- The paper introduces a comprehensive benchmark, EmergentTTS-Eval, that evaluates TTS models on six challenging linguistic scenarios using LALMs as automated judges.
- The methodology employs iterative LLM refinement to expand hand-crafted samples and calculates win-rate metrics to assess system performance.
- Experimental results reveal significant variability among TTS systems, emphasizing the need for targeted optimizations in prosody, emotion, and multilingual synthesis.
EmergentTTS-Eval: Evaluating TTS Models on Complex Challenges
The paper "EmergentTTS-Eval: Evaluating TTS Models on Complex Prosodic, Expressiveness, and Linguistic Challenges Using Model-as-a-Judge" addresses the limitations of traditional Text-to-Speech (TTS) benchmarks which often fail to capture nuanced complexities in text synthesis. The authors introduce EmergentTTS-Eval, a comprehensive benchmark designed to evaluate TTS models across six challenging textual scenarios that are commonly encountered in real-world applications. This benchmark employs a model-as-a-judge approach using Large Audio LLMs (LALMs) to assess various dimensions of speech, providing a scalable alternative to traditional human evaluations.
Benchmark Design and Dataset Construction
EmergentTTS-Eval targets six critical dimensions of TTS performance: emotions, paralinguistics, foreign words, syntactic complexity, complex pronunciation, and questions. The benchmark is built on a diverse set of 1,645 test cases, generated through an iterative refinement process using LLMs to extend a small set of human-written seed prompts. This process allows for the creation of increasingly complex utterances, providing a robust framework for differentiating performance among TTS systems.
To construct the dataset, the authors began with a base of 140 hand-crafted samples from BASE-TTS, each representing specific linguistic phenomena. These samples were extended using LLMs to generate four additional categories, creating a multi-layered benchmark designed to stress-test various aspects of TTS systems comprehensively. For example, the foreign words category incorporates phrases from multiple languages, requiring systems to manage code-switching and native pronunciation.


Figure 1: Paralinguistic example, refined and made more complex for TTS with increased number of cues.
Model-as-a-Judge Approach
A key innovation of this benchmark is the integration of LALMs as automated judges. These models evaluate synthesized speech based on multiple dimensions such as emotion, prosody, pronunciation, and stress, areas that traditional metrics like Word Error Rate (WER) fail to assess. The authors demonstrate the effectiveness of LALMs in predicting human preferences, with high correlation achieved between machine-based evaluation results and human judgments.
The judger framework utilizes a win-rate metric to summarize system performance relative to a baseline. The win-rate reflects the percentage of instances where a candidate system outperforms the baseline, effectively revealing strengths and weaknesses in specific synthesis scenarios. This approach not only scales efficiently but also provides detailed, timestamp-based reasoning to diagnose synthesis errors.
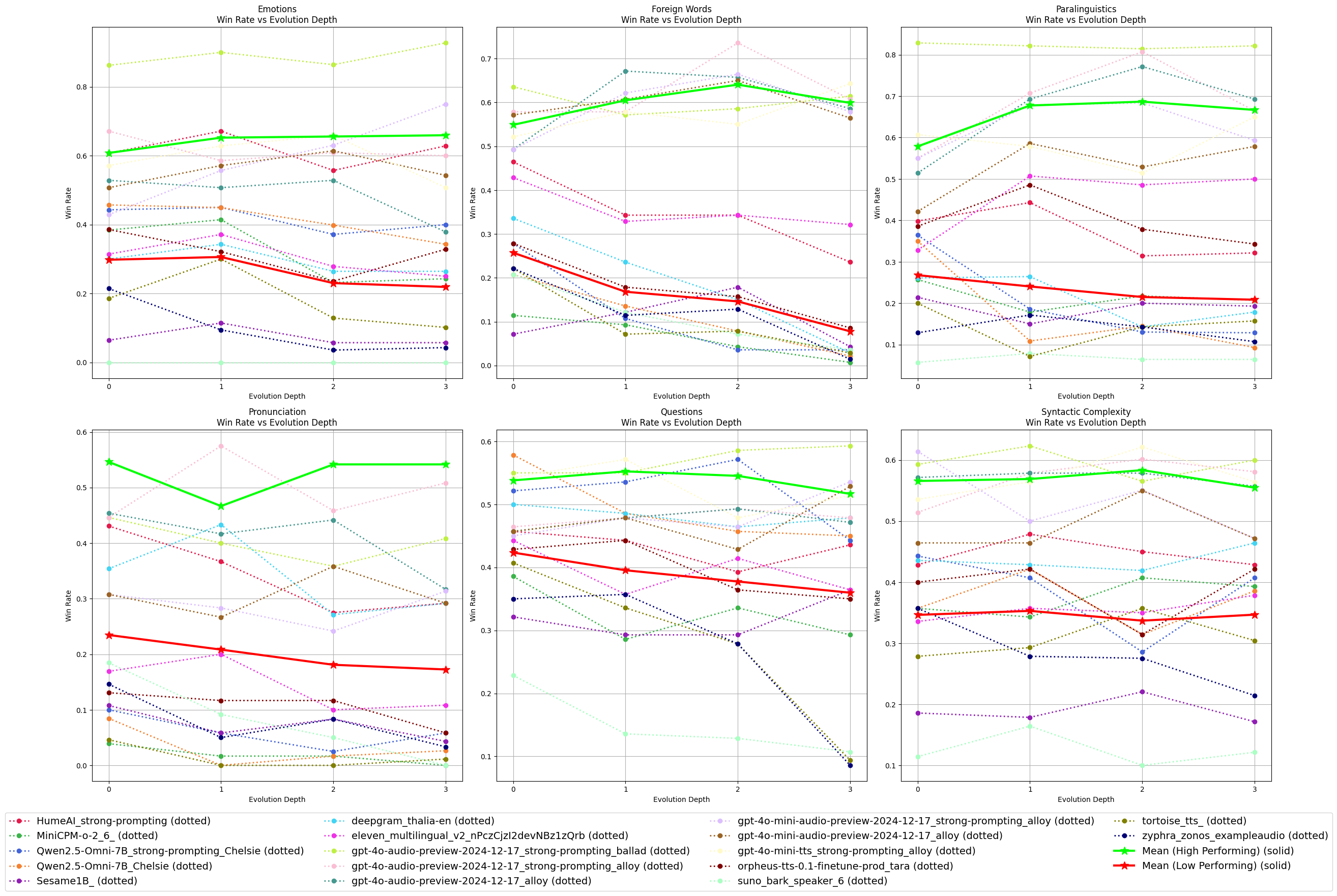
Figure 2: Win-rate chart for each category at different refinement depths. We also show the mean win-rate at each depth, computed collectively for high-performing models~(average win-rate>50\%) and low-performing models~(average win-rate<50\%).
Experimental Evaluation
The authors evaluated 11 different TTS systems, including state-of-the-art proprietary models and open-source alternatives, yielding detailed insights into system capabilities across the benchmark's dimensions. Results show significant variability in performance, with proprietary models generally outperforming open-source solutions, particularly in complex scenarios like emotions and foreign words.
Performance trends reveal that while the complexity of scenarios increases, both high-performing and low-performing models exhibit mixed results. Strong performance in one category does not uniformly extrapolate to success across all categories, underscoring the importance of targeted optimizations for specific linguistic challenges.
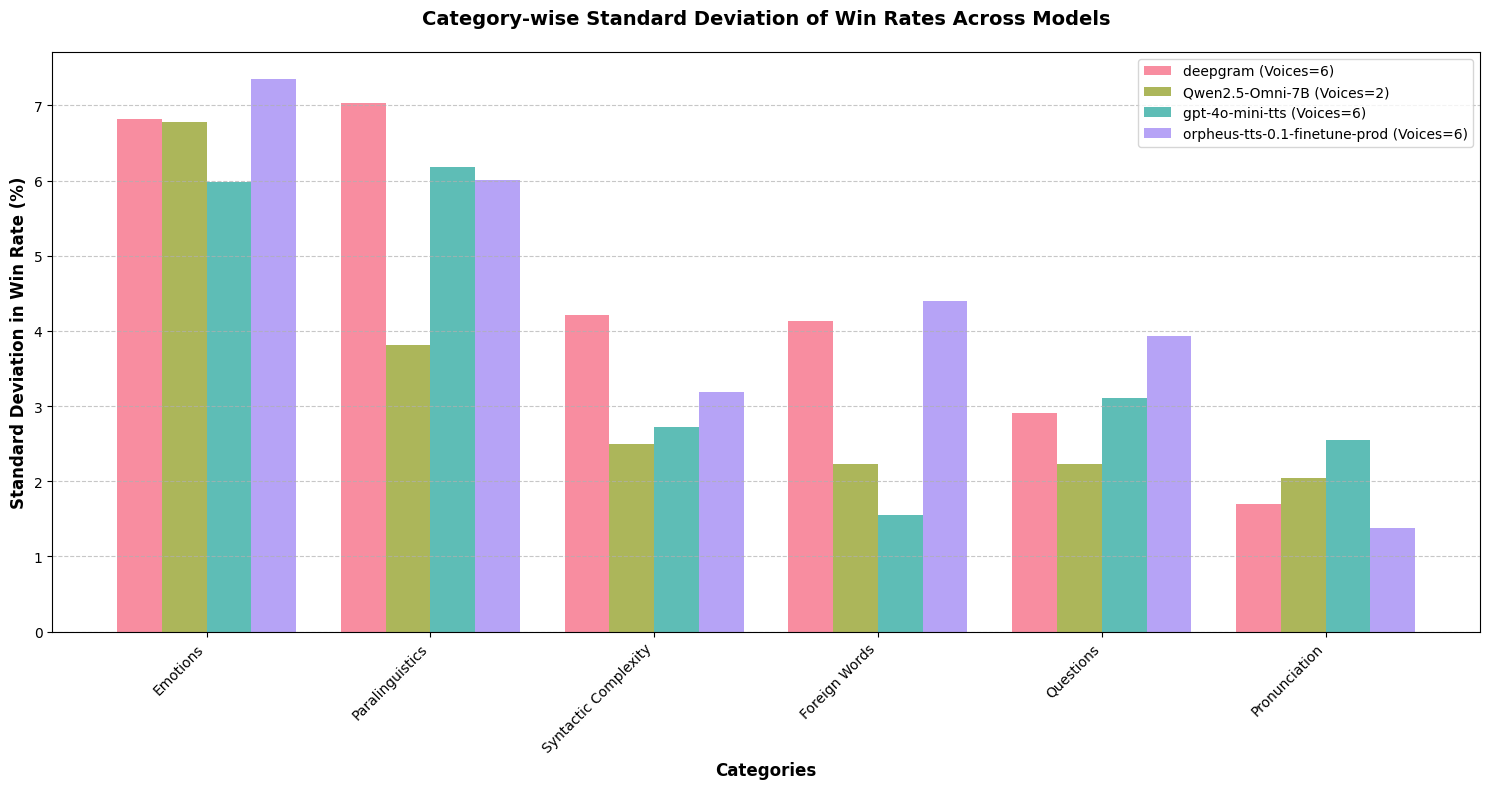
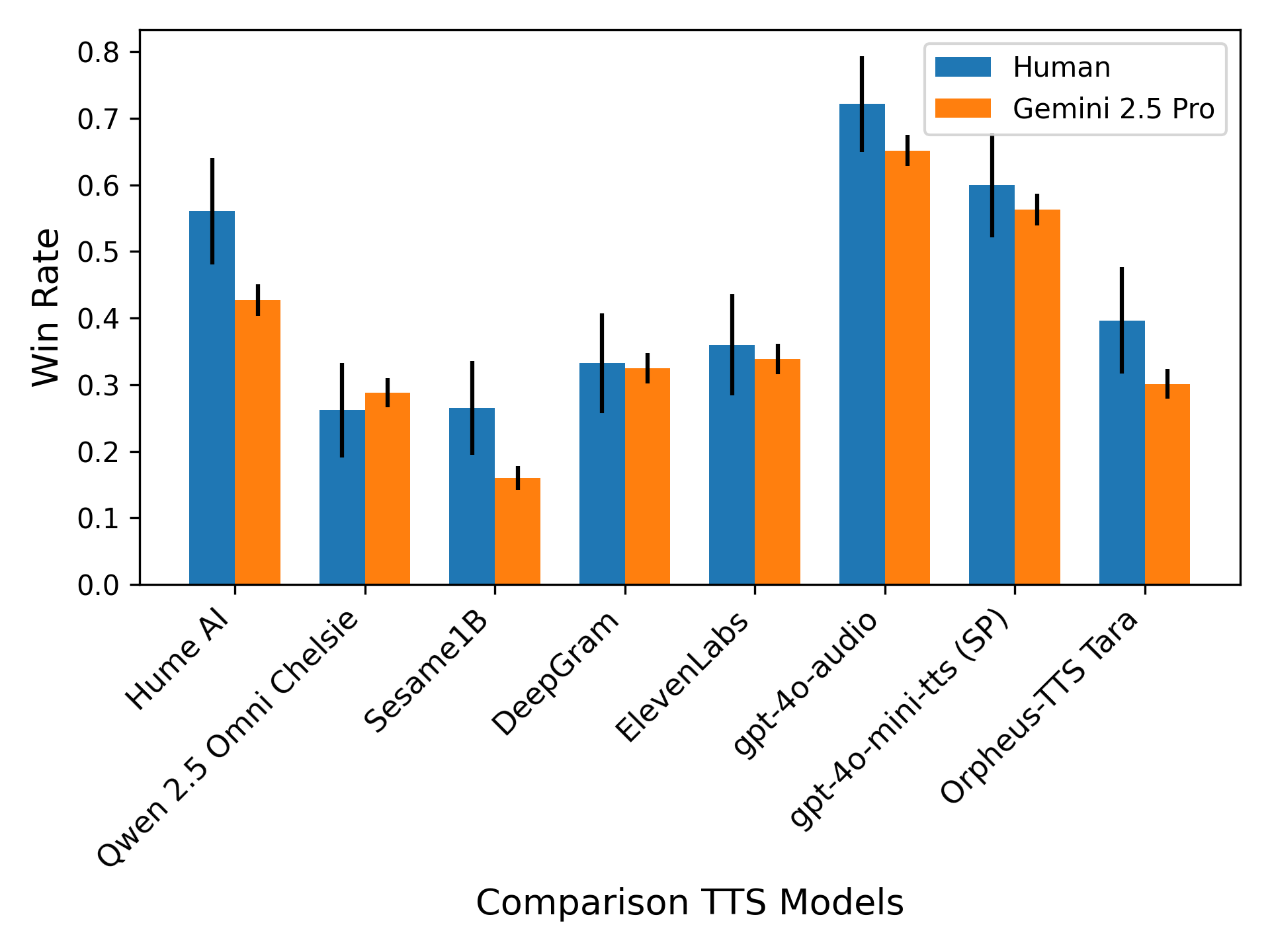
Figure 3: Variance of win-rate by voice (gemini-2.0-flash as judge)
Implications and Future Work
EmergentTTS-Eval provides a comprehensive methodology for evaluating TTS systems, addressing limitations in current benchmarks by introducing scalable and reproducible assessment techniques. The research highlights important areas of improvement for TTS technology, such as enhancing emotional expressiveness and managing multilingual content.
Future developments may include expanding the dataset to cover additional linguistic phenomena or refining the model-as-a-judge approach for even greater interpretability and precision. By continuing to advance evaluation frameworks, researchers can drive progress toward more adaptive and human-like TTS systems that excel across increasingly complex real-world applications.
In conclusion, EmergentTTS-Eval represents a significant step forward in TTS evaluation, offering robust tools to measure and improve system performance on nuanced, complex text synthesis challenges.