- The paper demonstrates that RLVR optimizes language model reasoning by channeling focus to historically successful patterns rather than generating new ones.
- The empirical analysis reveals that integrating supervised fine-tuning with RLVR significantly boosts pattern selection efficiency, particularly in weaker models.
- The study’s theoretical and experimental frameworks validate RLVR's scalability, confirming its efficacy in aligning reasoning strategies across various model architectures.
On the Mechanism of Reasoning Pattern Selection in Reinforcement Learning for LLMs
Introduction
The paper "On the Mechanism of Reasoning Pattern Selection in Reinforcement Learning for LLMs" systematically examines the capability enhancement effected by Reinforcement Learning with Verifiable Rewards (RLVR) in LLMs to optimize reasoning patterns. Despite RL's known empirical success, the underlying improvements in reasoning abilities remain weakly understood. This study breaks down the RLVR's contribution by investigating the techniques' role in refining the use of pre-existing reasoning configurations to achieve higher success rates.
Empirical Analysis
Comprehensive experiments across a spectrum of reasoning tasks establish that RLVR nudges models to favor reasoning patterns exhibiting higher historical success rates. Tasks range from basic arithmetic to complex mathematical problems sampled from the MATH dataset. Upon comparing models pre and post RLVR enhancement, it's observed that the intrinsic quality of particular reasoning configurations remains constant—an insight suggesting RLVR chiefly excels in optimizing pattern selection rather than creating new techniques.
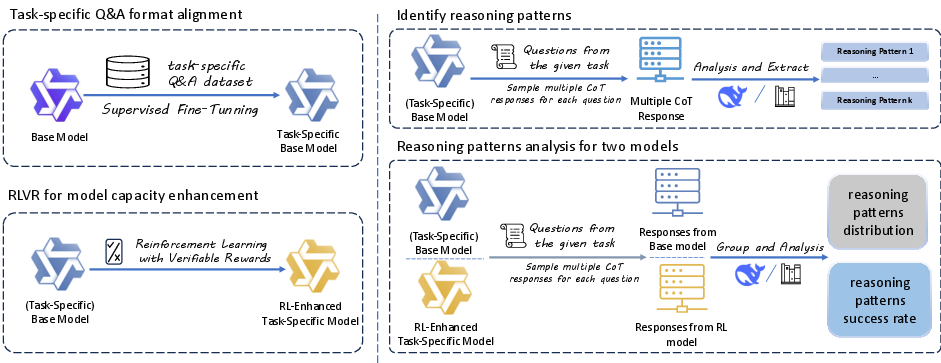
Figure 1: Illustration of the evaluation pipeline for conducting RLVR.
Post-application of RLVR, models manifest a discernible shift towards more effective reasoning patterns without altering the fundamental success rate of these patterns, highlighting the optimization in selection. In essence, RLVR promotes an intelligent distribution of reasoning techniques, channeling usage towards those configurations yielding superior outcomes.
Theoretical Framework
The theoretical analysis introduces a reasoning model conceptualized as a two-stage pipeline: choosing a reasoning pattern and generating a corresponding output. This framework underpins the correctness of RLVR's ability to converge models toward optimal patterns with high success probabilities by considering initial reasoning capabilities. Specifically, models with robust starting points demonstrate rapid convergence, whereas those with weaker credentials face prolonged optimization challenges, delineating RLVR's efficacy under varied initial model strengths.
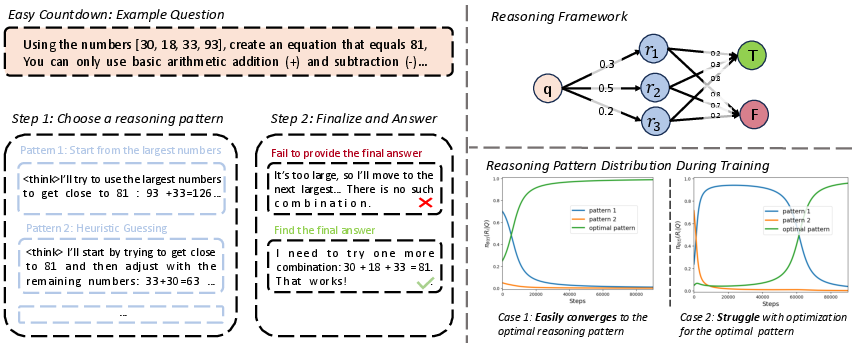
Figure 2: Overview of our theoretical framework and analysis results.
Case Studies
Detailed simulations validate the theorizations, showcasing scenarios where RLVR expeditiously guides strong base models to favorable reasoning configurations. Conversely, weaker models, when supplemented with a high-quality Supervised Fine-Tuning (SFT) dataset pre-RLVR, reveal marked improvement in subsequent reasoning pattern selection. This establishes the superlative efficacy of an SFT-then-RLVR training regime—curating an efficient pretext for optimizing reasoning capabilities.
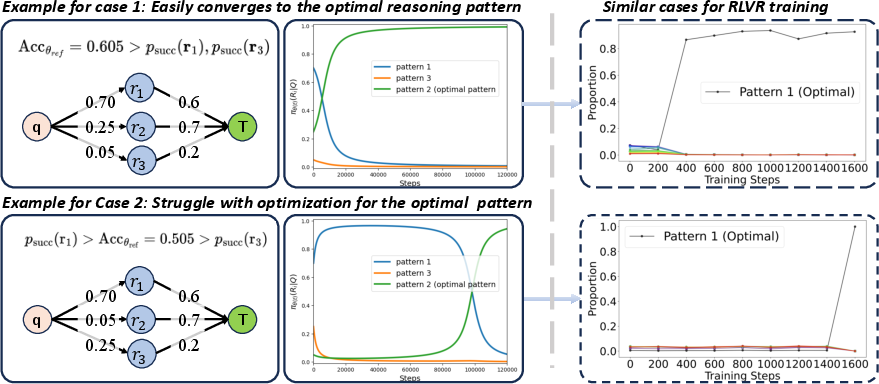
Figure 3: Case studies illustrating the nuanced dynamics of RLVR training.
Additional Experiments and Scale Analysis
Further empirical validations highlight similar pattern favoring phenomena in larger models like Qwen-2.5-32B. This consistent convergence of reasoning patterns aligns with theoretical predictions and emboldens the hypothesis surrounding RLVR's utility in large-scale applications, reaffirming the model consistency across different architectures and scales.
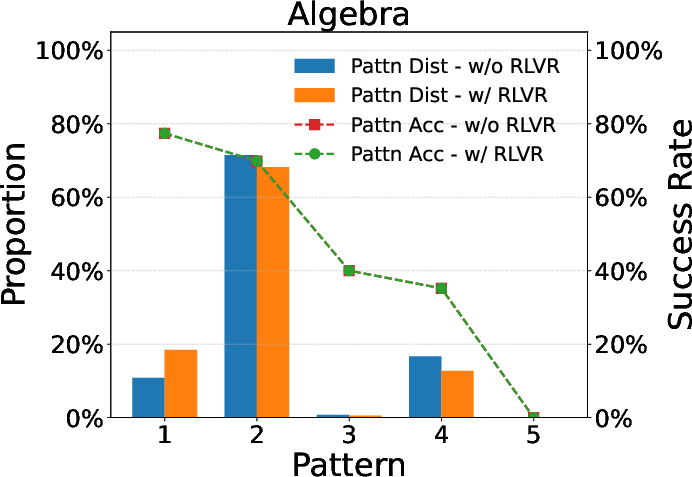
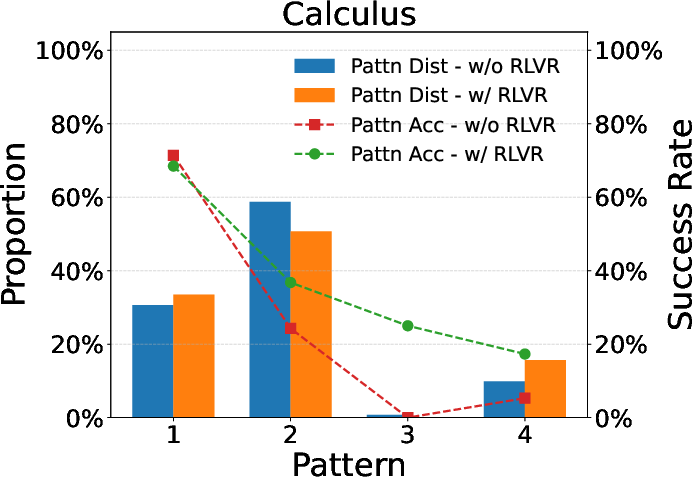
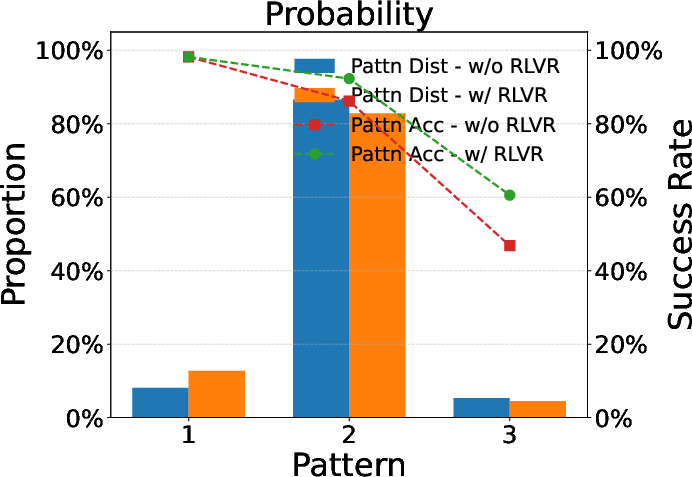
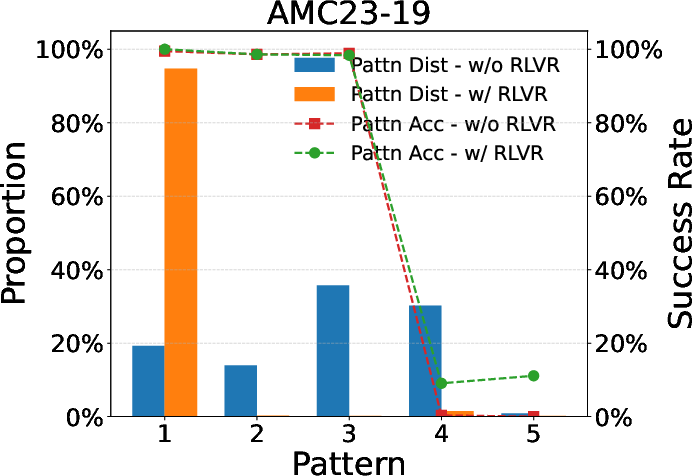
Figure 4: Evaluation results for larger models, underscoring RLVR's scalability.
Conclusions
This paper identifies key mechanisms underpinning RLVR's enhancement of reasoning capabilities in LLMs: primarily, the optimal selection of inherently successful reasoning patterns. The employment of both empirical and theoretical analyses clears misconceptions about RLVR's role in reasoning improvement and emphasizes efficient pattern utilization over the emergence of entirely new reasoning technology. This insight not only informs future RL-based enhancements in LLMs but also assists in structuring fine-tuning strategies, advocating for upstream supervised interventions for maximizing downstream RL benefits. While the framework comprehensively captures reasoning dynamics in simplified setups, extending this analysis to more complex patterns remains a promising avenue for future research.

