- The paper demonstrates that augmenting reasoning models with external tools significantly enhances accuracy on structured reasoning tasks.
- It employs methodologies like Program-of-Thought and scratchpad memory to overcome token limitations and execute Python code, achieving near-perfect results on benchmarks.
- Empirical results reveal that tool-augmented models consistently outperform traditional LLMs, particularly on tasks like River Crossing and Blocks World.
This essay provides a comprehensive analysis of the paper "Thinking Isn't an Illusion: Overcoming the Limitations of Reasoning Models via Tool Augmentations" (2507.17699). The work investigates the reasoning capabilities of Large Reasoning Models (LRMs) when augmented with external tools such as Python interpreters and scratchpads.
Introduction to Reasoning Models
LLMs, such as GPT and Qwen, have demonstrated impressive generalization and reasoning abilities. Recent developments have focused on Large Reasoning Models (LRMs), which aim to explicitly incorporate thinking processes like Chain-of-Thought (CoT) prompting and self-reflection. However, some empirical studies have questioned the actual reasoning improvements provided by these LRMs. This paper reevaluates these claims by integrating tools that facilitate enhanced reasoning pathways.
Figure 1: Research Question.
Experimental Setup
The study systematically evaluates LRMs and LLMs using Apple's Thinking-Illusion benchmark, which includes reasoning tasks such as Hanoi Tower, Checker Jumping, River Crossing, and Blocks World. The primary evaluation framework is tool-augmented, enabling models to use Python interpreters and scratchpad memory to circumvent the limitations of static output lengths.
- Program-of-Thought (PoT): This framework allows models to generate and execute Python code externally, thus enabling complex reasoning beyond their token limits.
- Think-and-Execute: This method treats the model as a pseudo-interpreter by having it reason in the syntax of Python code without external execution.
- Scratchpad: This approach uses an external memory buffer to store intermediate states, enabling models to construct longer reasoning chains incrementally (Figure 2).
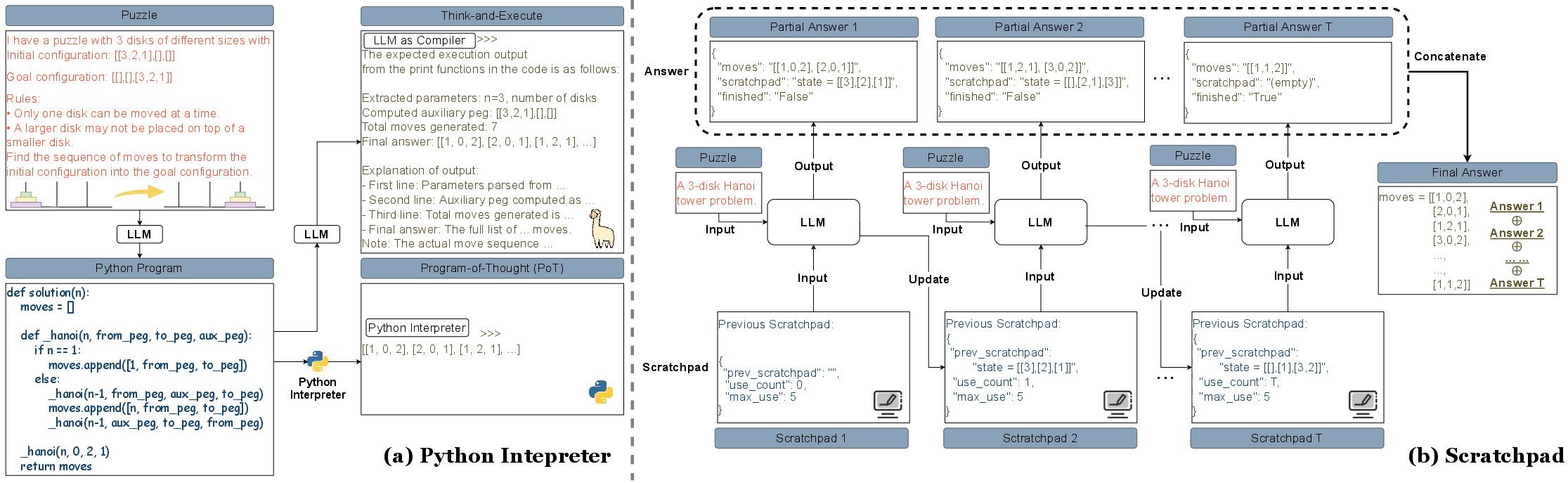
Figure 2: Evaluation Setting of Tool Use.
Results and Discussion
The study found that tool-augmented LRMs consistently outperformed non-reasoning LLMs across various tasks, overturning previous conclusions of negligible LRM advantages. With Python interpreters, for example, DeepSeek-R1 exhibited significant accuracy improvements on River Crossing and Blocks World tasks compared to its non-reasoning variant, DeepSeek-V3.
Task-Specific Observations
- Hanoi Tower: PoT enabled perfect accuracy for both LRMs and LLMs across all task complexities (Table 1).
- Checker Jumping: Both reasoning and non-reasoning models struggled with higher complexity levels, indicating inherent task difficulty.
- River Crossing & Blocks World: LRMs with PoT produced significantly better outcomes, suggesting structured reasoning tasks benefit from external execution capabilities (Tables 2).
Token Consumption and Scratchpad Use
The integration of tools like PoT did not increase token consumption, contrary to expectations. Instead, tools appeared to streamline the reasoning process by guiding models to more efficient pathways, especially noticeable in Qwen 3 Thinking on complex tasks like the Tower of Hanoi (Figures 3-8).
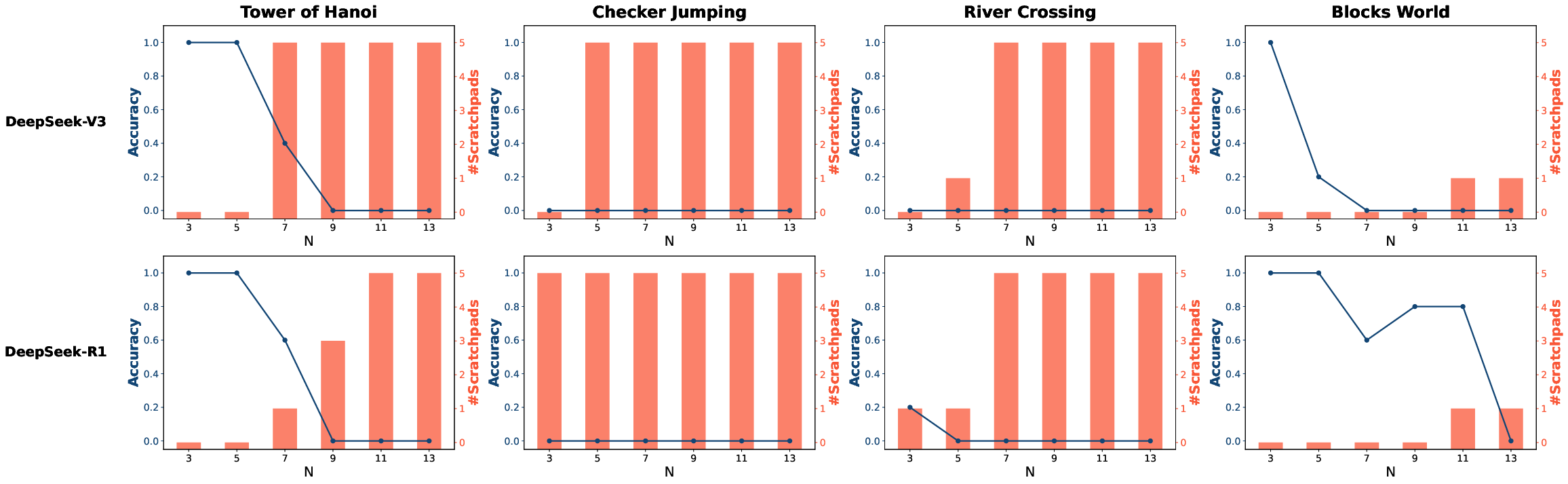
Figure 3: Number of Scratchpads Used on DeepSeek-V3 and DeepSeek-R1.
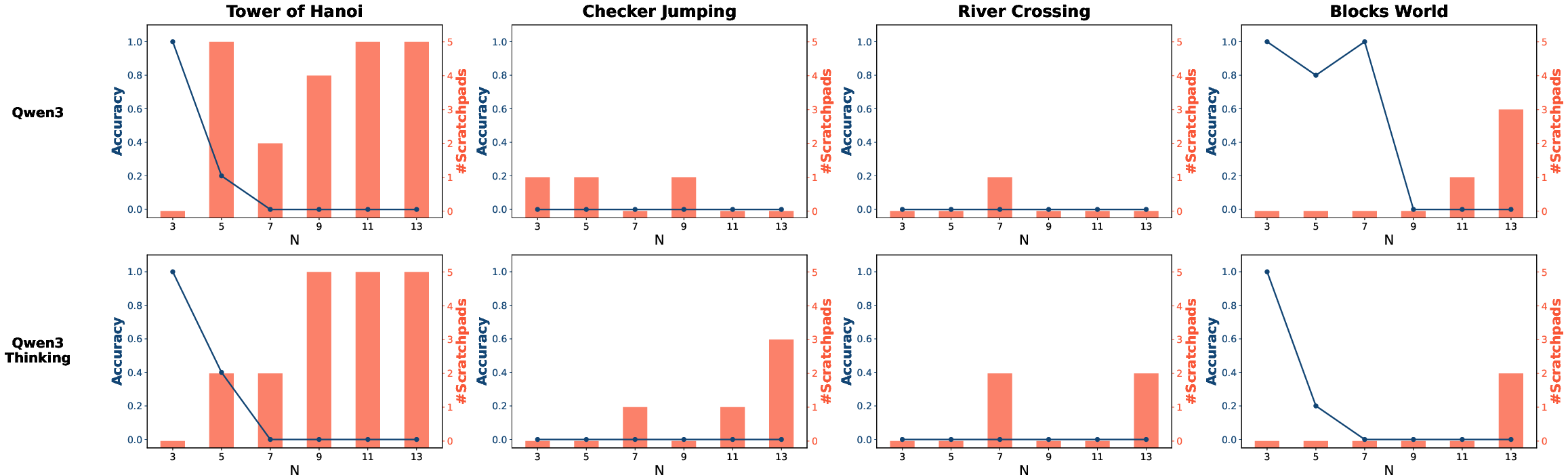
Figure 4: Number of Scratchpads Used on Qwen 3 and Qwen 3 Thinking.

Figure 5: Token Consumption of Qwen 3 Thinking on Tower of Hanoi.
(Figures 6-8)
Figure 6: Token Consumption of Qwen 3 Thinking on Checker Jumping.
Figure 7: Token Consumption of Qwen 3 Thinking on River Crossing.
Figure 8: Token Consumption of Qwen 3 Thinking on Blocks World.
Conclusion
This paper challenges previous assertions about the limitations of LRMs by successfully demonstrating that tool augmentation can unlock significant reasoning capabilities. Moving forward, incorporating more sophisticated tools and environments could further advance the initiatives of reasoning models. Moreover, recognizing the different effectiveness of tools across model architectures and tasks will be vital for future research and practical implementations.

