- The paper introduces DistillPrompt, a novel autoprompting method that optimizes prompts for LLMs without altering model parameters.
- It employs a multi-stage process—integrating distillation, compression, and aggregation—to achieve a 20.12% improvement over baseline autoprompting methods.
- The approach enhances various NLP tasks by improving macro F1-score and METEOR metrics, demonstrating its efficacy and potential in prompt optimization research.
Automatic Prompt Optimization with Prompt Distillation
Introduction
The paper "Automatic Prompt Optimization with Prompt Distillation" (2508.18992) introduces a novel autoprompting method called DistillPrompt. This method is designed for optimizing prompts for LLMs without altering the model parameters. Autoprompting, a key aspect of this work, automates the selection of prompts, a process that traditionally demands significant manual effort and expertise in prompt engineering. The paper underscores the increasing complexity of manual prompt engineering amid the growing diversity of prompting techniques.
DistillPrompt Methodology
DistillPrompt leverages a multi-stage process integrating task-specific data into prompts, utilizing operations such as distillation, compression, and aggregation. The method draws inspiration from the Tree-of-Thoughts prompting technique, emphasizing the exploration of prompt space to avoid local optima. Each iteration in DistillPrompt involves generating prompt variations, embedding task-specific examples, compressing instructions, aggregating candidates, and refining prompts (Figure 1).
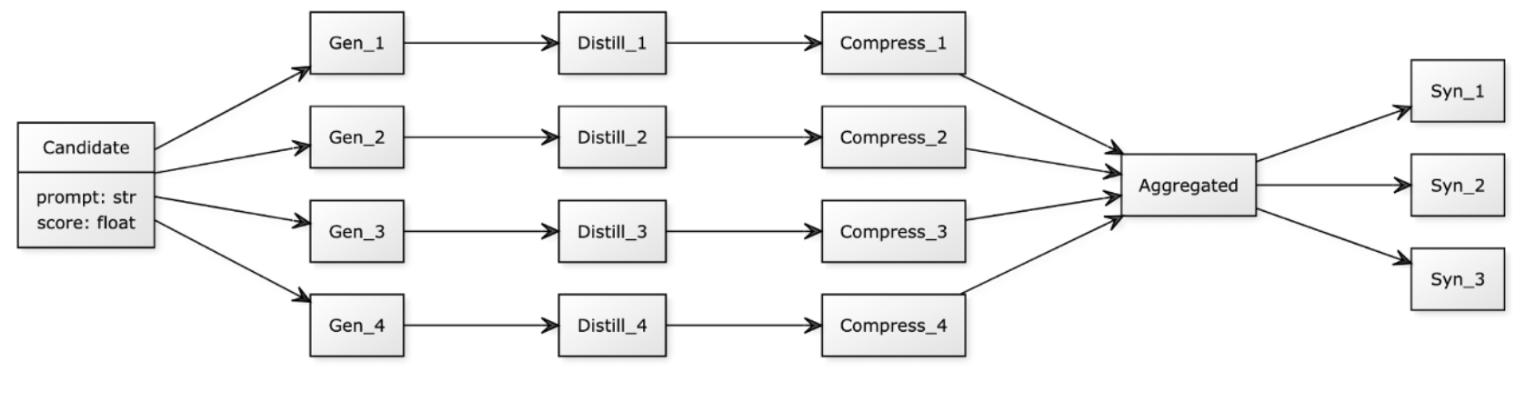
Figure 1: Workflow of DistillPrompt.
Non-Gradient Autoprompting
The study contrasts DistillPrompt with existing non-gradient methods, highlighting their limitations such as limited prompt manipulation and narrow task applicability. By addressing these issues, DistillPrompt offers a more structured and generalizable approach. The method's design emphasizes semantic diversity and task alignment, avoiding the computational overhead associated with gradient-based prompt optimization.
Experimental Evaluation
The effectiveness of DistillPrompt was tested using the t-lite-instruct-0.1 LLM across various datasets involving classification and generation tasks. Key classification datasets included SST-2, MNLI, and MedQA, while generation tasks were tested with datasets like GSM8K and SAMSum. The evaluation metrics used were macro F1-score for classification and METEOR for text generation tasks.
The experimental results indicate significant improvements in performance with DistillPrompt compared to baseline prompting and existing autodrafted methods like Grips and Protegi. For instance, DistillPrompt achieved a 20.12% average improvement over Grips across evaluated tasks, demonstrating superior capacity in prompt space exploration.
Discussion
DistillPrompt's framework allows it to effectively handle diverse NLP tasks, showcasing its superiority over other non-gradient autoprompting methods. The results reveal a substantial increase in average F1-scores and METEOR scores compared to other methods, highlighting its efficacy in both classification and generation tasks. DistillPrompt's success paves the way for future exploration in prompt distillation and non-gradient autogeneration methods, hinting at further possibilities for refinement and adaptation to other approaches.
Conclusion
By introducing a comprehensive distillation approach for prompt optimization, DistillPrompt sets a benchmark in non-gradient autoprompting methods. Its application across various datasets demonstrates consistent improvements in NLP tasks, underscoring the potential of prompt distillation as a foundational technique in automated prompt engineering. DistillPrompt's advances suggest profound impacts on the future landscape of AI LLM applications, with significant implications for both research and practical deployment in LLM-driven tasks.