- The paper presents VideoComposer which achieves controllable video synthesis by integrating textual, spatial, and temporal conditions through a novel STC-encoder.
- It leverages Video Latent Diffusion Models and motion vectors to enhance inter-frame consistency and reduce the computational burden of video processing.
- Experimental results validate superior motion control in tasks like image-to-video generation and video inpainting, highlighting its potential for automated content creation.
Compositional Video Synthesis with Motion Controllability
Introduction to VideoComposer
The paper introduces VideoComposer, a sophisticated system aimed at achieving controllable video synthesis through the integration of textual, spatial, and temporal conditions. Addressing the complexities inherent in video creation, this work departs from traditional methods by employing a compositional framework that prioritizes motion controllability. VideoComposer leverages motion vectors derived from compressed videos as explicit temporal control signals, facilitating enhanced inter-frame consistency. The innovation lies in the use of a Spatio-Temporal Condition encoder (STC-encoder) that harmonizes spatial and temporal cues, thereby improving the precision and fidelity of synthesized videos.
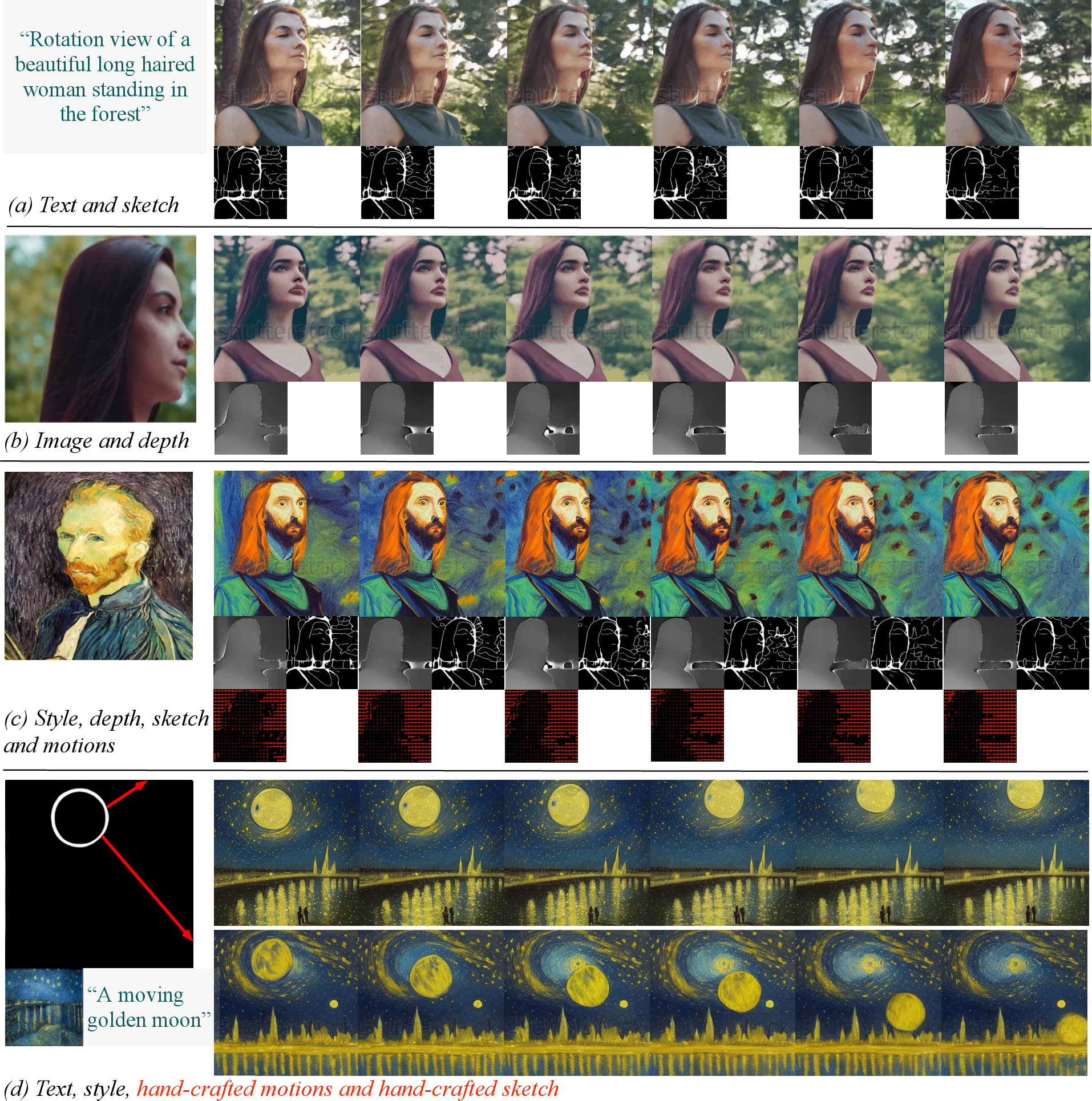
Figure 1: Compositional video synthesis using VideoComposer.
Architectural Overview
Video Latent Diffusion Models
The architecture is grounded in Video Latent Diffusion Models (VLDMs), which operate in the latent space to efficiently process video data. This approach circumvents the computational burden of pixel-space processing while ensuring high fidelity and preserving the visual manifold. The model incorporates perceptual video compression through a pre-trained encoder and decoder, projecting videos onto a latent representation optimized for rapid synthesis.
Spatio-Temporal Condition Encoder
Central to VideoComposer's robustness is the STC-encoder, designed to handle complex spatio-temporal dependencies. The encoder integrates sequential inputs using temporal attention mechanisms, facilitating enhanced inter-frame consistency. By embedding control signals from multiple conditions—such as text descriptions, sketches, and motion vectors—the model achieves versatile compositionality.

Figure 2: Image-to-video generation with spatial and temporal conditions.
Experimental Results
Compositional Video Generation
VideoComposer demonstrates significant versatility across several compositional tasks. In image-to-video generation, static images are animated while adhering to specified textual conditions. The model excels in video inpainting by restoring corrupted regions according to prescribed textual and temporal guidance.

Figure 3: Demonstration of video inpainting using masked conditions.
Motion Control and Evaluation Metrics
The efficacy of motion control is quantitatively affirmed through metrics such as motion control error, highlighting the precision achieved by incorporating motion vectors. Comparative assessments illustrate the superior performance of VideoComposer over existing models, attributed to the STC-encoder's temporal modeling capacity.

Figure 4: Video-to-video translation showcasing effective motion control.
Implications and Future Directions
The capabilities of VideoComposer extend beyond mere synthesis, offering profound implications for automated content creation. Its potential application in fields such as film and media production underscores the transformative impact of controllable synthesis systems. Future developments may explore the integration of real-time feedback mechanisms to further refine fidelity and adaptability.
Conclusion
VideoComposer heralds a new era in video synthesis by emphasizing compositionality and motion controllability. Through its innovative use of motion vectors and STC-encoding, the system sets a benchmark for personalized and consistent video creation. The implications of this research are wide-ranging, promising advancements in both theoretical understanding and practical deployment in visual content creation domains.