- The paper proposes a novel attention disaggregation mechanism that offloads computation from decoding to prefill phases, optimizing GPU resource utilization.
- It integrates low-latency decoding synchronization, dynamic resource partitioning, and load-aware scheduling to increase throughput and reduce latency.
- Evaluation on Llama-2 models demonstrates up to a 1.68x boost in inference throughput with significantly improved memory and bandwidth usage.
Injecting Adrenaline into LLM Serving: Boosting Resource Utilization and Throughput via Attention Disaggregation
Introduction
The paper "Injecting Adrenaline into LLM Serving: Boosting Resource Utilization and Throughput via Attention Disaggregation" addresses the inefficiencies in LLM serving systems, particularly focusing on the dichotomous nature of prefill and decoding phases. Current systems often employ a prefill-decoding disaggregation technique to handle these phases on separate machines. However, this strategy suffers from poor resource utilization, as prefill phases have low memory utilization while decoding phases struggle with compute utilization. To tackle these inefficiencies, the authors propose "Adrenaline," a novel attention disaggregation mechanism designed to enhance resource utilization and performance.
Problem Statement
In LLM serving environments, the execution of user queries involves compute-intensive prefill and memory-intensive decoding phases. Traditional serving systems physically separate these phases to minimize interference but end up with significant resource underutilization. Prefill instances show low memory usage, while decoding instances under-utilize computational resources. This not only increases latency but also elevates the operational costs associated with GPU usage.
Adrenaline's Design and Implementation
Adrenaline improves GPU resource utilization by disaggregating part of the attention computation from the decoding phase and offloading it to prefill instances. This method increases memory and bandwidth usage in prefill instances and boosts compute utilization in decoding instances, achieved through three core techniques:
- Low-latency Decoding Synchronization: This technique reduces the overhead associated with synchronizing between offloaded and local attention computations. It employs CUDA graph technology to manage and minimize kernel-launching overheads, ultimately shortening the execution path and enhancing performance synchronization.

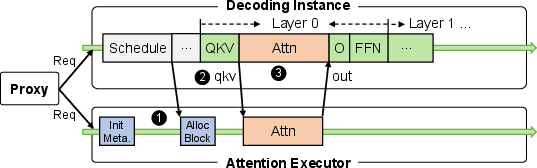
Figure 1: A comparison of decoding workflows with and without low-latency attention offloading.
- Resource-efficient Prefill Colocation: Adrenaline employs a mechanism to partition GPU resources flexibly, allowing efficient prefill and attention computations within the same hardware. This approach leverages NVIDIA's MPS technology to optimize resource allocation dynamically, based on offline profiling data to avoid runtime interference.
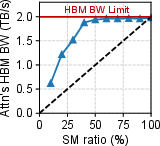
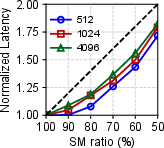
Figure 2: The impact of varying SM allocations on the bandwidth use of memory-intensive attention tasks.
- Load-aware Offloading Scheduling: A global scheduler located in the proxy manages offloading rates adaptively, based on the real-time load of the server. This scheduler uses runtime metadata to optimize load distribution dynamically across available resources.
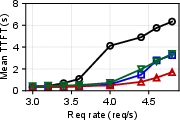
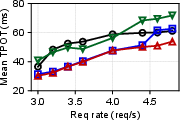
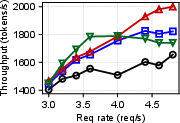
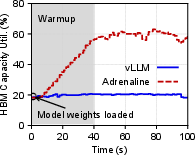
Figure 3: Performance impact of various offloading ratios with ShareGPT and Llama-2 models.
Evaluation and Results
The evaluation on Adrenaline using the Llama-2 models against benchmarks such as ShareGPT and OpenThoughts highlights its efficacy.
- Resource Utilization: Adrenaline increased HBM memory utilization by 2.28 times in prefill instances and nearly doubled bandwidth use, addressing underutilization issues compared to existing PD systems.
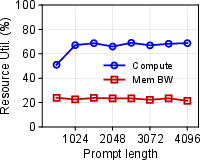
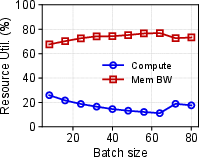
Figure 4: Resource utilization in disaggregated prefill and decoding phases under Adrenaline.
- Performance Metrics: In field scenarios, Adrenaline achieved up to a 1.68 times increase in overall inference throughput without compromising the service-level objectives (SLOs), such as time to first token (TTFT) and time per output token (TPOT).
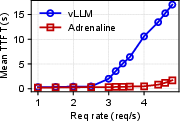
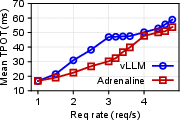
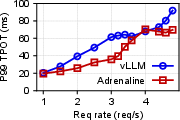
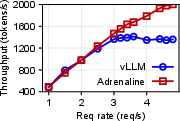
Figure 5: The E2E performance of ShareGPT with Adrenaline, highlighting improvements in output throughput and latency metrics.
Conclusion
Adrenaline significantly enhances the deployment efficiency of LLM serving systems by optimizing resource utilization through innovative strategies for attention offloading and synchronization. The proposed methodologies demonstrate increased throughput and reduced latency, offering a promising direction for future improvements in AI-driven services. By implementing Adrenaline, it is feasible to achieve better service performance and reduced infrastructure costs, and its adaptive scheduling paves the way for flexible, scalable high-performance LLM inference services. Future work could integrate similar disaggregation strategies to other components of LLM serving infrastructures to further enhance their operational efficiency.