- The paper introduces TempoControl, an inference-time optimization method that steers cross-attention maps for explicit temporal control in video generation.
- It achieves substantial improvements, raising single-object temporal accuracy from 63.94% to 81.00% and enhancing multi-object and motion control performance.
- The method is model-agnostic and extends to audio-visual alignment, although it increases inference time and may trade off motion diversity.
TempoControl: Temporal Attention Guidance for Text-to-Video Models
Introduction and Motivation
Text-to-video diffusion models have achieved substantial progress in generating high-fidelity, temporally coherent videos from natural language prompts. However, these models lack mechanisms for fine-grained temporal control, i.e., the ability to specify when particular visual elements or actions should appear within a generated sequence. This limitation is particularly acute in scenarios requiring precise temporal alignment, such as synchronizing visual events with audio cues or orchestrating the appearance of multiple objects at specific times.
TempoControl addresses this gap by introducing an inference-time optimization method that enables explicit temporal control over the appearance and motion of visual concepts in text-to-video diffusion models. The approach leverages the cross-attention mechanism inherent in modern diffusion architectures, steering the temporal activation of prompt tokens without requiring model retraining or additional supervision.
Methodology
TempoControl operates by manipulating the latent variables during the denoising process of a pre-trained text-to-video diffusion model (specifically, Wan 2.1). The core idea is to steer the temporal profile of cross-attention maps associated with specific prompt tokens, aligning them with user-defined temporal masks that encode the desired timing of concept appearance.
Cross-Attention Extraction and Aggregation
At each denoising step t, the model computes cross-attention tensors At∈RL×h×nv×np, where L is the number of layers, h the number of heads, nv the number of video tokens, and np the number of prompt tokens. These are averaged across heads and layers to yield Aˉt∈Rnv×np. For a given word i, the temporal attention vector ait∈RT′ is constructed by spatially aggregating the attention over all video tokens at each frame.
Temporal Control Objective
The optimization objective at each denoising step is a weighted sum of four loss terms:
- Temporal Correlation Loss: Encourages the normalized temporal attention vector ait to be highly correlated (via Pearson correlation) with the target temporal mask mi.
- Attention Energy Loss: Promotes high attention values where the mask is active and suppresses attention elsewhere, ensuring sufficient activation for visibility.
- Entropy Regularization: Penalizes high spatial entropy in the attention maps, enforcing spatial focus and preventing attention diffusion.
- Spatial Consistency Penalty: Penalizes deviations between the initial and optimized spatial attention maps to maintain scene coherence.
The latent code zt is updated via gradient descent on this objective for a fixed number of steps or until the correlation exceeds a threshold, after which the standard denoising process resumes.
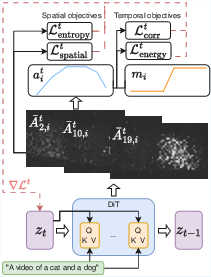
Figure 2: Illustration of TempoControl. During a single denoising step t, spatial attention maps are aggregated to a temporal attention signal and aligned with the target mask via loss terms; gradients update the latent code.
Inference-Time Optimization
TempoControl is applied only during the initial k denoising steps, with l gradient updates per step. The optimization is performed on the latent variables, not the model weights, ensuring compatibility with any pre-trained diffusion backbone and avoiding the need for additional data or retraining.
Experimental Evaluation
Quantitative Results
TempoControl is evaluated on VBench and custom benchmarks for single-object, two-object, and motion-centric temporal control. The method is compared against Wan 2.1 with explicit temporal cues in the prompt.
Qualitative Analysis
Qualitative results demonstrate that TempoControl enables precise placement of objects and actions at specified times, which is not achievable by the baseline even with explicit temporal phrasing in the prompt. For example, in prompts requiring an object to appear only in the final second, the baseline often fails to suppress early appearance, while TempoControl achieves the desired timing.
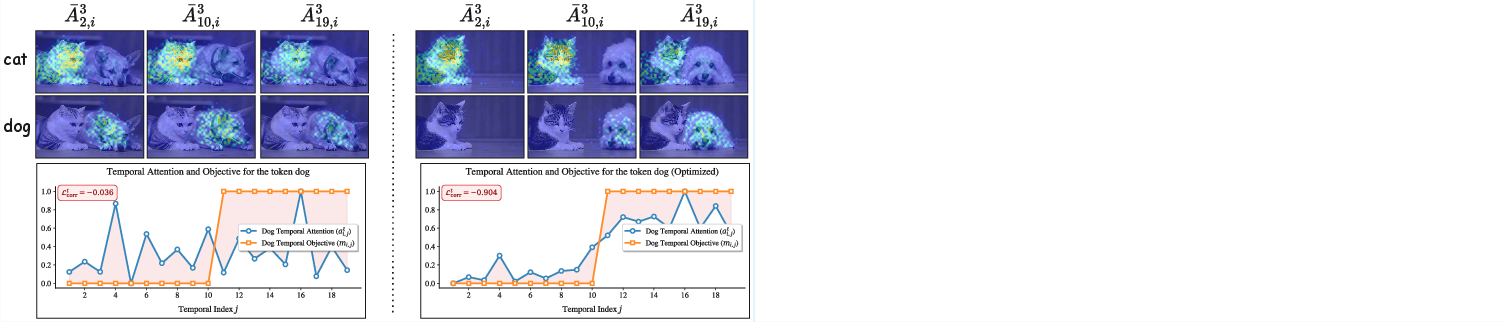
Figure 1: Video generated for the prompt "A cat and a dog." Before (left) and after optimization (right). Top: Spatial attention maps for "cat" and "dog" at a denoising step, overlaid on frames. Bottom: Temporal attention vs. target mask, with Pearson correlation loss.
Audio-Visual Alignment
TempoControl is extended to zero-shot audio-to-video alignment by using a preprocessed audio envelope as the temporal mask. The method successfully synchronizes visual events with audio peaks, demonstrating the generality of the approach for multimodal temporal control.

Figure 3: Examples of video alignment to an audio signal using TempoControl.
Human Evaluation
A user study with 50 annotators confirms that videos generated with TempoControl are preferred in terms of temporal accuracy (61.51% vs. 16.94%) and visual quality, corroborating the quantitative findings.
Figure 5: Evaluation interface showing the prompt and two videos (A and B) for comparison.
Figure 6: Second example of the human evaluation interface.
Ablation Studies
Ablation experiments reveal that the entropy regularization term is critical for preventing attention diffusion and object blending, especially in multi-object scenes. Removing the energy term modestly reduces temporal accuracy, while omitting entropy regularization leads to substantial degradation in both temporal and visual metrics.

Figure 7: Ablation study. Left: without entropy regularization, the motorcycle disappears. Right: the bear is incorrectly replaced by a zebra.
Implementation Considerations
- Computational Overhead: TempoControl increases inference time (∼460s per video vs. ∼170s for vanilla generation on an NVIDIA H200 GPU) due to the optimization steps. However, it does not require retraining or additional data.
- Hyperparameters: The method is robust to hyperparameter choices, with minor adjustments needed for different scenarios (e.g., higher learning rate for two-object scenes).
- Prompt Engineering: Explicit temporal phrasing in prompts does not improve baseline performance and may degrade quality. TempoControl achieves higher accuracy with simpler prompts.
- Limitations: Temporal conditioning can induce perceptual changes in background or unspecified features, and current objectives do not fully guarantee global scene consistency.
Broader Implications and Future Directions
TempoControl demonstrates that inference-time manipulation of cross-attention maps provides a practical and effective mechanism for temporal control in text-to-video diffusion models. This approach is model-agnostic, data-free, and extensible to multimodal alignment tasks such as audio-to-video synchronization. The method exposes new axes of controllability in generative video models, enabling applications in animation, content creation, and human-computer interaction where precise timing is essential.
Future work may focus on improving global consistency, reducing computational overhead, and extending the approach to more complex temporal structures and multimodal scenarios. Integrating temporal control objectives into model training, or developing more efficient optimization strategies, could further enhance the usability and scalability of temporally controlled video generation.
Conclusion
TempoControl introduces a principled, inference-time method for temporally aligning visual concepts in text-to-video diffusion models by steering cross-attention maps. The approach achieves substantial improvements in temporal accuracy for object and action appearance, maintains high visual quality, and generalizes to audio-visual alignment, all without retraining or additional supervision. This work establishes a foundation for fine-grained temporal control in generative video models and opens new directions for research in temporally grounded content generation.


