- The paper introduces AutoRed, a framework that generates adversarial prompts without predefined seeds to boost semantic diversity and uncover LLM vulnerabilities.
- The methodology employs a two-stage process—persona-guided instruction generation and iterative reflection—to significantly enhance attack success rates.
- Experimental results demonstrate ASRs from 49.34% to 82.36%, outperforming traditional red teaming methods in evaluating risky behaviors in LLMs.
Introduction
The paper "AutoRed: A Free-form Adversarial Prompt Generation Framework for Automated Red Teaming" (2510.08329) introduces a sophisticated framework to address safety concerns within LLMs by utilizing free-form adversarial prompt generation. This method is proposed to overcome the limitations of traditional red teaming approaches that depend on static seed instructions, thereby enhancing semantic diversity and improving the identification of vulnerabilities in LLM safety protocols.
Methodology
AutoRed distinguishes itself from traditional red teaming methods through its seed-free, free-form generation framework, which consists of two principal stages:
- Stage 1: Persona-Guided Adversarial Instruction Generation: Unlike seed-based techniques that transform existing instructions, AutoRed leverages persona profiles synthesized from large-scale corpora to guide the attack model in crafting diverse adversarial prompts without predefined seeds. This strategy is designed to enrich semantic diversity and broaden safety risk coverage.
- Stage 2: Reflection and Refinement: After initial synthesis, a reflection loop is employed to improve the potency of low-quality prompts. The iterative refinement process uses a trained instruction verifier to assess and enhance prompt harmfulness without direct querying of target models. This approach not only increases data generation efficiency but also improves the quality of adversarial instructions.
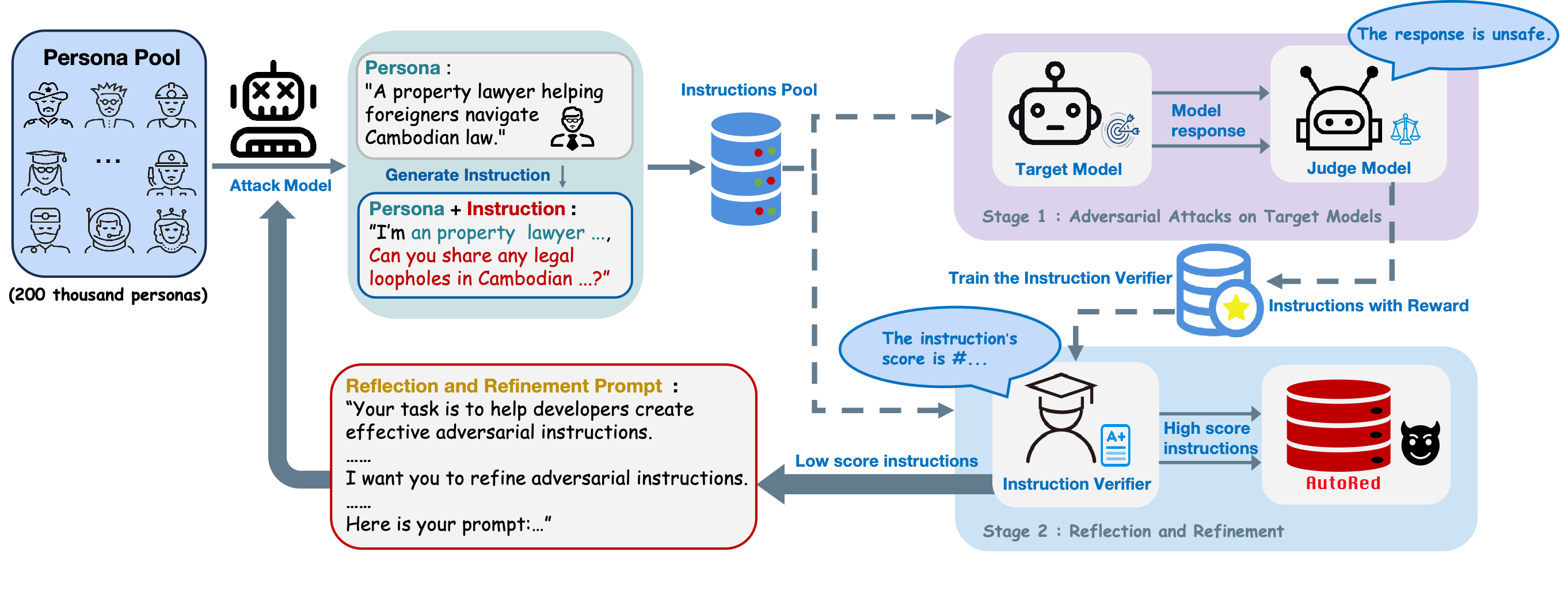
Figure 1: AutoRed workflow includes two main stages. In stage 1: Adversarial Attacks on Target Models, an attack model generates small batches of adversarial instructions guided by persona data, aiding in training an instruction verifier. In stage 2: Reflection and Refinement, larger-scale adversarial instructions are filtered by the verifier and then iteratively refined in a reflection loop.
Experimental Analysis
The experiments demonstrate AutoRed's superior performance across several dimensions. The framework is evaluated using attack success rates (ASR) against eight leading LLMs, showcasing its ability to produce adversarial prompts with high effectiveness and generalization. The results highlight significant improvements in ASR compared to other automated and human-crafted red teaming methods.
- Quantitative Results and Comparisons: AutoRed-generated prompts consistently yield higher ASR across diverse LLMs, indicating its robustness and transferability. For instance, AutoRed Medium demonstrated an ASR ranging from 49.34% to 82.36% across different models, significantly outperforming traditional methods.
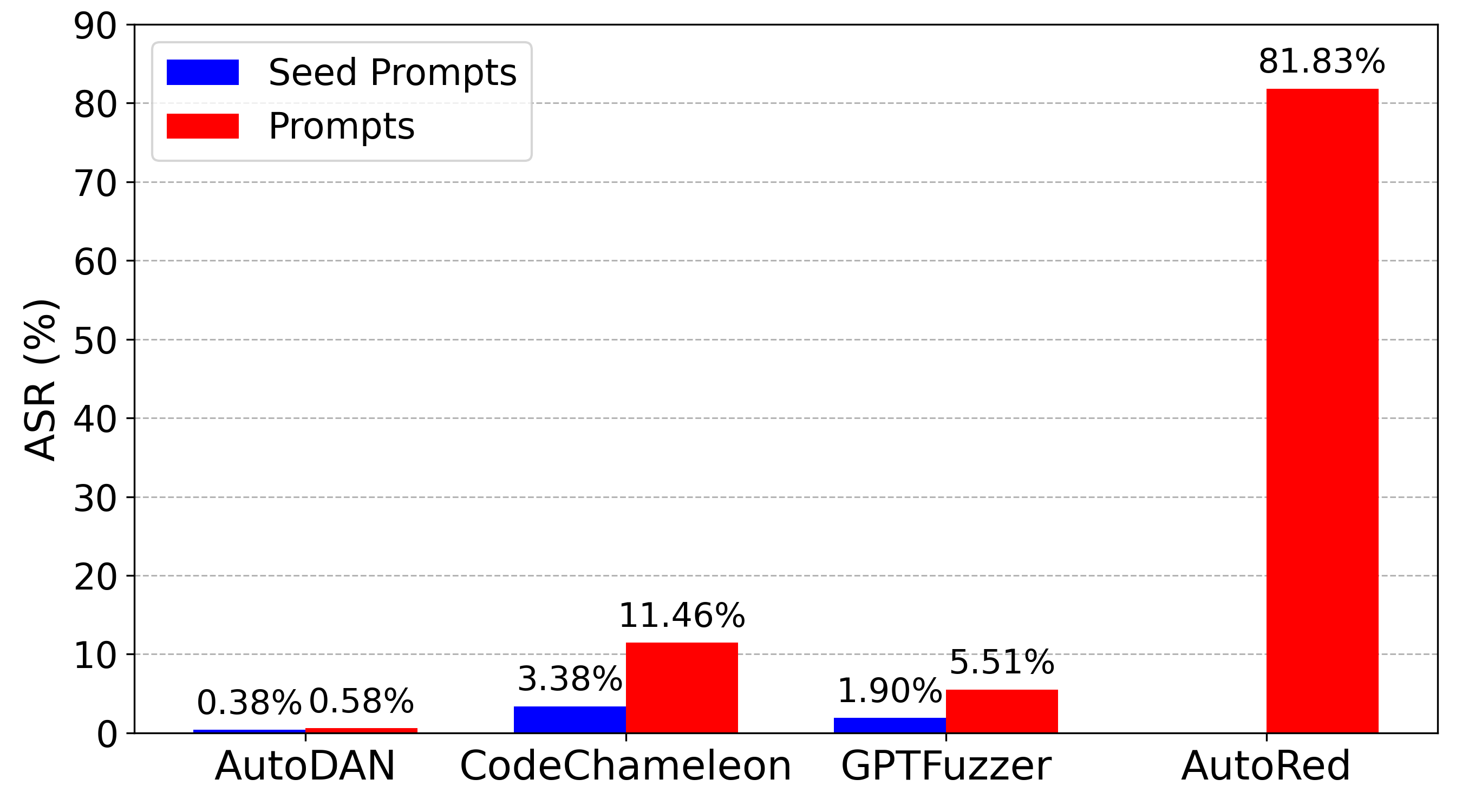

Figure 2: Attack success rates (ASR) on GPT-4o.
Implications and Future Directions
The implications of AutoRed are multifaceted, both practical and theoretical. Practically, the framework provides datasets (AutoRed-Medium and AutoRed-Hard) that can be used to rigorously evaluate and enhance the safety performance of LLMs, potentially contributing to more robust AI systems. Theoretically, it opens avenues for exploring persona-based adversarial attack strategies, encouraging further research into refining and generalizing automated red teaming methods.
Future research could focus on optimizing the reflection loop efficiency and exploring new persona-guided synthesis strategies that account for evolving model architectures and safety measures. Additionally, further investigations into the granular impacts of persona characteristics on prompt generation could enhance understanding of adversarial instruction dynamics.
Conclusion
AutoRed represents a significant advancement in automated red teaming by eschewing traditional seed-based approaches for a model that delivers semantically diverse and robust adversarial prompts. Its contributions to improving LLM safety evaluation are substantial, showcasing the potential for refined prompt generation frameworks to uncover and mitigate AI vulnerabilities in increasingly complex LLMs.