- The paper introduces HeteroScale, a coordinated autoscaling framework for disaggregated LLM inference that dynamically adjusts resource allocation via topology-aware scheduling and key metrics.
- It employs a topology-aware scheduler and metrics-driven policy based on TPS, SM activity, and GPU utilization to optimize performance across heterogeneous hardware.
- In production, HeteroScale increased average GPU utilization by 26.6 percentage points and significantly reduced GPU-hours, demonstrating enhanced operational efficiency.
Taming the Chaos: Coordinated Autoscaling for Heterogeneous and Disaggregated LLM Inference
Introduction
The paper presents HeteroScale, an innovative autoscaling framework tailored for serving LLMs in Prefill-Decode (P/D) disaggregated architectures. Traditional autoscalers face challenges in such settings due to inefficient resource usage on heterogeneous hardware, network bottlenecks, and imbalances between prefill and decode stages. HeteroScale addresses these challenges through a coordinated autoscaling approach that adapts to the specific needs of P/D disaggregation, optimizing both resource utilization and operational costs.
HeteroScale delivers substantial improvements by employing a topology-aware scheduler and a metrics-driven policy born from extensive empirical studies of autoscaling signals in a production environment using tens of thousands of GPUs. The outcome includes a 26.6 percentage point increase in average GPU utilization and significant savings in GPU-hours.
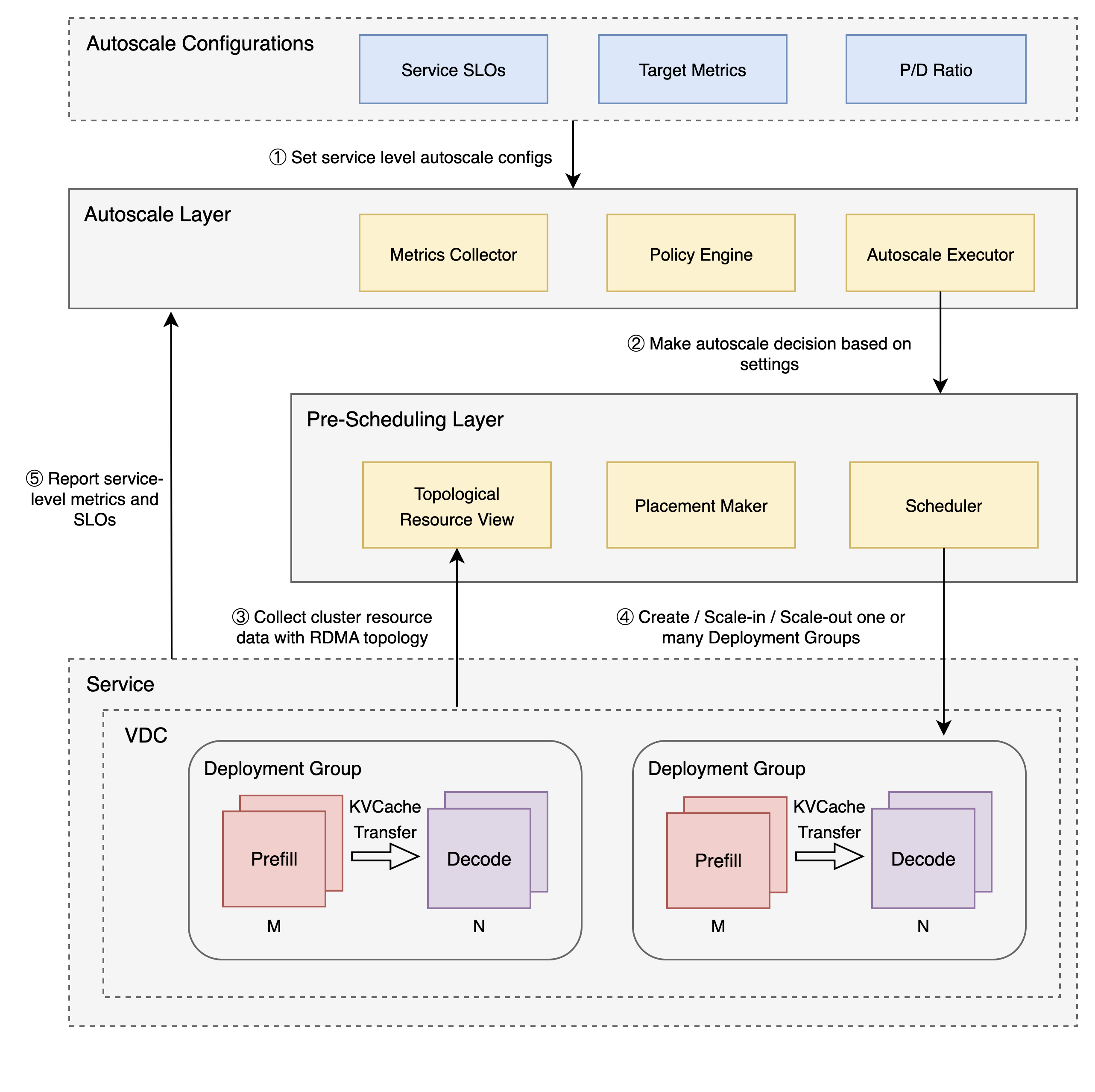
Figure 1: HeteroScale System Architecture.
Background and Motivation
P/D Disaggregated Serving
P/D disaggregation involves separating the compute-intensive prefill phase from the memory-bound decode phase, allowing each to be independently optimized. This separation can lead to enhanced resource utilization but also introduces scaling challenges. Prefill requires powerful compute resources, while decode, being sequential, is less intensive in terms of raw computation but demands high-bandwidth KV cache transfers.
Motivation and Challenges
Deploying in the Seed Serving Platform, HeteroScale confronts several challenges, including ineffective conventional autoscalers, heterogeneous resource management, complex network topology, and metric selection issues. Prefill and decode phases must balance hardware heterogeneity and network affinity constraints to effectively scale capacity and manage resource distribution across different pools.
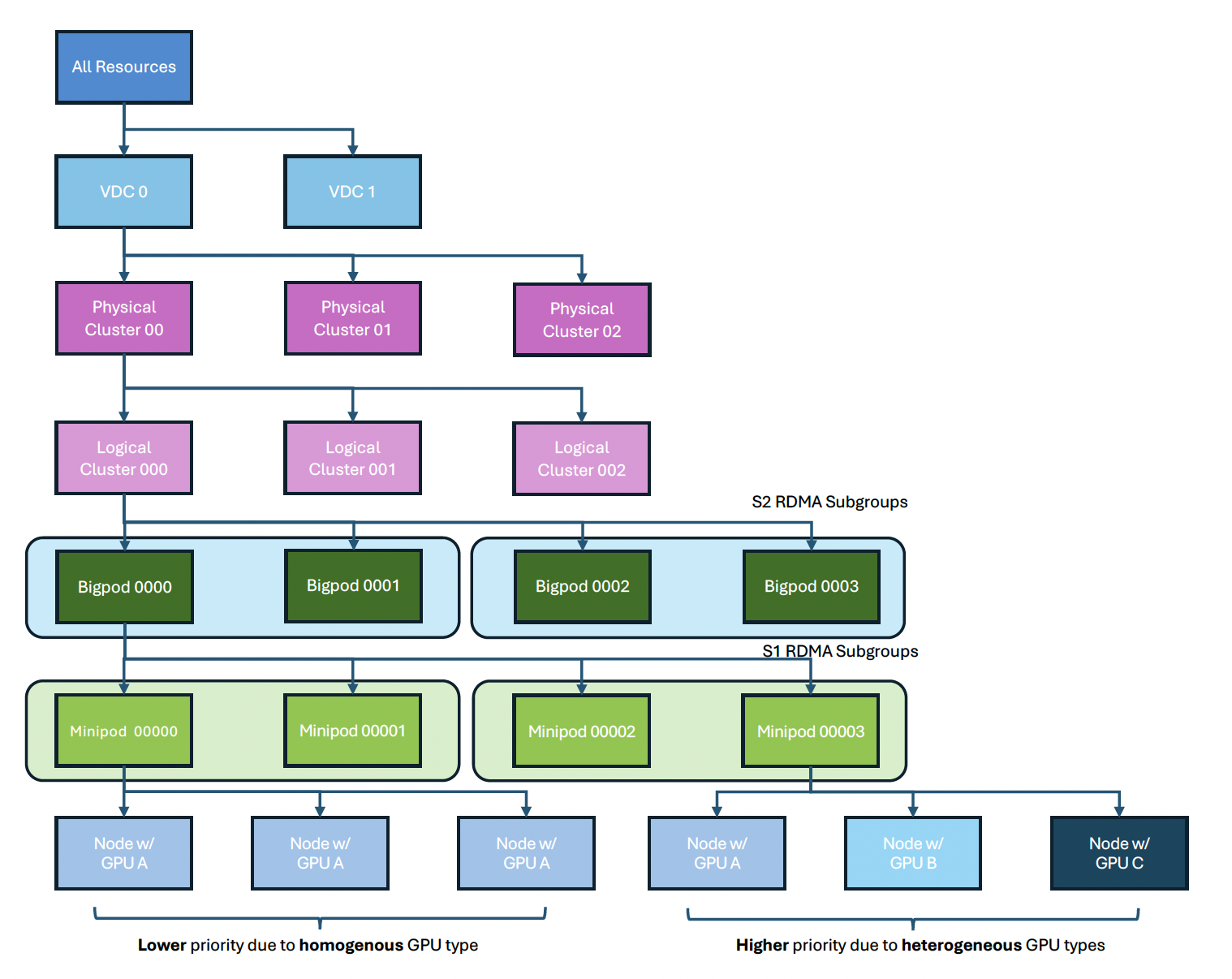
Figure 2: Topological resource tree illustrating the hierarchical organization of resources from data centers (VDCs) down to individual nodes.
System Design
Architecture and Components
HeteroScale is structured into several layers: the autoscaling layer with a policy engine, federated pre-scheduling, and sub-cluster scheduling layers. The design ensures resource-efficient scaling decisions by examining various operational metrics, aligning resource allocation and scaling decisions with workload requirements.
Scaling Policies
The policy engine is pivotal, facilitating real-time and periodic scaling based on workload conditions. It employs throughput (TPS), SM activity, and GPU utilization as the core metrics. Decoding TPS was identified as a robust signal for guiding scale decisions due to consistent behavior across diverse workloads and hardware configurations.
Topology-Aware Scheduling
Deployment Group abstraction maintains network affinity by strategically co-locating prefill and decode instances, hence minimizing latency from KV cache transfers and optimizing scarce high-performance hardware through RDMA subgroups.
Evaluation
Metrics Analysis
Eight scaling metrics were analyzed under simulated workload conditions. TPS emerged as responsive and reliable, aligning with real-world signal-to-noise ratios and enabling effective autoscaling.
Production Deployment Impact
In production, HeteroScale efficiently scaled resources across thousands of GPUs, raising average GPU utilization and SM activity significantly. Figure 3 highlights performance metrics under TPS-based autoscaling, showcasing improved stability and resource savings.
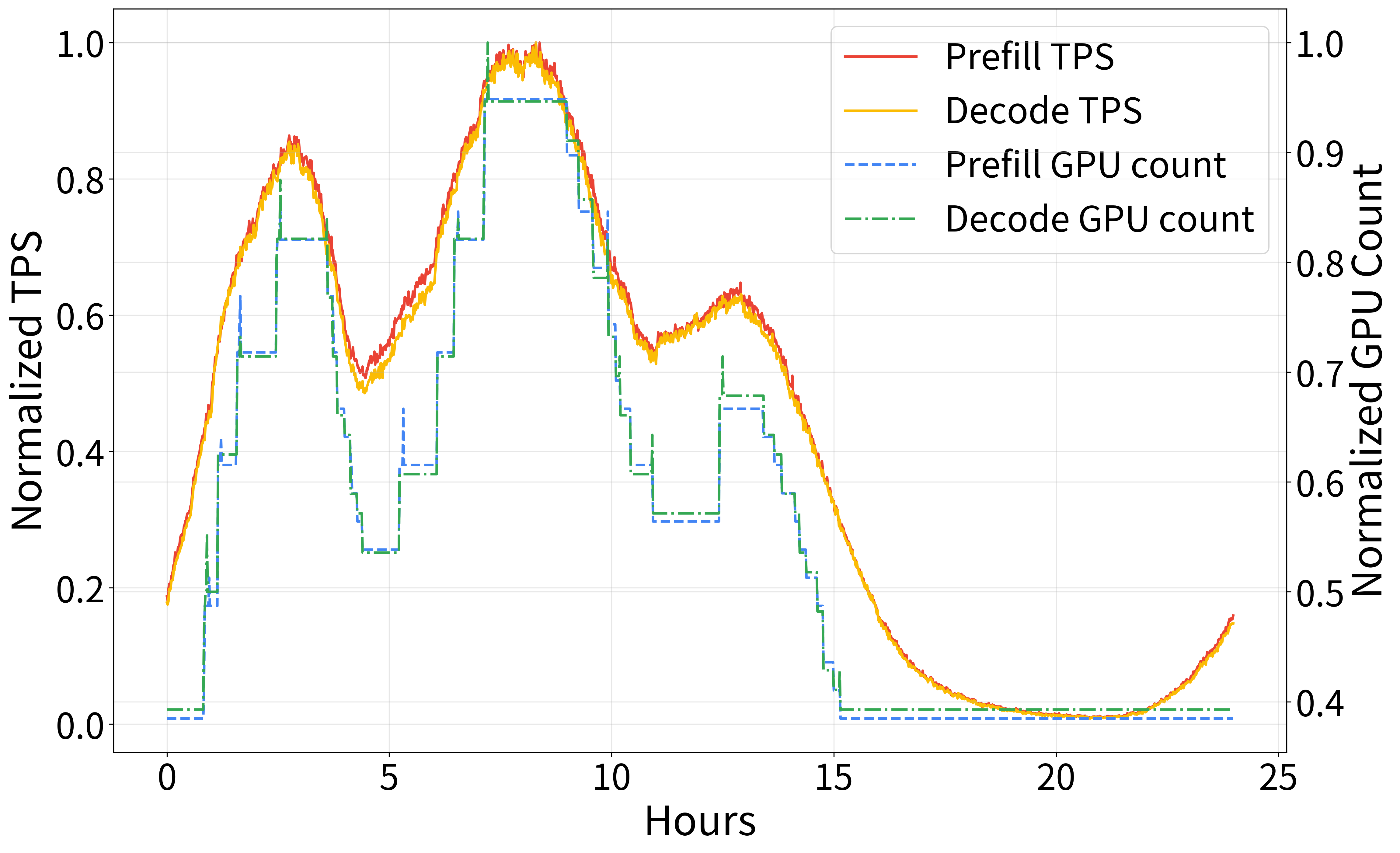
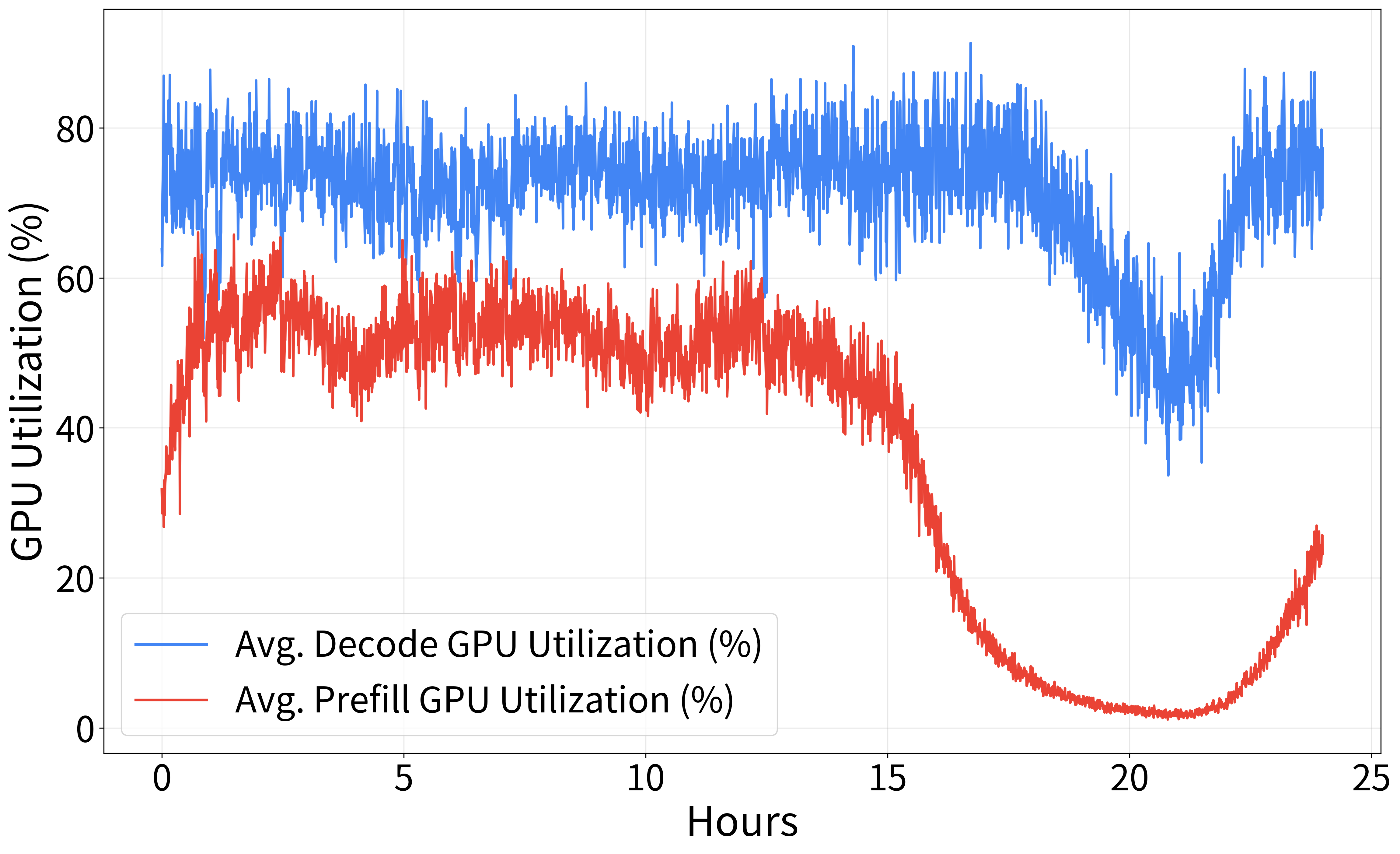
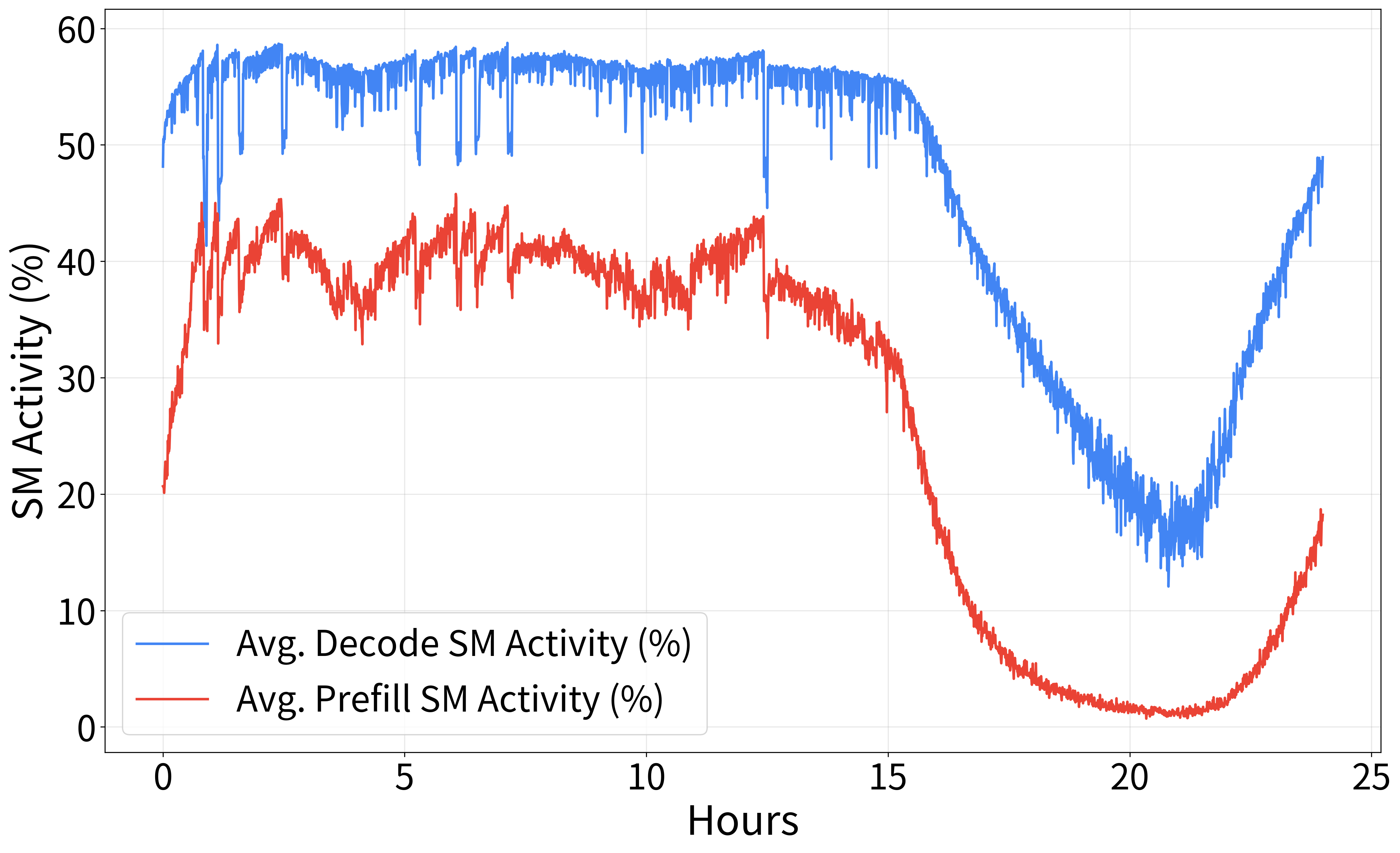
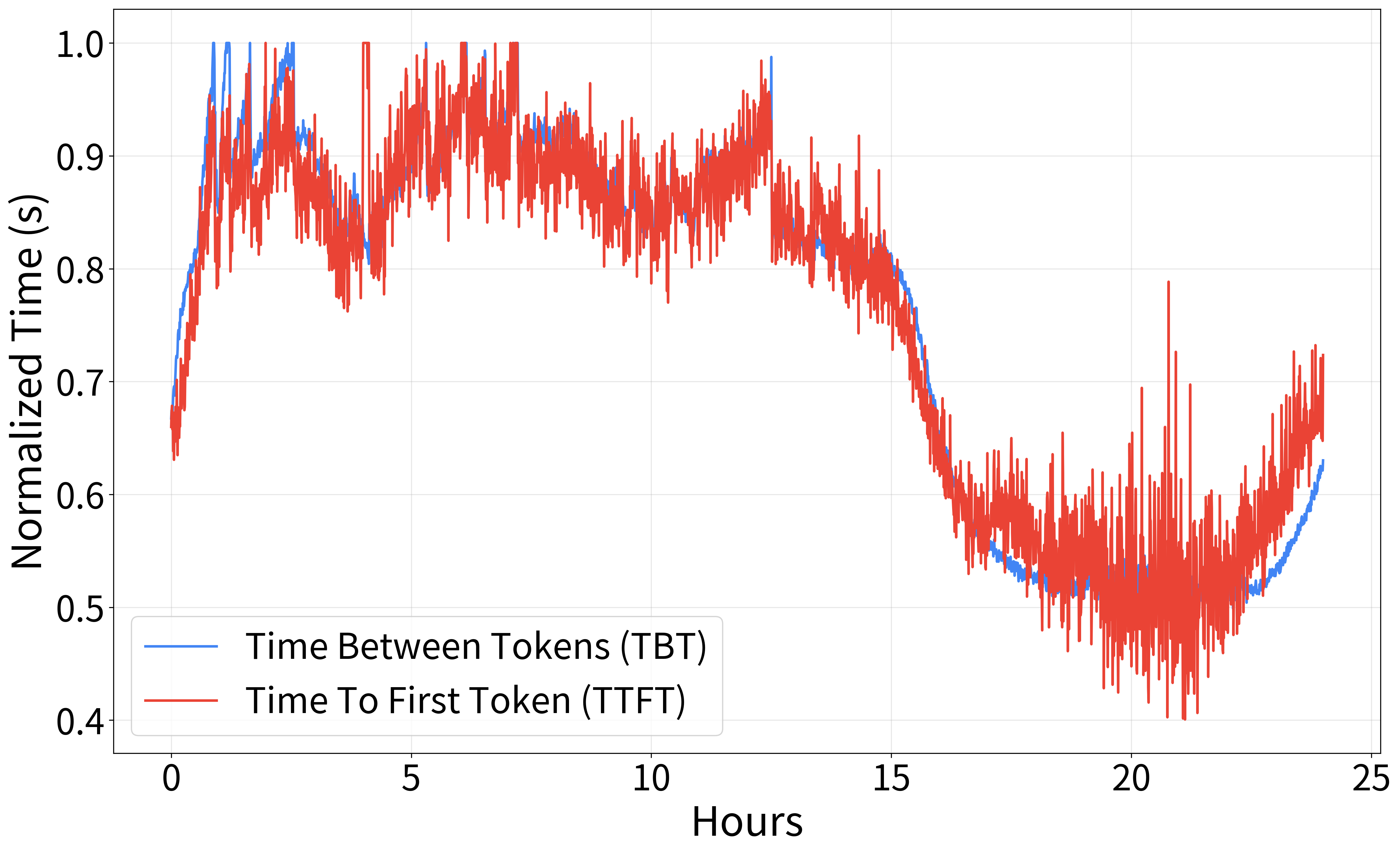
Figure 3: Production environment: Performance metrics of an open-domain dialogue service with TPS-based autoscaling.
The paper situates HeteroScale within existing LLM serving systems and autoscaling technologies, highlighting its unique contributions in heterogeneous resource management and network-aware scheduling in comparison to other frameworks such as Kubernetes HPA, Autoscale, and various deep learning schedulers.
Conclusion
HeteroScale represents a significant advancement for the deployment of large-scale LLM serving platforms, particularly in P/D disaggregated settings. Its topology-aware and metric-driven innovations offer substantial efficiency improvements while maintaining stringent service-level objectives, exemplifying its capability as a benchmark for future scalable LLM infrastructures. Future work will involve exploring dynamic P/D ratio adaptation and cache-aware scaling strategies to further enhance the autoscaling efficiency and robustness.

