Evolving Language Models without Labels: Majority Drives Selection, Novelty Promotes Variation (2509.15194v1)
Abstract: LLMs are increasingly trained with reinforcement learning from verifiable rewards (RLVR), yet real-world deployment demands models that can self-improve without labels or external judges. Existing label-free methods, confidence minimization, self-consistency, or majority-vote objectives, stabilize learning but steadily shrink exploration, causing an entropy collapse: generations become shorter, less diverse, and brittle. Unlike prior approaches such as Test-Time Reinforcement Learning (TTRL), which primarily adapt models to the immediate unlabeled dataset at hand, our goal is broader: to enable general improvements without sacrificing the model's inherent exploration capacity and generalization ability, i.e., evolving. We formalize this issue and propose EVolution-Oriented and Label-free Reinforcement Learning (EVOL-RL), a simple rule that couples stability with variation under a label-free setting. EVOL-RL keeps the majority-voted answer as a stable anchor (selection) while adding a novelty-aware reward that favors responses whose reasoning differs from what has already been produced (variation), measured in semantic space. Implemented with GRPO, EVOL-RL also uses asymmetric clipping to preserve strong signals and an entropy regularizer to sustain search. This majority-for-selection + novelty-for-variation design prevents collapse, maintains longer and more informative chains of thought, and improves both pass@1 and pass@n. EVOL-RL consistently outperforms the majority-only TTRL baseline; e.g., training on label-free AIME24 lifts Qwen3-4B-Base AIME25 pass@1 from TTRL's 4.6% to 16.4%, and pass@16 from 18.5% to 37.9%. EVOL-RL not only prevents diversity collapse but also unlocks stronger generalization across domains (e.g., GPQA). Furthermore, we demonstrate that EVOL-RL also boosts performance in the RLVR setting, highlighting its broad applicability.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching LLMs to get better on their own, without needing answer keys or human judges. The authors show that many current “no-label” training tricks make models too cautious and repetitive over time. To fix that, they introduce a new method called EVOL-RL that borrows a simple idea from nature: keep what works (selection) and keep trying new ideas (variation).
What questions did the researchers ask?
They focused on three kid-friendly questions:
- How can a model improve itself using only its own attempts, when there are no right answers provided?
- Why do some popular “majority vote” methods make the model’s thinking shorter, less creative, and weaker over time?
- Can we design a training rule that keeps the model stable and correct, but also curious and diverse in its reasoning?
How did they do it? (Methods in simple language)
Think of the model like a student solving a math problem by writing out different solution attempts:
- Generate several answers per question: The model tries the same problem many times, producing multiple solutions with explanations.
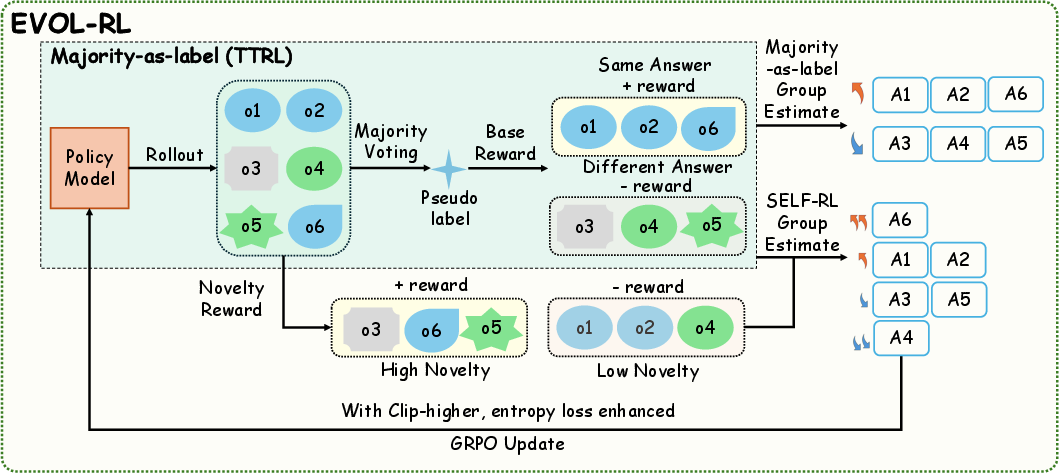
- Majority vote for selection: If most tries end with the same final answer, that answer becomes the “majority.” The model gets a reward for producing the majority answer. This keeps it anchored to what likely works.
- Novelty for variation: The model also gets extra points if its reasoning (the steps it wrote out) is meaningfully different from other tries. In everyday words: don’t just copy the crowd—offer a fresh, sensible path.
- How do they measure “novelty”? They compare the meaning of the reasoning steps using embeddings (a way to turn text into numbers) and reward solutions that are less similar to others. This helps avoid near-duplicates.
- Both majority and minority solutions get a novelty score, but majority always earns more overall. So: correctness first, creativity second.
- Avoiding “entropy collapse”: “Entropy” here means how varied the model’s choices are. Without novelty, the model becomes overly certain, repeats short templates, and stops exploring. EVOL-RL keeps the search lively.
- GRPO training (simple view): GRPO is a way to update the model using a group of its own attempts. It boosts attempts that score better than their peers and lowers the chances of worse ones.
- Two extra helpers:
- Asymmetric clipping: Let especially good, novel attempts influence the model more strongly (so we don’t “clip” away their big positive effect).
- Entropy regularizer: Add a small bonus for staying a bit uncertain so the model keeps exploring and doesn’t get stuck in one way of thinking.
In short: Majority keeps it grounded. Novelty keeps it growing.
What did they find, and why is it important?
Here are the key findings, using math benchmarks as tests:
- Better on first try and across many tries:
- “pass@1” = correct on the first try
- “pass@n” (like pass@16) = correct in any of n tries
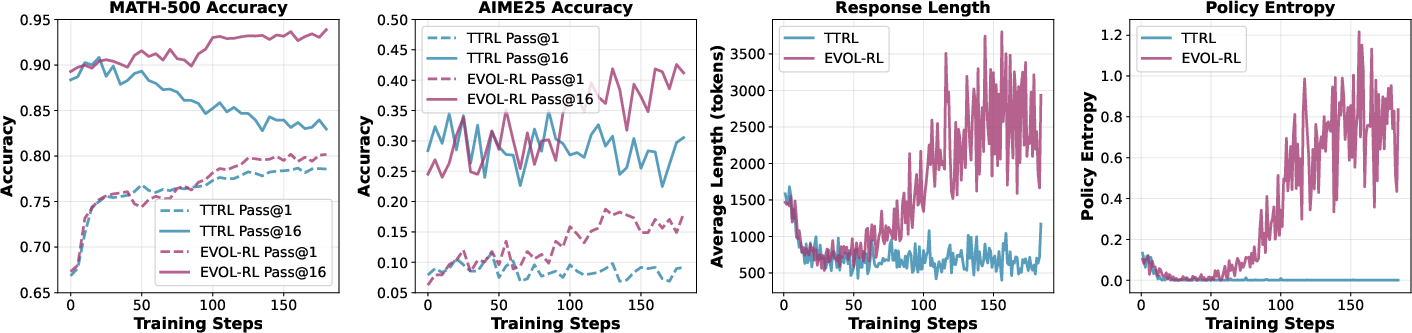
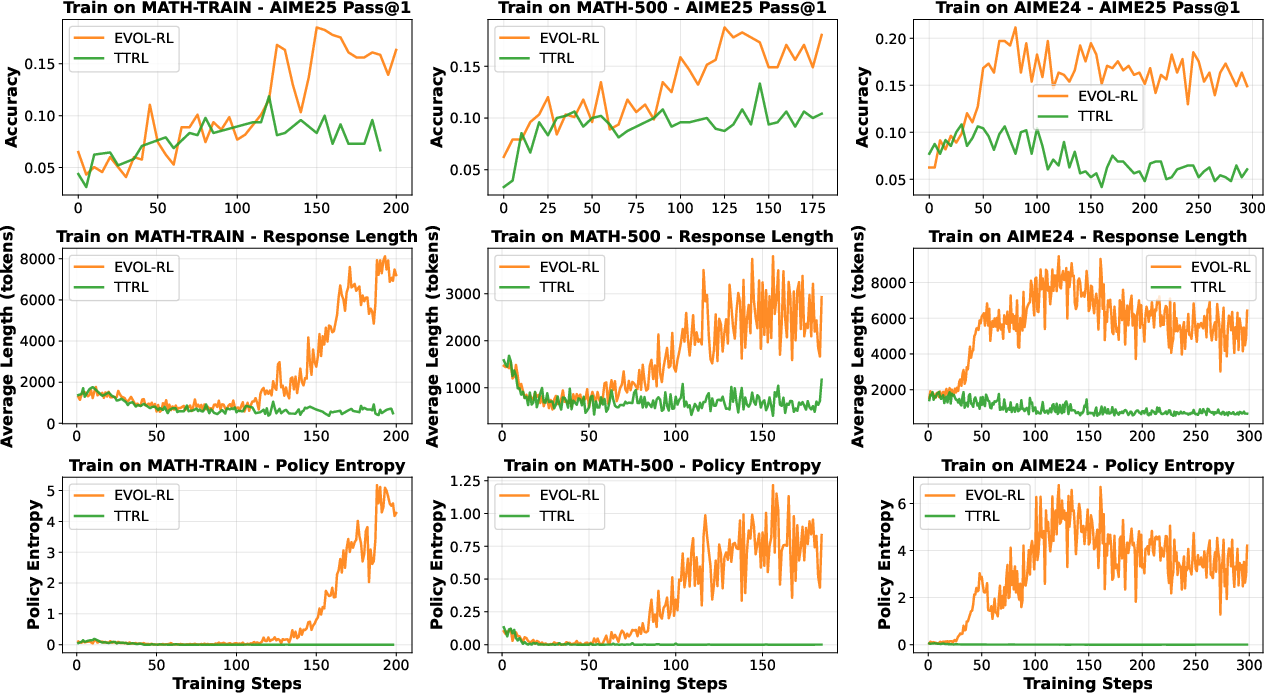
- EVOL-RL improves both. For example, training on AIME24 without labels, Qwen3-4B-Base improved on the AIME25 test from 4.6% to 16.4% (pass@1) and from 18.5% to 37.9% (pass@16).
- Stops diversity collapse:
- Unlike majority-only methods (which make answers shorter and repetitive), EVOL-RL keeps reasoning longer, richer, and more varied. That means the model can try multiple good paths, not just one memorized pattern.
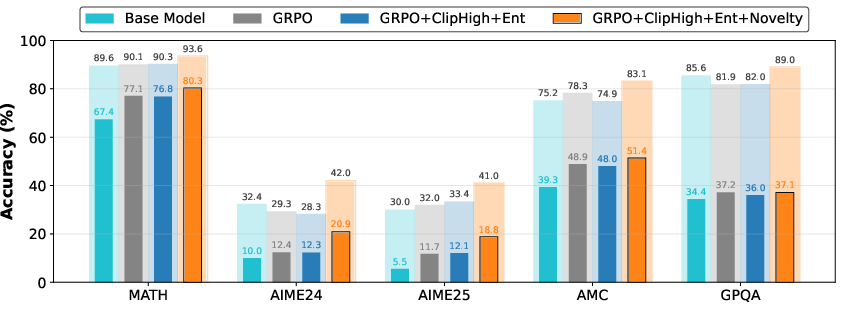
- Generalizes better:
- The model trained on one dataset (like MATH) also gets better on different, harder tests (like AIME25 or GPQA). This shows it’s learning real reasoning skills, not just overfitting.
- Works at different sizes:
- Gains appear in both 4B and 8B models and across small and large training sets.
- Helps even when labels do exist:
- When ground-truth checkers are available (the RLVR setting), adding EVOL-RL’s novelty and exploration tools still boosts performance. So the idea is broadly useful.
Why this matters: Models that only chase the majority get stuck, become brittle, and stop improving. EVOL-RL keeps them stable and curious, which leads to better accuracy and stronger general reasoning.
Why did “majority-only” methods fail?
Imagine a class where everyone copies the most common answer. At first, scores rise a bit. But soon, everyone writes the same short solution, even if it’s not great. New ideas vanish. That’s what “entropy collapse” looks like in a model: fewer different answers, shorter explanations, worse results when problems change.
EVOL-RL fixes that by always preferring the likely-correct answer (majority) but rewarding fresh, sensible reasoning paths (novelty). This balance prevents the model from narrowing down to one brittle way of thinking.
What’s the big picture? (Implications)
- Self-improving models without answer keys: EVOL-RL shows a simple recipe to let models learn from their own attempts in the wild, where labeled data is scarce.
- More reliable reasoning: By keeping multiple good ways to solve problems, models become less fragile and more adaptable to new tasks.
- A general training rule: The “selection + variation” idea is powerful and simple—use the crowd’s best guess as an anchor, and keep encouraging diverse, thoughtful paths to get there.
Overall, EVOL-RL provides a practical and effective way for AI to evolve its reasoning—staying correct while staying creative.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper that future work could address:
- Generality beyond math QA: Evaluate EVOL-RL on non-math, open-ended reasoning (e.g., long-form QA, summarization, planning), coding, multimodal tasks, and interactive tool use to test applicability without numeric/verifiable answers.
- Majority anchor without verifiable final answers: Develop a principled “selection” signal for open-ended outputs where majority voting over final answers is ill-defined or unreliable.
- Scale and model diversity: Test on larger models (e.g., 14B–70B, MoE) and different architectures or instruction-tuned bases to assess scaling laws and architecture sensitivity.
- Compute efficiency and cost: Quantify training/inference costs (tokens processed, GPU hours, energy), analyze cost–benefit trade-offs of generating up to 64 samples with long (≥12k tokens) chains, and compare to test-time scaling baselines under equal compute.
- Pairwise novelty scalability: The novelty computation is O(G2) per prompt; investigate subquadratic approximations, clustering, or learned novelty critics for large G.
- Sensitivity to hyperparameters: Provide systematic studies on α in the novelty score, intra-group normalization, group sizes (G=64 rollout, 32 update), entropy coefficient λ_ent, and asymmetric clipping ranges; derive default recipes and robustness envelopes.
- Embedding choice for novelty: Assess robustness to the embedding model used for “reasoning” similarity (domain mismatch in math CoT, multilinguality), and compare alternatives (task-specific encoders, supervised similarity, token-level or step-level novelty).
- Reward hacking risk: Determine whether the novelty reward incentivizes superficial paraphrases, unnecessary verbosity, or syntactic perturbations rather than truly distinct reasoning paths; propose anti-gaming countermeasures.
- Length bias and verbosity: Measure whether novelty/entropy pushes longer but not more correct chains; introduce brevity-normalized or information-theoretic novelty to prevent cost inflation.
- Incorrect-majority anchoring: Analyze failure modes when the majority is wrong; design mechanisms allowing minority-but-novel candidates to occasionally overcome wrong majorities without labels (e.g., uncertainty-aware band overlap, adaptive exploration bonuses).
- Reward-band design: Study alternatives to fixed, non-overlapping bands (e.g., continuous mappings, learned band boundaries, curriculum schedules) and quantify their impact on exploration–exploitation balance.
- Advantage normalization effects: Examine how group z-scoring interacts with bimodal rewards and outliers; compare to robust normalization, per-token advantages, or baseline critics.
- Theoretical guarantees: Formalize conditions under which EVOL-RL avoids mode collapse, characterize fixed points, and provide convergence or stability analyses relative to majority-only methods.
- Diversity measurement: Go beyond entropy and length; report semantic diversity metrics (e.g., cluster counts, intra-/inter-cluster distances, self-BLEU, distinct-n) to substantiate “collapse prevention.”
- Continual/online evolution: Validate on non-stationary data streams with task shifts, replay/regularization for forgetting, and long-horizon stability; quantify retention and forward/backward transfer.
- Robustness and safety: Evaluate hallucination rates, harmful content, and robustness to adversarial prompts; assess whether novelty rewards exacerbate unsafe diversity.
- Verifier noise in RLVR: When pairing with verifiable rewards, paper robustness to noisy or partial verifiers and mixed label-free/verified training schedules.
- Prompt dependence: Measure sensitivity to system prompts and decoding parameters (temperature, nucleus/top-k), and derive prompt- and decoding-robust configurations.
- Inference-time synergy: Compare EVOL-RL to test-time scaling methods (e.g., s1) under matched compute; paper combinations with best-of-n, reranking, or tree search at inference.
- Minority-group novelty design: Justify intra-group normalization and novelty in minority clusters; test global vs group-relative novelty and its effect on discovering new correct modes.
- Reasoning segmentation: Specify and evaluate methods for extracting the “reasoning part” used for embeddings; test robustness to different segmentation heuristics and CoT formats.
- Statistical rigor: Report multi-seed results, confidence intervals, and significance tests; analyze variance across runs to ensure reliability of observed gains.
- Data leakage and evaluation hygiene: Training on test sets (MATH-500, AIME24) risks overfitting; include strict OOD benchmarks and leakage checks to corroborate “evolution” claims.
- Multilingual and cross-domain transfer: Test EVOL-RL on non-English datasets and heterogeneous domains to assess embedding and reward generality.
- Resource and environmental impact: Provide carbon/energy footprints and explore efficiency improvements (e.g., smaller G with smarter sampling, early stopping, distillation of diverse strategies).
Glossary
- Advantage (standardized advantage): In policy-gradient methods, an estimate of how much better a sampled action or trajectory is compared to its peers or baseline, often used to scale updates. "This high novelty translates to a large standardized advantage"
- AIME24: A high-difficulty math competition benchmark (2024) used to evaluate LLM reasoning. "the competition-level AIME24"
- AIME25: A high-difficulty math competition benchmark (2025) used to test generalization after training. "AIME25 pass@1 from TTRL's 4.6% to 16.4%"
- AMC: The American Mathematics Competitions benchmark used to evaluate mathematical reasoning. "The evaluation suite includes AIME24, AIME25, MATH500, AMC, and GPQA."
- Asymmetric clipping: In PPO-like objectives, using different clipping bounds for increasing vs. decreasing probability ratios to preserve strong positive signals. "EVOL-RL also uses asymmetric clipping to preserve strong signals"
- Chain of thought: The explicit multi-step reasoning traces generated by an LLM to solve a problem. "maintains longer and more informative chains of thought"
- Clipped surrogate objective: The PPO-style objective that limits the change in policy probability ratios to stabilize training. "The policy is optimized with a clipped surrogate objective:"
- Cosine similarity matrix: A matrix of pairwise cosine similarities between embeddings, used here to measure semantic closeness of reasoning traces. "We compute embeddings for the reasoning part of each response to form a cosine similarity matrix."
- Entropy collapse: A degradation in exploration where model outputs become short, repetitive, and low-entropy. "causing an entropy collapse: generations become shorter, less diverse, and brittle."
- Entropy regularizer: A term added to the loss to encourage higher entropy in token distributions, promoting exploration. "we add a token-level entropy regularizer to maintain diversity during the initial generation process:"
- Evolutionary computation: A family of algorithms inspired by biological evolution that balance selection and variation to avoid premature convergence. "This idea motivates decades of algorithms in evolutionary computation—genetic algorithms \citep{holland1992adaptation,eiben2015introduction}, novelty search \citep{lehman2011abandoning}, and quality–diversity (QD) methods such as MAP-Elites \citep{pugh2016quality}—"
- EVOL-RL: EVolution-Oriented and Label-free Reinforcement Learning; a method that couples majority-based selection with novelty-driven variation to prevent collapse. "we propose EVolution-Oriented and Label-free Reinforcement Learning (EVOL-RL), a simple rule that couples stability with variation under a label-free setting."
- GPQA: A cross-domain reasoning benchmark used to test generalization beyond mathematics. "across domains (e.g., GPQA)."
- GRPO: Group Relative Policy Optimization; a policy-gradient method for LLMs that normalizes rewards within sampled groups and uses a PPO-style objective. "Group Relative Policy Optimization (GRPO) \citep{shao2024deepseekmath} is a policy-gradient algorithm designed for fine-tuning LLMs without a separate value function."
- KL penalty: A regularization term based on Kullback–Leibler divergence that discourages the new policy from deviating too far from the old one. "regularized by a KL penalty to ensure stable learning."
- Majority vote: Using the most common final answer among multiple samples as a pseudo-label for selection. "keeps the majority-voted answer as a stable anchor (selection)"
- MAP-Elites: A quality–diversity algorithm that preserves diverse high-performing behaviors across feature dimensions. "quality–diversity (QD) methods such as MAP-Elites"
- Min-max normalization: Scaling values within a group to a fixed range (e.g., [0,1]) to compare relative scores fairly. "Finally, we min-max normalize the scores~ separately within the majority and minority groups to get~."
- Novelty score: A scalar that quantifies how semantically distinct a response’s reasoning is from others, combining mean and max similarity penalties. "The novelty score is:"
- Novelty search: An evolutionary strategy that prioritizes behavior diversity over immediate performance to avoid premature convergence. "novelty search \citep{lehman2011abandoning}"
- OOD (out-of-domain): Data or tasks that differ from the distribution seen during training, used to assess generalization. "out-of-domain (OOD) problems"
- Pass@1: Accuracy achieved with a single attempt (one sampled response). "improves both pass@1 and pass@n."
- Pass@16: Accuracy achieved when up to 16 sampled attempts are allowed; measures multi-path reliability. "pass@16 from 18.5\% to 37.9\%."
- Pass@k: Accuracy computed over k sampled attempts; higher k tests solution diversity and robustness. "i.e., pass@k"
- Policy entropy: The entropy of the model’s token distribution during generation, used as a proxy for exploration level. "policy entropy on the training set."
- PPO-style clipped objective: The Proximal Policy Optimization objective that constrains policy updates via clipping to stabilize learning. "update the policy with a PPO-style clipped objective"
- Quality–Diversity (QD): Methods that aim to discover a set of diverse, high-quality solutions, balancing performance and behavioral variation. "quality–diversity (QD) methods such as MAP-Elites"
- Reward bands: Disjoint intervals assigned to different classes of responses (e.g., majority vs. minority) to prioritize selection while refining with novelty. "We map the majority label and normalized novelty score into non-overlapping reward bands."
- RLVR (Reinforcement Learning with Verifiable Rewards): Training with automated correctness checks (verifiers) to provide reward signals, common in math/coding tasks. "Reinforcement Learning with Verifiable Rewards (RLVR)"
- Semantic space: The embedding space where textual reasoning traces are represented, enabling similarity-based novelty scoring. "measured in semantic space."
- TTA (Test-Time Adaptation): Adjusting a model to a specific test distribution during inference, often yielding narrow gains. "test-time adaptation (TTA)."
- TTRL (Test-Time Reinforcement Learning): An RL approach that uses majority-vote pseudo-labels from multiple samples to adapt models at test time. "Test-Time Reinforcement Learning (TTRL)"
- Variation–Selection principle: The evolutionary rule that progress arises from generating diverse candidates (variation) and retaining effective ones (selection). "mirrors the variation–selection principle"
- Verifier (ground-truth verifier): An external automated checker that confirms correctness of outputs and provides rewards in supervised RL settings. "with a ground-truth verifier (RLVR)"
- Z-score normalization: Standardizing scores within a group by subtracting the mean and dividing by the standard deviation to obtain comparable advantages. "Rewards within the group are normalized with a z-score"
Collections
Sign up for free to add this paper to one or more collections.

