- The paper introduces the Re⁴ framework that decomposes scientific computing into rewriting, resolution, review, and revision, enabling robust, bug-free code generation.
- The paper demonstrates method selection improvements via a multi-agent setup, achieving up to 24% increase in execution success rates across PDE benchmarks.
- The paper validates its approach on challenging tasks, including ill-conditioned systems and data-driven physical analysis, ensuring enhanced reliability and accuracy.
Scientific Computing Agents via Rewriting, Resolution, Review, and Revision: The Re⁴ Framework
Introduction and Motivation
The Re⁴ agent framework introduces a multi-LLM collaborative architecture for autonomous scientific computing, targeting the persistent challenges of method selection, bug-free code generation, and solution reliability in LLM-driven code synthesis. The framework decomposes the problem-solving pipeline into four logical stages—rewriting, resolution, review, and revision—each governed by a specialized LLM agent (Consultant, Programmer, Reviewer). This modular design enables explicit knowledge transfer, robust code generation, and iterative self-refinement, addressing the limitations of single-model approaches such as hallucination, method randomness, and low bug-free rates.
Architecture and Workflow
The Re⁴ agent comprises three core modules:
- Consultant: Augments the problem context by integrating domain-specific knowledge and enumerating candidate solution strategies. This module enhances the semantic richness of the input, facilitating downstream reasoning.
- Programmer: Synthesizes and executes Python code based on the Consultant's expanded context or Reviewer feedback. It is responsible for algorithm selection, code structuring, and runtime validation.
- Reviewer: Independently evaluates the Programmer's output, providing detailed feedback on algorithmic correctness, code quality, and runtime anomalies. The Reviewer-Programmer feedback loop enables iterative debugging and refinement.
This multi-agent, multi-model setup supports heterogeneous LLM combinations (e.g., ChatGPT, DeepSeek, Gemini), mitigating single-model failure modes and leveraging complementary strengths in reasoning and context handling.
Experimental Evaluation
PDE Benchmark
The agent was evaluated on a diverse PDE benchmark, including nonlinear, unsteady, and elliptic equations (Burgers, Sod shock tube, Poisson, Helmholtz, Lid-driven cavity, and unsteady Navier-Stokes). The framework demonstrated substantial improvements in code execution success rate and solution accuracy compared to single-model baselines.

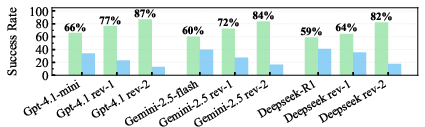
Figure 1: The overall average execution success rate of numerical algorithms employed by Programmers across all equations in the PDEbench.
The Reviewer module increased the execution success rate by up to 24% (e.g., DeepSeek R1: 59%→82%, ChatGPT 4.1-mini: 66%→87%, Gemini-2.5: 60%→84%). The iterative review process consistently reduced L2 relative errors across all equations.


Figure 2: Boxplot of the average L2 relative errors for all equations in the PDEbench. The annotated numbers in the figure denote the average of relative errors.
Best-of-n sampling confirmed that the lowest errors were achieved after two rounds of Reviewer intervention, with the agent reliably selecting high-precision numerical schemes and correcting non-physical solutions.
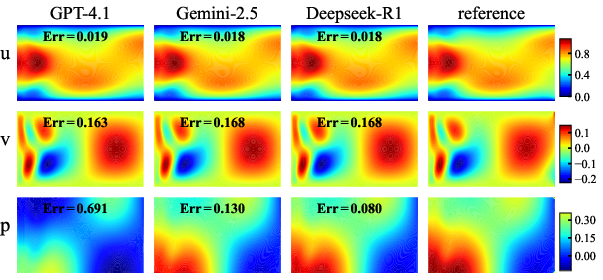
Figure 3: The best runtime outputs of the executable code provided by each Programmer in the final response (review-2).
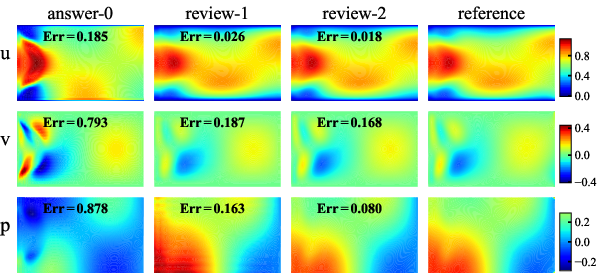
Figure 4: The runtime outputs of the executable code provided by Programmer Deepseek-R1 in the initial response (answer-0), together with those in the Reviewer's first (review-1) and second (review-2) interventions, respectively.
Ill-Conditioned Linear Systems
The agent was tasked with solving Hilbert matrix systems, a canonical example of ill-conditioned problems. The Reviewer module guided the selection of regularization and iterative methods (e.g., Tikhonov, conjugate gradient), resulting in a marked increase in solving success rate and a reduction in L∞ errors.
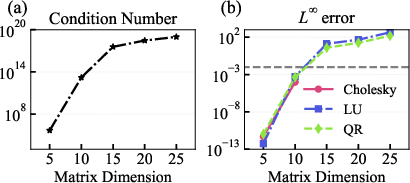
Figure 5: Schematic diagram of (a) variation of the 2-norm condition number with matrix dimension; (b) L∞ error obtained by direct solution using the naive methods.
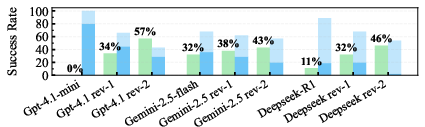
Figure 6: Proportional distribution of executable code provided by Programmers across three different completion statuses.

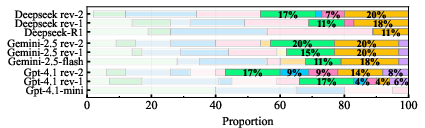
Figure 7: Proportional distribution of completion status for various methods at different response stages. A single dark-colored patch represents SVD method results consistently below the threshold. The color patches corresponding to other methods are divided into three segments, with colors darkening gradually to indicate the following respectively: results contain NaN, exceed L∞ threshold and below L∞ threshold.
GPT-4.1-mini improved from 0% to 57% success rate, Gemini-2.5 from 32% to 43%, and DeepSeek-R1 from 11% to 46%. The Reviewer’s feedback was essential for method selection and parameter tuning, especially in high-dimensional cases.
Data-Driven Physical Analysis
For dimensional analysis in laser-metal interaction, the agent autonomously identified dominant dimensionless quantities (e.g., the keyhole number Ke) from experimental data, enforcing physical constraints and exponent normalization.

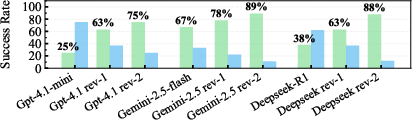
Figure 8: The success rate of Programmers' search algorithms in identifying dominant dimensionless quantities Ke.
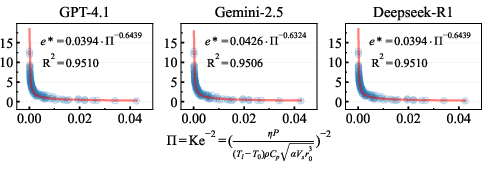
Figure 9: Fitting curve of the dimensionless number Π as a function of e
derived by all programmers in final response (review-2).*
The Reviewer module increased the success rate of discovering physically meaningful dimensionless numbers by up to 50%, ensuring strict compliance with dimensional homogeneity and robust implementation of exponent constraints.
Implementation Considerations
- Prompt Engineering: The framework relies on structured prompt templates for each module, with explicit instructions for context expansion, algorithm selection, code annotation, and feedback incorporation.
- Context Window Management: Long-context scenarios (e.g., large datasets, verbose runtime logs) necessitate prompt truncation and information distillation to avoid LLM output failures.
- Model Selection: The modular design allows for flexible assignment of LLMs to different roles, optimizing for context length, reasoning depth, and response efficiency.
- Iterative Refinement: The feedback loop between Reviewer and Programmer is critical for self-debugging, error correction, and solution enhancement, with each iteration improving reliability and accuracy.
- Execution Success Rate: Percentage of bug-free code and non-NaN solutions.
- Solving Success Rate: Percentage of solutions below error thresholds or correctly identified physical quantities.
- Accuracy: L2 and L∞ relative errors compared to reference solutions.
Implications and Future Directions
The Re⁴ agent framework establishes a robust paradigm for autonomous scientific computing, demonstrating generality across PDEs, linear systems, and data-driven analysis. The multi-agent, multi-model collaboration mitigates hallucination and method selection randomness, while the review mechanism ensures progressive refinement and reliability.
Practical implications include:
- Automated Code Synthesis: Reliable translation of natural language problem descriptions into executable, high-precision scientific code.
- Domain Adaptability: Applicability to diverse scientific domains without domain-specific fine-tuning.
- Scalability: Modular architecture supports parallel evaluation and heterogeneous model integration.
Theoretical implications suggest that structured multi-agent reasoning chains can systematically address the limitations of current LLMs in scientific computing, paving the way for more interpretable and physically grounded algorithm design.
Future work should focus on:
- Quantitative Reviewer Evaluation: Developing more granular and quantifiable review metrics.
- Long-Context Adaptation: Enhancing LLMs or integrating external memory for handling extensive runtime logs and datasets.
- Version Synchronization: Addressing code version lag and integrating up-to-date domain knowledge bases.
Conclusion
The Re⁴ agent framework delivers a reliable, modular, and generalizable solution for autonomous scientific computing, leveraging multi-LLM collaboration and iterative review to achieve high bug-free rates, robust method selection, and superior solution accuracy. Its design and empirical validation establish automatic code generation and review as a promising paradigm for future AI-driven scientific discovery and engineering applications.

