Metacognitive Reuse: Turning Recurring LLM Reasoning Into Concise Behaviors
Abstract: LLMs now solve multi-step problems by emitting extended chains of thought. During the process, they often re-derive the same intermediate steps across problems, inflating token usage and latency. This saturation of the context window leaves less capacity for exploration. We study a simple mechanism that converts recurring reasoning fragments into concise, reusable "behaviors" (name + instruction) via the model's own metacognitive analysis of prior traces. These behaviors are stored in a "behavior handbook" which supplies them to the model in-context at inference or distills them into parameters via supervised fine-tuning. This approach achieves improved test-time reasoning across three different settings - 1) Behavior-conditioned inference: Providing the LLM relevant behaviors in-context during reasoning reduces number of reasoning tokens by up to 46% while matching or improving baseline accuracy; 2) Behavior-guided self-improvement: Without any parameter updates, the model improves its own future reasoning by leveraging behaviors from its own past problem solving attempts. This yields up to 10% higher accuracy than a naive critique-and-revise baseline; and 3) Behavior-conditioned SFT: SFT on behavior-conditioned reasoning traces is more effective at converting non-reasoning models into reasoning models as compared to vanilla SFT. Together, these results indicate that turning slow derivations into fast procedural hints enables LLMs to remember how to reason, not just what to conclude.
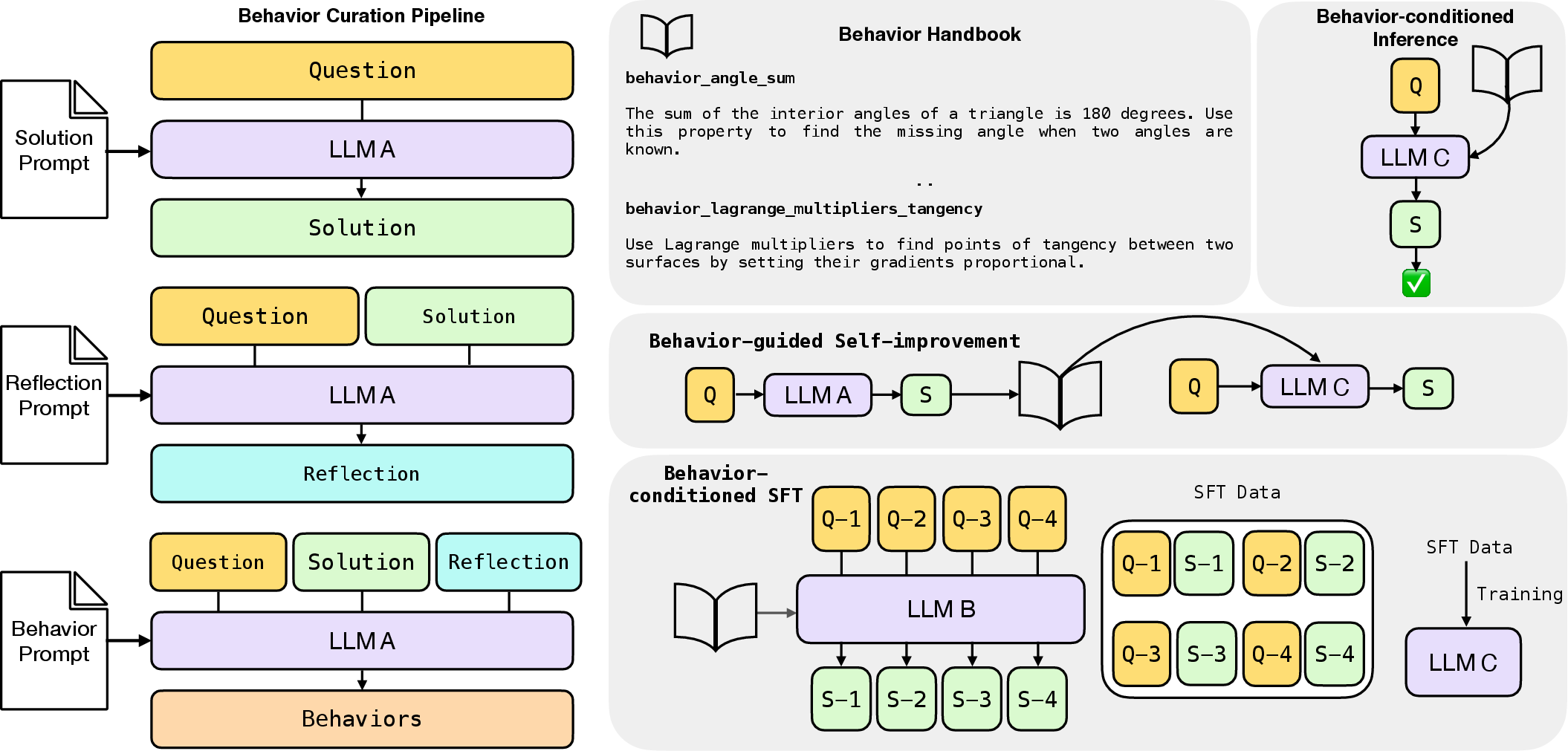

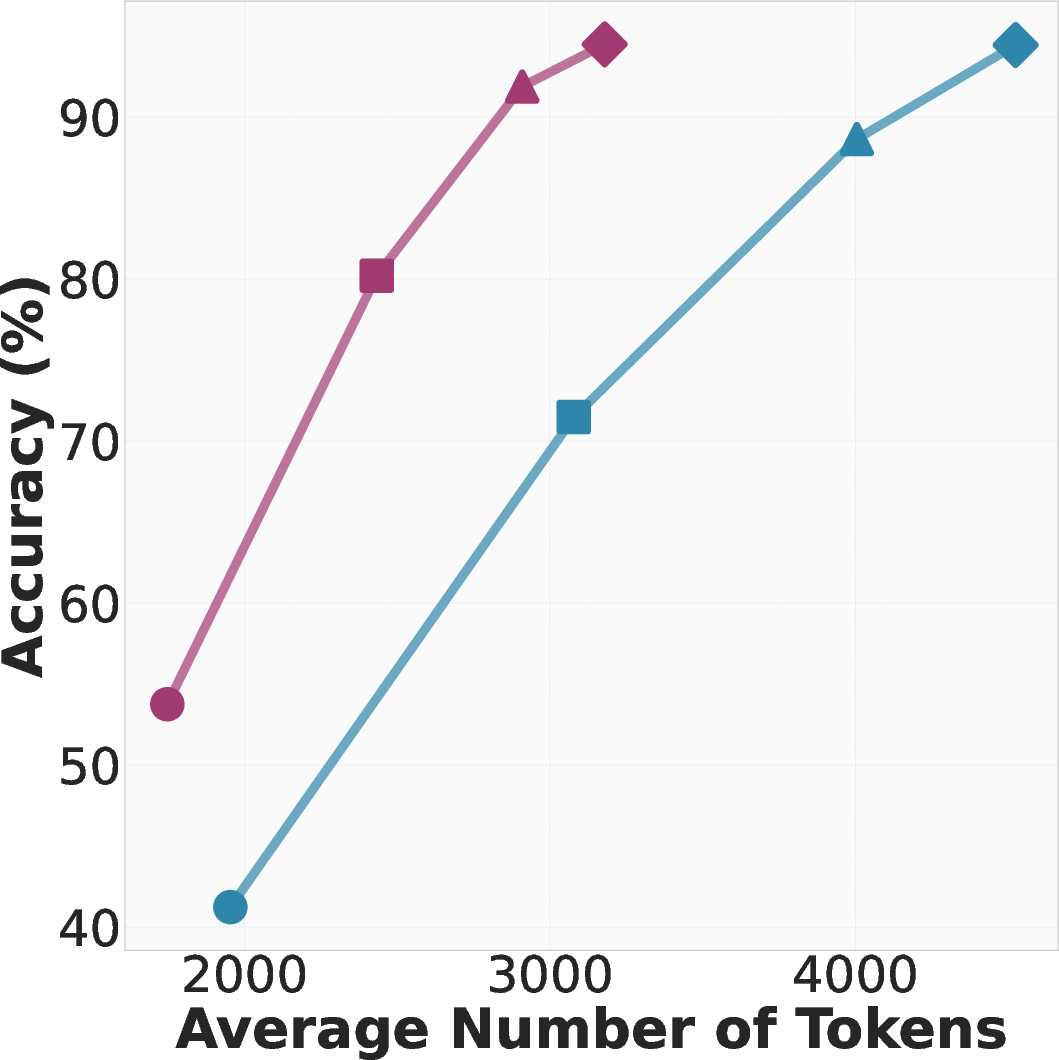

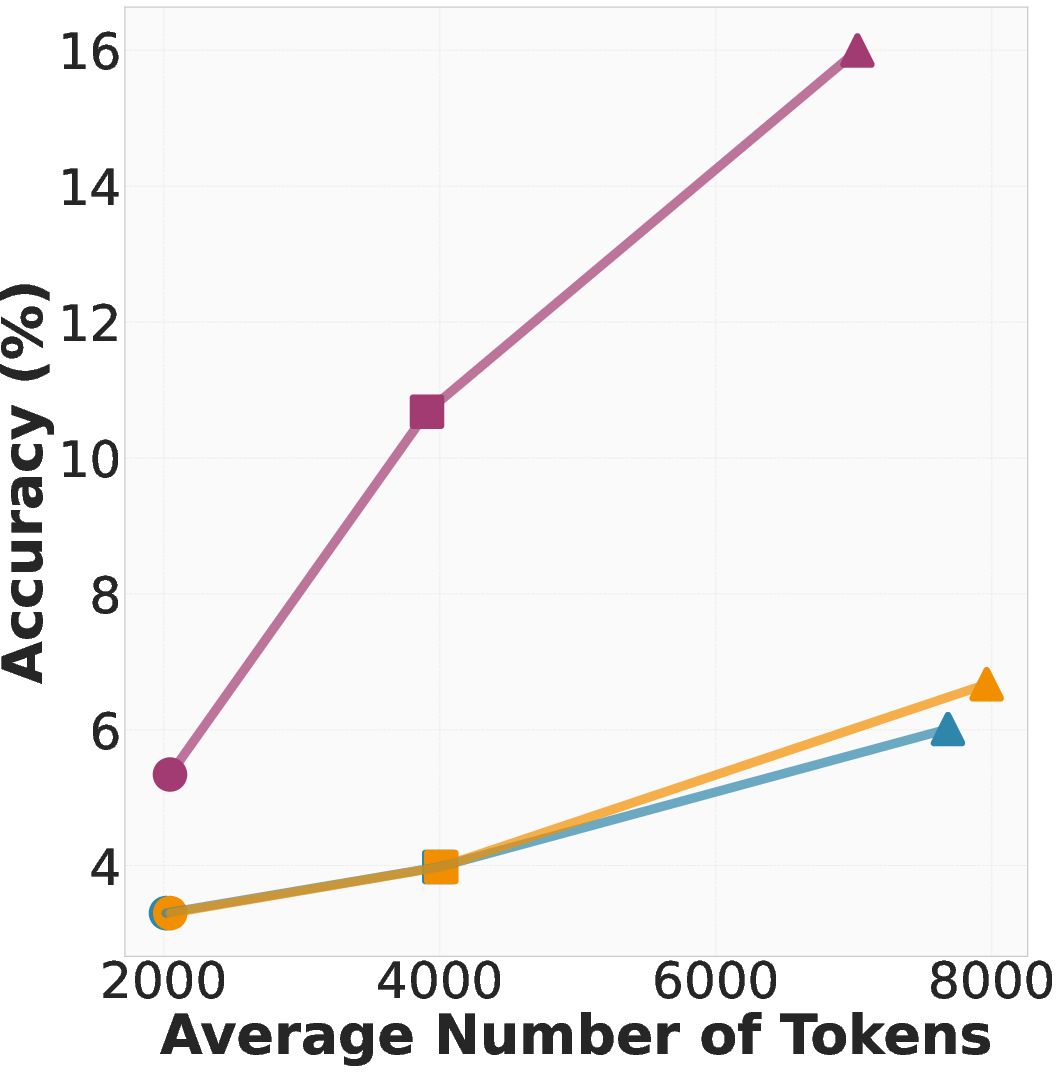
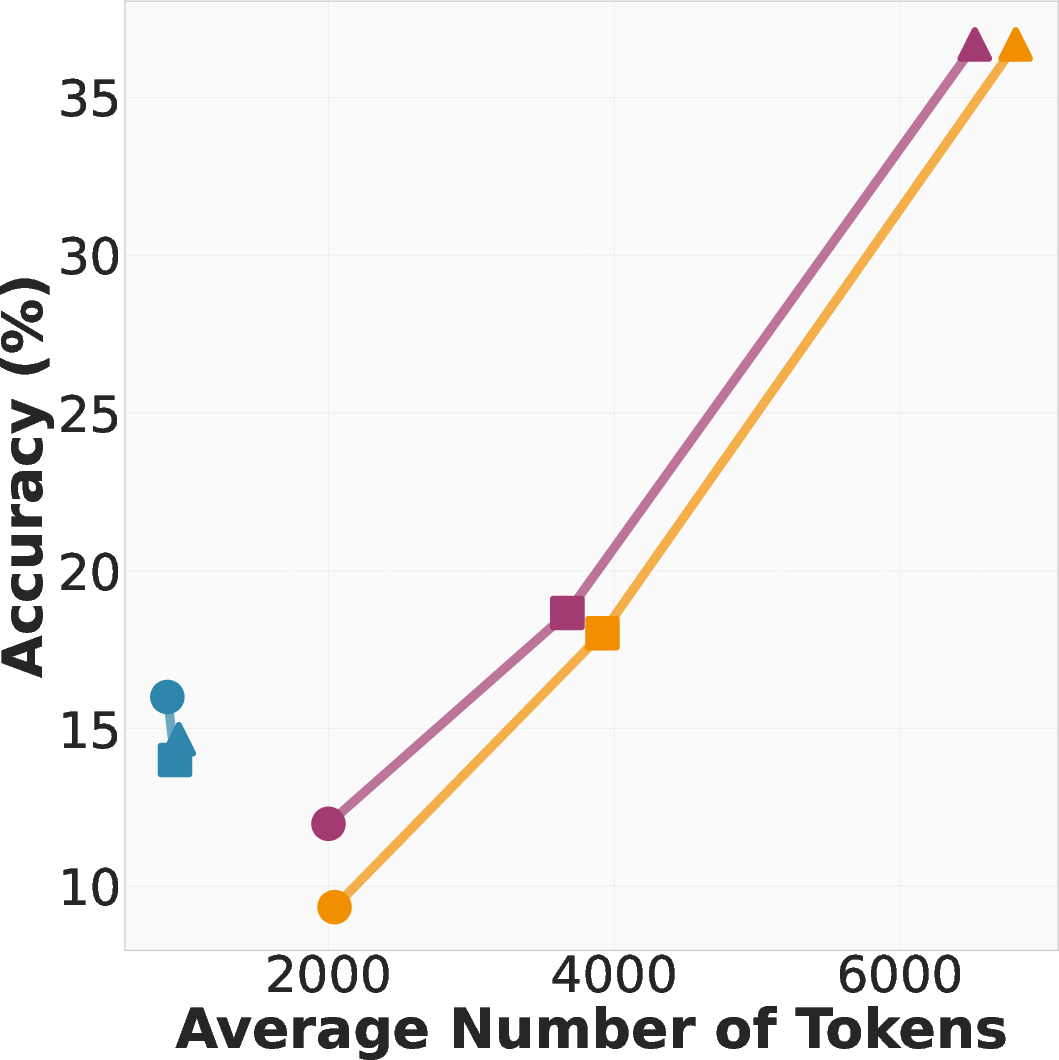
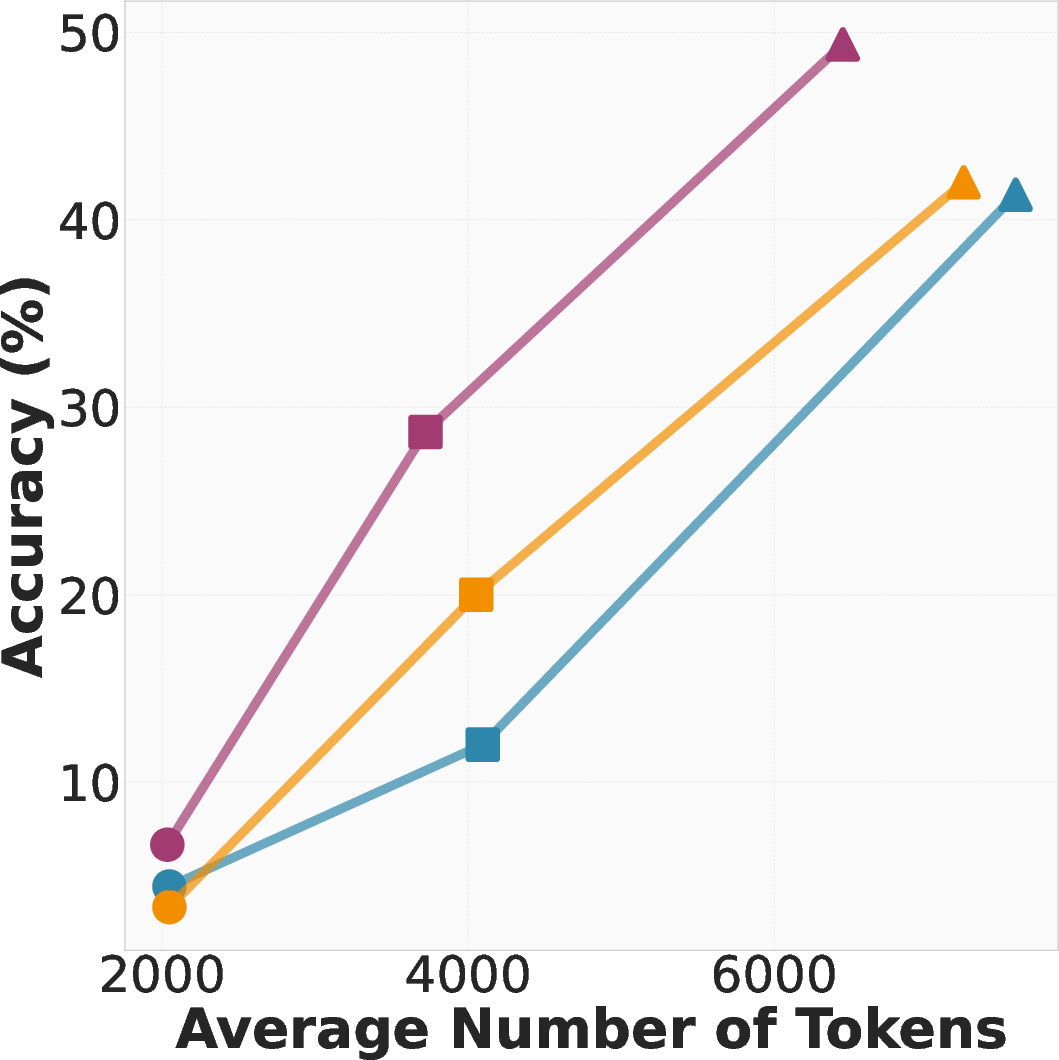

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI LLMs to remember how to solve problems more efficiently. Instead of re-explaining common steps every time (which wastes time and space), the model learns short, reusable “behaviors” — like a playbook of smart moves — that help it think faster and smarter on new problems.
Key Objectives
The researchers asked three simple questions:
- Can an AI turn repeated reasoning steps into short, named strategies (behaviors) it can reuse later?
- If we give these behaviors to the model while it thinks, will it solve problems just as well (or better) using fewer words?
- If we train a model on examples that use these behaviors, will it become a better “reasoning” model overall?
How They Did It
What is a “behavior”?
Think of a behavior like a recipe card for thinking. It has:
- a short name (e.g., “systematic_counting”)
- a one‑sentence instruction (e.g., “Count possibilities without overlap to avoid missing or double-counting cases.”)
These are not facts (“What is the capital of France?”). They are procedures (“How should I approach counting problems?”). That’s called procedural knowledge — knowing how to think — not just declarative knowledge — knowing what is true.
Building a behavior handbook (the “playbook”)
The model follows a three-step cycle on past problems:
- Solve: It writes out its chain of thought and answer.
- Reflect: It reviews its own solution to spot general steps that could be reused.
- Extract behaviors: It turns those steps into short, named behaviors and saves them in a searchable “behavior handbook.”
This is called metacognition — “thinking about thinking.”
Using the behaviors in three ways
The team tested behaviors in three settings:
- Behavior‑conditioned inference (BCI): At test time, give the model a few relevant behaviors alongside a new question, so it can use them while thinking.
- Behavior‑guided self‑improvement: The model learns from its own earlier attempts on the same question by extracting behaviors from them and trying again, now guided by those behaviors.
- Behavior‑conditioned supervised fine‑tuning (BC‑SFT): Train a new model on solutions that were written using behaviors so that, over time, the behaviors become part of the model’s “muscle memory.” Then the model doesn’t need behavior cards at test time.
A note on some technical terms (in everyday language)
- Token: a “chunk” of text (like a word piece). Fewer tokens = shorter, faster answers.
- Context window: the model’s short-term memory backpack. If it’s crammed with long thinking, there’s less room for new ideas.
- Retrieval: like using a mini search engine to find the most relevant behaviors for a question.
- Fine‑tuning: extra training so a model picks up new habits — like practicing drills in sports.
Main Findings
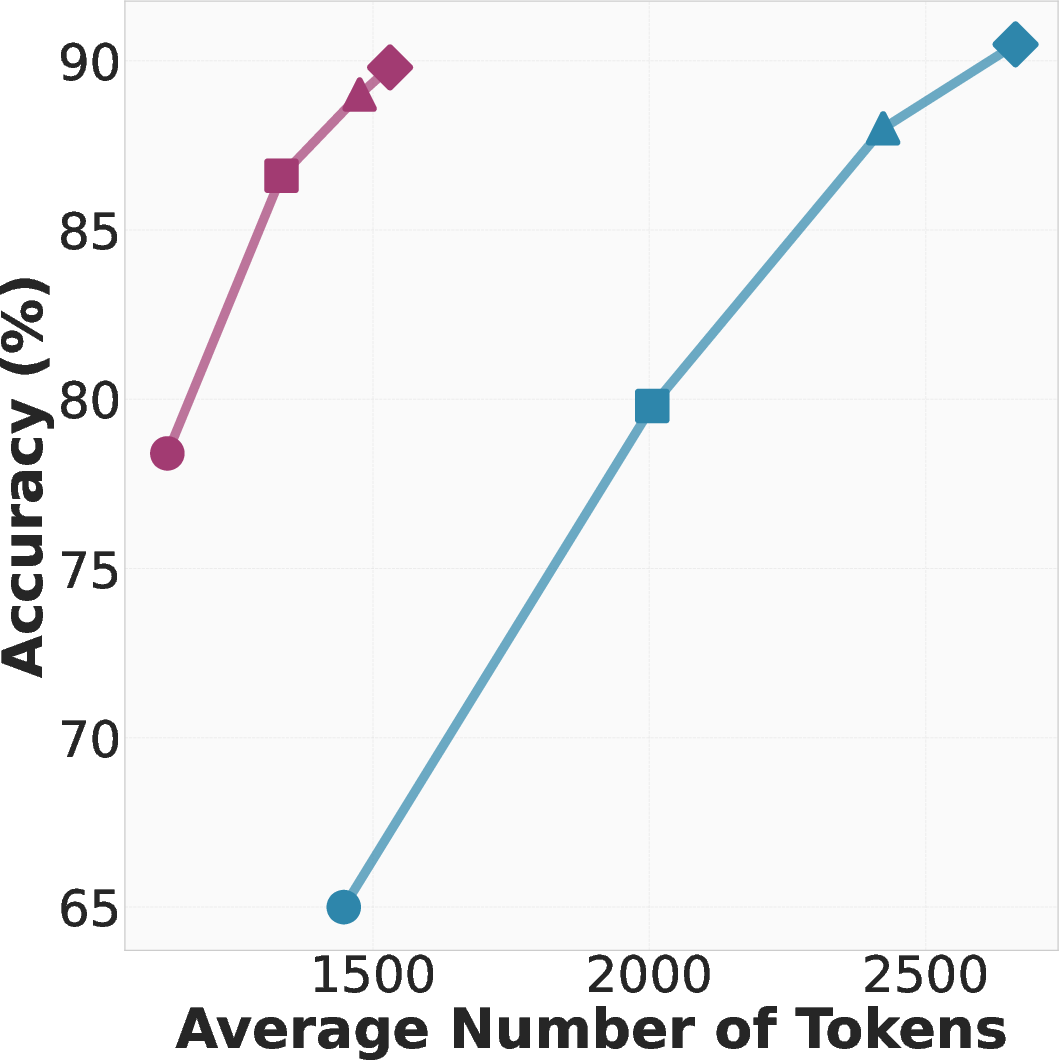
Here are the key results from tests on math benchmarks (MATH and AIME):
- Behavior‑conditioned inference (BCI): When the model was given relevant behaviors as hints, it needed up to 46% fewer tokens to think through problems, while matching or improving accuracy. In plain terms: it thought shorter, but just as well or better.
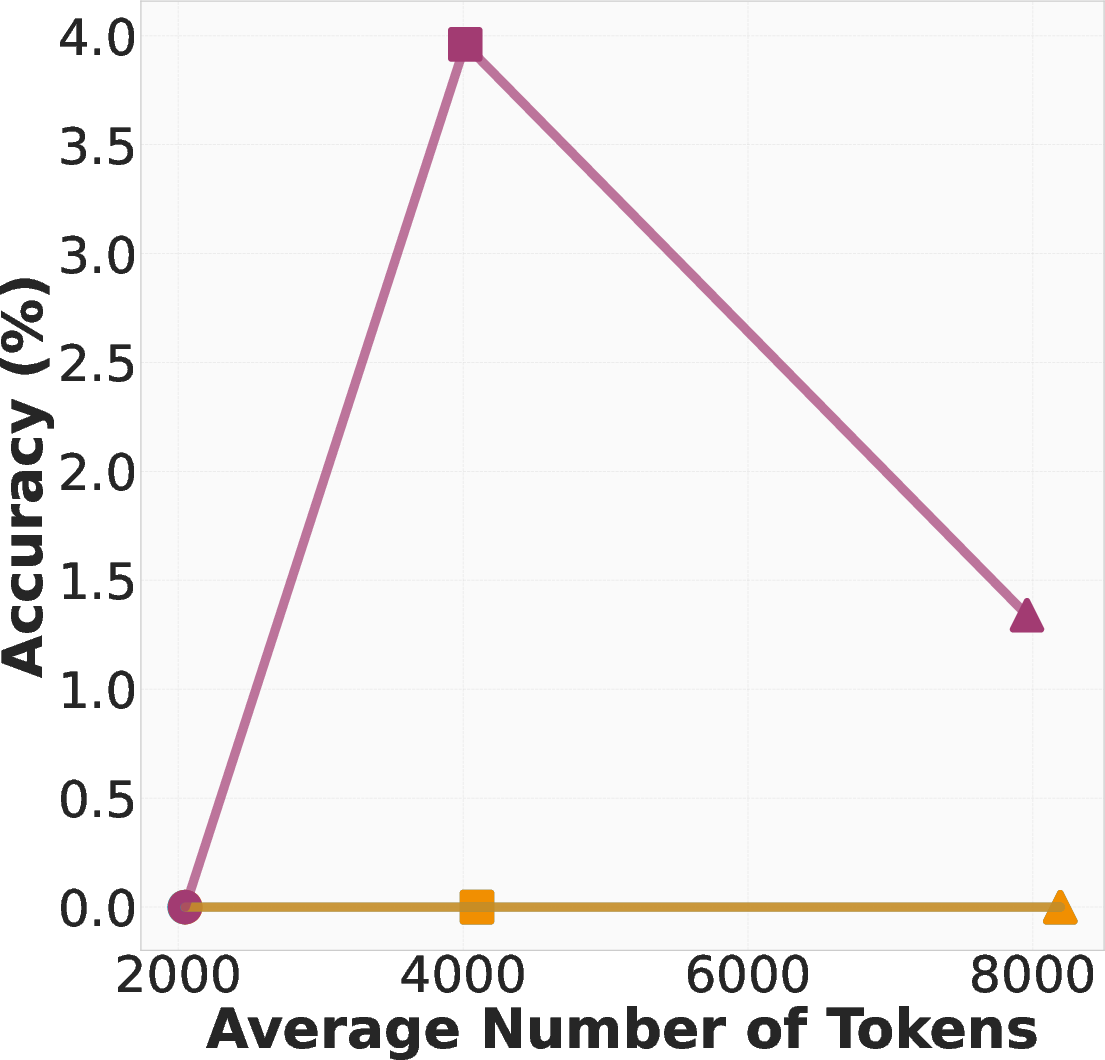
- Behavior‑guided self‑improvement: Without changing the model’s parameters, letting it reuse behaviors from its own earlier attempts raised accuracy by up to 10% compared to a common “critique-and-revise” baseline. In other words: learning from your own playbook beats just rereading your old answer.
- Behavior‑conditioned fine‑tuning (BC‑SFT): Training on behavior‑based solutions made “non‑reasoning” models turn into stronger reasoning models than standard training did. They were both more accurate and more concise.
Why this matters:
- The model spends less time re-deriving the same steps, saving tokens and speeding up answers.
- The model gets better at solving problems — not only at reaching the final answer, but at choosing smart steps along the way.
- This suggests a path for AI to build a growing library of thinking strategies over time.
Implications and Impact
- Smarter memory: Most AI memory tools store facts. This paper shows how to store “how-to” strategies. It’s like giving the model a toolbox, not just an encyclopedia.
- Better efficiency: Shorter reasoning saves cost and time, which matters a lot when many questions are answered at once.
- Beyond math: The same idea could help in coding, science, planning, and other multi-step tasks — anywhere repeated thinking patterns appear.
- Limitations and next steps:
- Today, behaviors are chosen at the start of a solution and don’t change mid-way. A future upgrade could let the model pull new behaviors on the fly while thinking.
- The paper focuses on math and fairly small behavior libraries. Scaling to huge, cross‑topic behavior handbooks is an open challenge.
In short: This research turns long, repeated chains of thought into short, reusable thinking habits. That helps AI models remember how to reason — not just what to answer — making them faster, cheaper, and often more accurate.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper. Items are grouped for clarity.
Behavior definition, quality, and management
- Lack of formal criteria for “good” behaviors: no quantitative definition of specificity, generality, length, or actionability; no scoring or filtering pipeline to prioritize high‑impact behaviors.
- No procedure for deduplication, consolidation, or conflict resolution among overlapping or contradictory behaviors as the handbook grows.
- Unclear canonical naming/ontology: how to standardize behavior names, map synonyms, and maintain a taxonomy that supports discoverability and retrieval across domains.
- No evaluation of behavior correctness or safety pre‑deployment: behaviors are model‑generated and may contain subtle errors or unsafe instructions; absent automated validation or human‑in‑the‑loop vetting.
- No analysis of misapplication rates: how often retrieved behaviors are inapplicable or harmful to a given problem and how to detect/prevent misuse.
- No lifecycle strategy: policies for versioning, pruning stale behaviors, provenance tracking, and auditing updates over time.
Retrieval and integration during reasoning
- Static, one‑shot provisioning: behaviors are retrieved once at the start; no on‑the‑fly, iterative retrieval as new subgoals emerge in long solutions.
- No learned retrieval policy: retrieval uses topic labels (MATH) or embedding similarity (AIME) with fixed top‑k; absent learning‑to‑retrieve or RL policies to optimize relevance and minimality.
- No sensitivity analyses for retrieval hyperparameters (e.g., k, embedding model choice, similarity threshold) or ablations on retrieval quality vs. performance.
- No mechanism for behavior selection under context budget constraints: how to choose a minimal subset that maximizes utility while minimizing prompt overhead.
- Absent robustness checks against retrieval errors, adversarial or irrelevant behaviors, and prompt injection via behavior content.
Generalization and scope beyond math
- Domain transfer untested: no experiments on programming, formal proofs, scientific QA, multi‑hop QA, planning, or dialogue to validate proposed domain‑agnostic claims.
- Cross‑lingual generalization unexplored: whether behaviors extracted in one language transfer to others and how multilingual behavior handbooks should be designed.
- No study of behavior compositionality: how multiple behaviors combine, interfere, or synergize in complex multi‑step tasks.
Causality and mechanism of improvement
- No causal attribution of gains to behaviors: absent ablations isolating behavior content vs. formatting vs. additional prompt structure; no behavior “dropout” studies.
- No analysis of which specific behaviors drive improvements for which problem types; missing per‑behavior impact metrics and credit assignment.
- For BC‑SFT, unclear whether gains stem from distilled procedural strategies vs. stylistic/length regularities; needs matched‑length and style‑controlled training controls.
Scaling the behavior handbook
- No empirical demonstration of scaling to large, cross‑domain libraries (millions of behaviors): memory footprint, indexing, latency, and retrieval quality at scale remain untested.
- No incremental update strategy for FAISS or alternative indices to support continuous ingestion, decay, and low‑latency retrieval in production settings.
- Missing cost–benefit analysis: end‑to‑end wall‑clock latency and dollar costs for building, maintaining, and querying large handbooks vs. savings from reduced output tokens.
Training and fine‑tuning questions (BC‑SFT)
- Catastrophic interference/forgetting unstudied: how BC‑SFT affects previously learned capabilities, and how to prevent overfitting to behavior‑conditioned styles.
- Data construction confounds: BC‑SFT uses 1 trace per problem to curate behaviors—no ablation on number/quality of traces and its effect on distilled behaviors.
- No curriculum or schedule design: how to mix behavior‑conditioned and vanilla traces, or stage training to maximize retention and generalization.
- Absent analysis of parameter‑efficiency: whether LoRA/adapters suffice to internalize behaviors vs. full‑parameter FT, and how capacity limits affect retention of many behaviors.
Self‑improvement setting
- Circularity risk: using the same model to generate traces, extract behaviors, and then self‑improve may confound improvements with exposure/selection effects; needs comparison to self‑consistency, majority vote, or external teacher‑guided baselines.
- Token‑efficiency regression: behavior‑guided self‑improvement produced more tokens than critique‑and‑revise; unclear how to recover efficiency while preserving accuracy.
- No robustness to noisy initial traces: how behavior extraction handles incorrect or low‑quality traces and how noise propagates into the behavior set.
Evaluation design and rigor
- Limited benchmarks: results are on MATH‑500 and AIME’24/’25; unclear generality across broader math distributions (e.g., GSM8K‑hard, MATH‑full, competition proofs).
- Potential data contamination not audited: teacher/student may have seen AIME/MATH in pretraining; no decontamination checks or withheld categories analysis.
- Small‑scale AIME training source (AIME’22/’23, 60 questions): overfitting risks not quantified; no cross‑year robustness tests beyond the two held‑out years.
- Lack of statistical significance tests and variance reporting beyond mean/seed counts; no per‑category error analysis to identify where behaviors help/hurt.
- No human evaluation of reasoning quality (e.g., faithfulness, logical soundness) or interpretability beyond token counts and accuracy.
Safety, alignment, and governance
- Safety risks of behavior reuse: behaviors might encode unsafe shortcuts or bias; no red‑teaming or safety filters specific to procedural content.
- Misalignment under distribution shift: no safeguards to prevent applying high‑confidence but wrong behaviors in unfamiliar contexts.
- Governance unanswered: who curates/approves behaviors, how to attribute credit, and how to prevent IP/policy violations when behaviors are model‑generated.
Comparisons to stronger baselines
- Missing head‑to‑head comparisons with state‑of‑the‑art efficiency/accuracy methods: SoT, Self‑Consistency with routing, ReAct/IR‑CoT, MinD, TokenSkip, or learned tool use.
- No integration experiments: whether behaviors complement tool use (e.g., calculators, theorem provers) or memory systems (e.g., RAG for procedures vs. facts).
Theoretical and interpretability questions
- No formalization linking “behavior” to learned internal circuits or algorithmic priors; lacks measures of procedural knowledge vs. declarative knowledge in parameters.
- No theory for optimal granularity: when a behavior is too atomic vs. too broad; how granularity affects transfer and retrieval efficiency.
Practical deployment considerations
- Input vs. output token economics assumed, not measured: no concrete cost benchmarks under common API pricing, batching, and cache reuse.
- Context‑window management: impact of behavior tokens on long‑context tasks and interference with other system prompts is not studied.
- Compatibility across model families/sizes: partial evidence with Qwen/Llama, but no systematic study of teacher–student family mismatch, scaling laws, or minimal teacher strength needed.
These gaps outline concrete next steps: rigorous ablations for causality and retrieval, scalable systems engineering for large handbooks, cross‑domain generalization studies, safety/governance protocols, and competitive baselines/integrations to establish when behavior handbooks are the best tool for efficient, reliable reasoning.
Collections
Sign up for free to add this paper to one or more collections.

