directions include:
- Developing more sophisticated off-policy or hybrid RL objectives that can provide learning signal for low-likelihood solutions.
- Exploring alternative regularization schemes that directly penalize coverage shrinkage or encourage exploration in the solution space.
- Extending the analysis to other domains (e.g., programming, scientific reasoning) and larger model scales.
Conclusion
This paper rigorously demonstrates that RLVR, as commonly applied, can paradoxically constrain LLM reasoning by reinforcing high-likelihood solutions and suppressing diversity, leading to coverage shrinkage. The proposed SELF algorithm provides a practical and effective remedy, but the findings highlight the need for fundamentally new approaches to RL-based LLM training that explicitly address negative interference and winner-take-all dynamics.

