- The paper introduces a novel CAMPO algorithm that leverages a two-stage training approach combining supervised fine-tuning and reinforcement learning with verifiable rewards for enhanced mathematical reasoning.
- It demonstrates competitive performance on benchmarks like AIME24, AIME25, and MATH500 while optimizing token efficiency through dynamic repetition penalties.
- The research emphasizes transparent data curation and reproducibility, establishing MiroMind-M1 as a robust open-source resource for advanced reasoning language models.
MiroMind-M1: Advancements in Mathematical Reasoning via Context-Aware Multi-Stage Policy Optimization
Introduction
This paper introduces MiroMind-M1, a suite of open-source reasoning LLMs (RLMs) designed to enhance mathematical reasoning capabilities through a transparent and reproducible research paradigm. Built on the Qwen-2.5 backbone, MiroMind-M1 employs a two-stage training protocol: Supervised Fine-Tuning (SFT) using a carefully curated dataset and Reinforcement Learning with Verifiable Rewards (RLVR). Notably, the paper presents a novel algorithm, Context-Aware Multi-Stage Policy Optimization (CAMPO), aimed at optimizing training efficiency and model performance, particularly in generating token-efficient reasoning paths.
Training Methodology
Supervised Fine-Tuning
The SFT phase focuses on leveraging a high-quality dataset comprising 719K mathematical reasoning problems with verified chain-of-thought (CoT) trajectories. This dataset is constructed through rigorous data curation involving de-duplication, decontamination, and difficulty-based pruning.
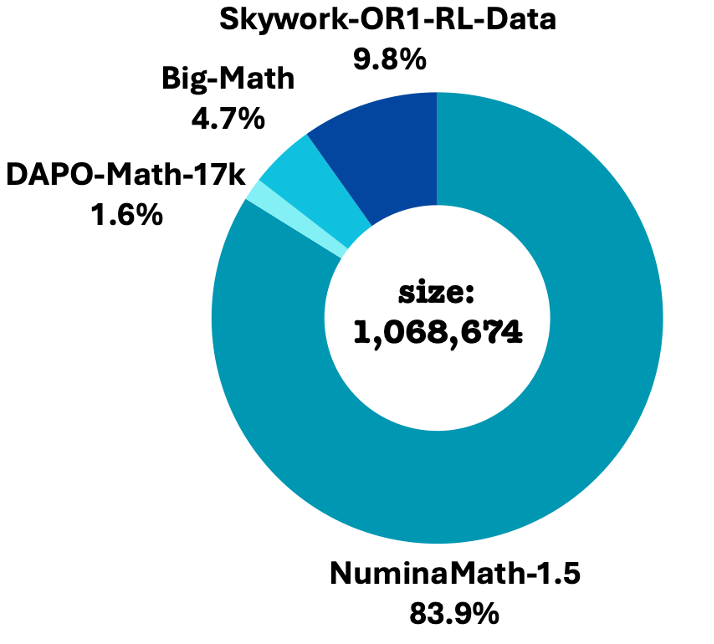
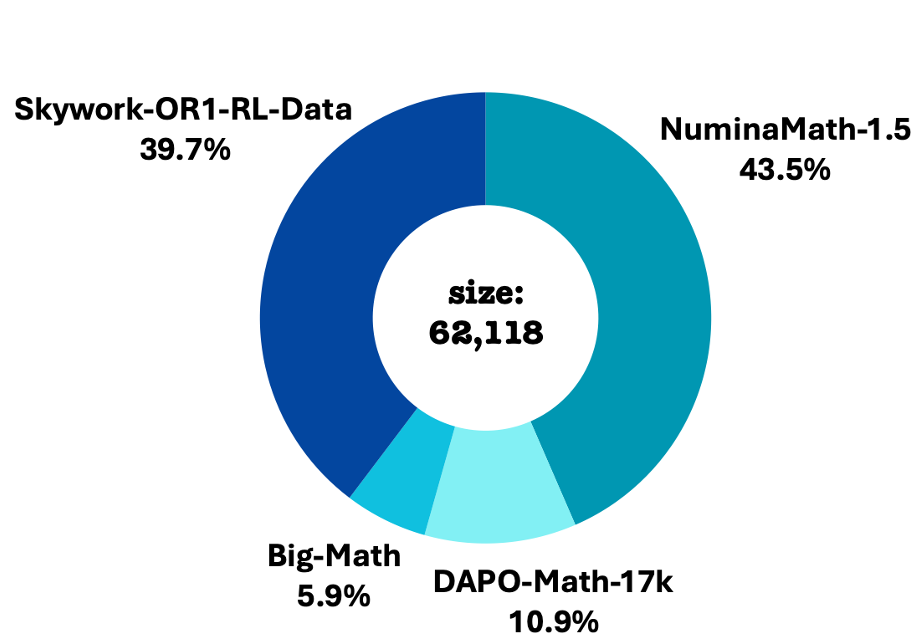
Figure 1: Initial composition distribution. Big-Math comprises HARP and reformulated machine outputs.
Significant emphasis is placed on ensuring the depth and semantic richness of CoT traces, which are critical in enhancing model performance. Training configurations include a peak learning rate of 5.0×10−5, a batch size of 128, and an increased max_position_embeddings limit of 32,768, to accommodate long reasoning sequences.
Reinforcement Learning with CAMPO
The CAMPO algorithm introduces a multi-stage training strategy. Initially, the model is constrained to a shorter maximum response length, progressively increasing during training to accommodate more complex reasoning as it develops.
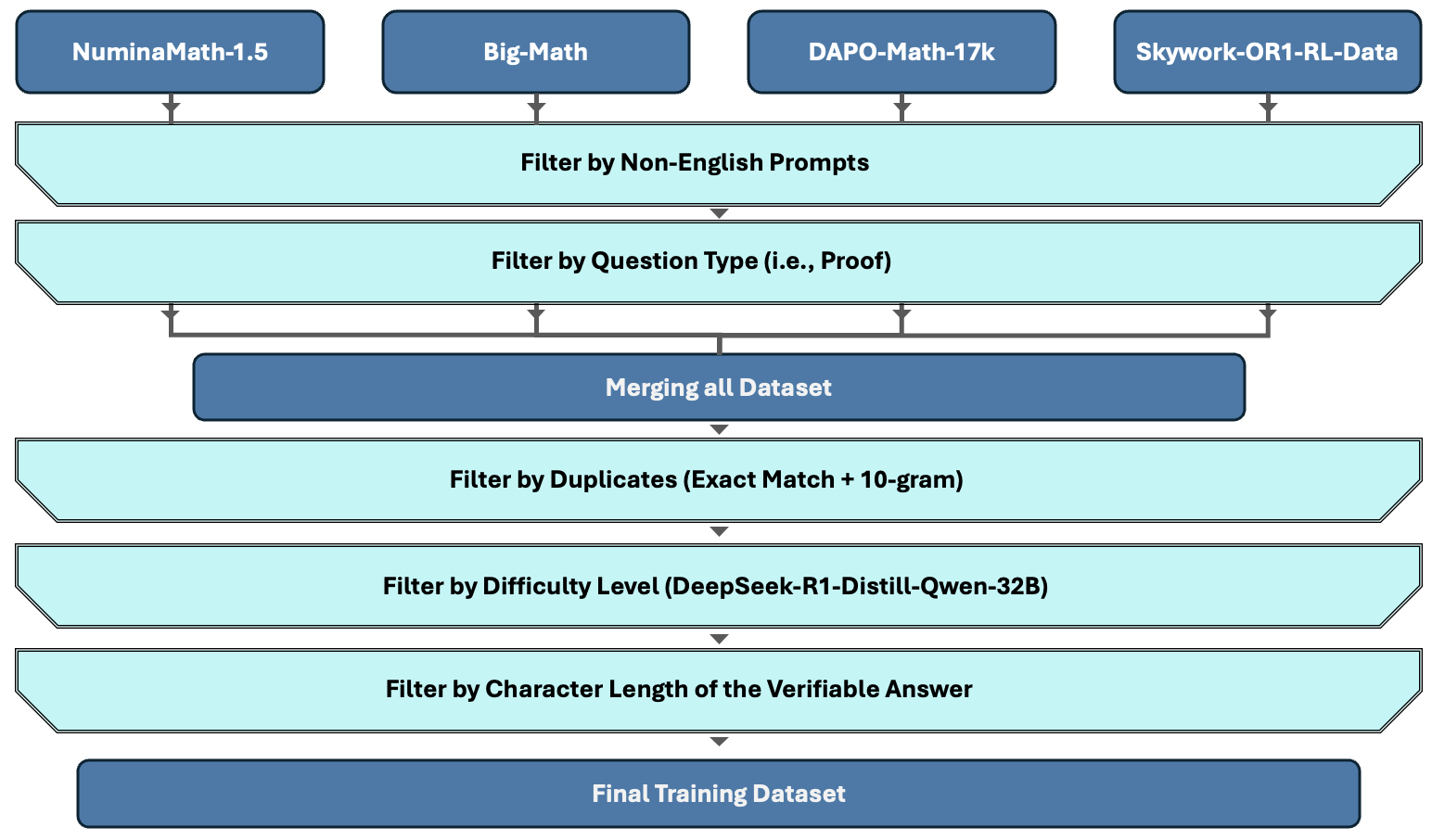
Figure 2: Inclusion-Exclusion Criteria. Overview of the filtering strategy used to construct the final training dataset.
Additionally, a dynamic repetition penalty is implemented to limit redundancy and ensure training stability. This penalty is calibrated by a repetition critic that assesses the occurrence of repeated motifs in the model's output sequence, optimizing for token efficiency without compromising reasoning quality.
Experimental Results
MiroMind-M1 demonstrates state-of-the-art performance against peers, utilizing benchmarks such as AIME24, AIME25, and MATH500 to validate its capability. On the AIME24 test set, the model achieves an accuracy of 77.5, compared to the 77.1 achieved by the Skywork-OR1-32B-Preview model, highlighting competitive advancement in model design.
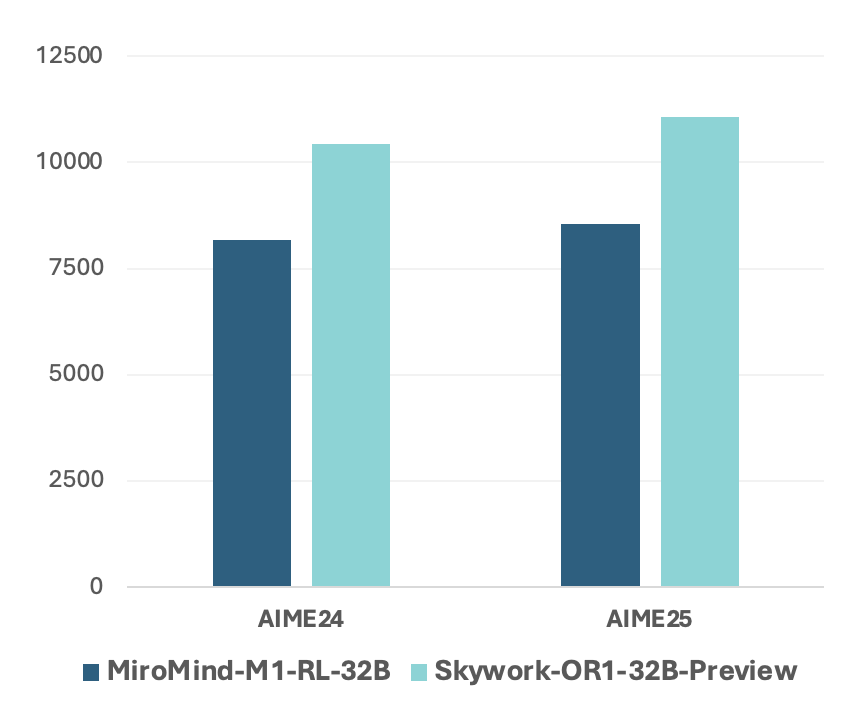
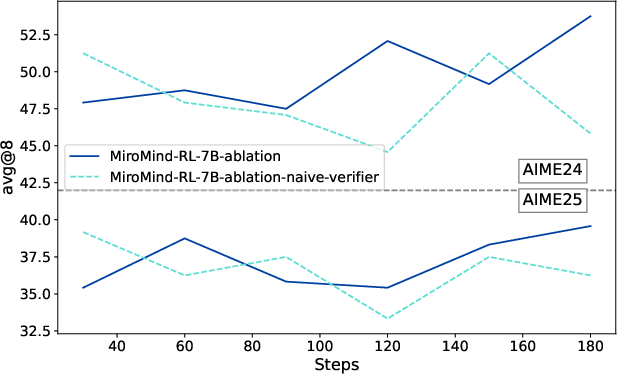
Figure 3: Average token count of model responses conditioned on correct answers.
Moreover, MiroMind-M1 models maintain superior token efficiency, evident from significant performance in environments with constrained token outputs. This efficiency underscores the utility of the CAMPO method in promoting coherent, concise CoT paths.
Comparison with Prior Work
The table below summarizes benchmark performance for 7B and 32B models:
| Model |
AIME24 |
AIME25 |
MATH500 |
| DeepSeek-R1 |
79.8 |
70.0 |
-- |
| MiroMind-M1-RL-32B |
77.5 |
65.6 |
96.4 |
| MiroMind-M1-RL-7B |
73.4 |
57.8 |
96.7 |
MiroMind-M1's performance is competitive with its contemporary, Skywork-OR1-32B-Preview, despite leaning heavily on math-specific training data and without employing additional symbolic reasoning augmentations such as coded examples.
Conclusion
The MiroMind-M1 project provides a robust framework for developing advanced RLMs with a focus on transparency and reproducibility. Through meticulous data curation and the implementation of CAMPO, MiroMind-M1 stands as a resource-efficient and effective mathematical reasoning model. Future research can further enhance this model by integrating broader domain data and optimizing the computational strategies involved in RL training. The project hopes to serve as a foundation for continued exploration and enhancement in reasoning LLMs, particularly in open-source domains.

