- The paper introduces ControlVideo, a training-free approach that leverages diffusion-based text-to-image models to generate consistent videos.
- It employs fully cross-frame interaction, interleaved-frame smoothing, and hierarchical sampling to enhance temporal consistency and reduce flickering.
- Results demonstrate superior frame and prompt consistency with efficient GPU synthesis, enabling rapid prototyping in video content creation.
ControlVideo: Training-Free Controllable Text-to-Video Generation
Abstract and Introduction
"ControlVideo: Training-free Controllable Text-to-Video Generation" (2305.13077) presents a novel approach to the generation of videos from text prompts, specifically leveraging the capabilities of diffusion-based text-to-image models without the need for extensive training. This method, termed ControlVideo, introduces innovative modules aimed at improving the quality and temporal consistency of generated videos, effectively expanding upon the successful application of diffusion models in image synthesis to video contexts.
While traditional methods for video generation demand considerable computational resources and training datasets to model temporal dynamics, ControlVideo circumvents these requirements by adapting the architecture and weights of ControlNet. The process involves inflating the network along the temporal axis and incorporating fully cross-frame interaction within self-attention modules, thus allowing the video synthesis process to inherit the proficiency of pre-trained text-to-image models. This adaptation is key to maintaining coherence in appearance across frames, a notable challenge in current approaches.
Methodology
The proposed framework integrates three critical components: fully cross-frame interaction, interleaved-frame smoothing, and hierarchical sampling. These innovations address prevalent issues of appearance inconsistency and structural flickers in generated videos, especially when synthesizing long sequences.
- Fully Cross-Frame Interaction: ControlVideo enhances temporal consistency by concatenating video frames into a "larger image", facilitating shared content across video frames through self-attention mechanisms. This technique refines previous sparse cross-frame methods that introduced discrepancies impacting video quality and consistency (Figure 1).
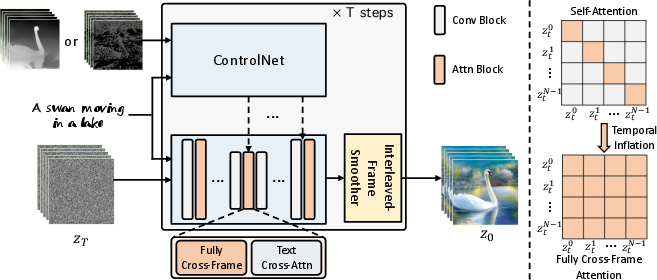
Figure 1: Overview of ControlVideo. For consistency in appearance, ControlVideo adapts ControlNet to the video counterpart by adding fully cross-frame interaction into self-attention modules.
- Interleaved-Frame Smoother: To mitigate flicker effects between frames, the framework employs an interpolation process on alternating frames, yielding smoother transitions through sequential timesteps (Figure 2).

Figure 2: Qualitative comparisons conditioned on depth maps and canny edges. Our ControlVideo produces videos with better (a) appearance consistency and (b) video quality than others.
- Hierarchical Sampler: This component focuses on efficient long-video synthesis by splitting video generation into sequential short clips, ensuring holistic coherency and reducing memory usage.
Results and Comparisons
ControlVideo demonstrates superior performance, both qualitatively and quantitatively, in video generation tasks compared to existing methods such as Tune-A-Video and Text2Video-Zero. Its efficient design allows for the production of both short and long videos within minutes on GPU hardware, showcasing its practical applicability and scalability.
Through comprehensive experiments across motion-prompt pairs, ControlVideo consistently achieves higher frame and prompt consistency scores, advancing the state-of-the-art in text-to-video generation.
Discussion and Impact
ControlVideo represents a significant step forward in efficient text-to-video synthesis, democratizing access to high-quality video generation without extensive infrastructural demands. This model has the potential to revolutionize creative industries and facilitate rapid prototyping in video content creation. Furthermore, its approach encourages future exploration into adapting temporal sequences to diverse motion patterns using text inputs.
Despite its advantages, the paper acknowledges inherent limitations in generating diverse video outputs beyond given motion sequences, prompting further research into adaptive motion transformation methods.
Conclusion
The paper introduces ControlVideo as a viable solution for training-free controllable text-to-video generation, leveraging the strengths of diffusion models to produce consistent, high-quality videos efficiently. It sets the foundation for future developments in innovative video synthesis methods, enhancing access and capabilities across both research and practical applications.
In summary, ControlVideo embraces the challenge of video generation through strategic architectural adaptations and module integrations, achieving state-of-the-art results in video quality and consistency. The model's efficiency and performance reaffirm its potential impact in advancing the field of generative models for video synthesis.
