- The paper demonstrates that simple Majority Voting can match or exceed the performance of complex debate mechanisms, challenging prior assumptions.
- It introduces a Bayesian belief update framework using the Dirichlet-Compound-Multinomial distribution to model agent uncertainty in debates.
- Empirical results over seven NLP benchmarks show that increasing the number of agents boosts performance, emphasizing the power of ensemble methods.
Exploring Multi-Agent Decision Making: Voting vs. Debate in LLMs
Introduction
The concept of using multiple agents to engage in structured interactions has been prevalent in many fields, and has recently gained attention in improving the performance of LLMs. The Multi-Agent Debate (MAD) paradigm has emerged as a potential approach for enhancing LLMs' capabilities by enabling structured discussions among multiple agents. This paper, titled "Debate or Vote: Which Yields Better Decisions in Multi-Agent LLMs?" (2508.17536), examines the efficacy of MAD by analyzing its two fundamental components: Majority Voting and inter-agent Debate.
Key Findings
The research demonstrates through extensive experiments that Majority Voting alone can account for a significant portion of the performance gains attributed to MAD. This challenges prior assumptions that complex inter-agent communication in MAD is the primary driver of improved performance. The paper spans multiple benchmark tests across various tasks, providing a comprehensive evaluation of these two components.
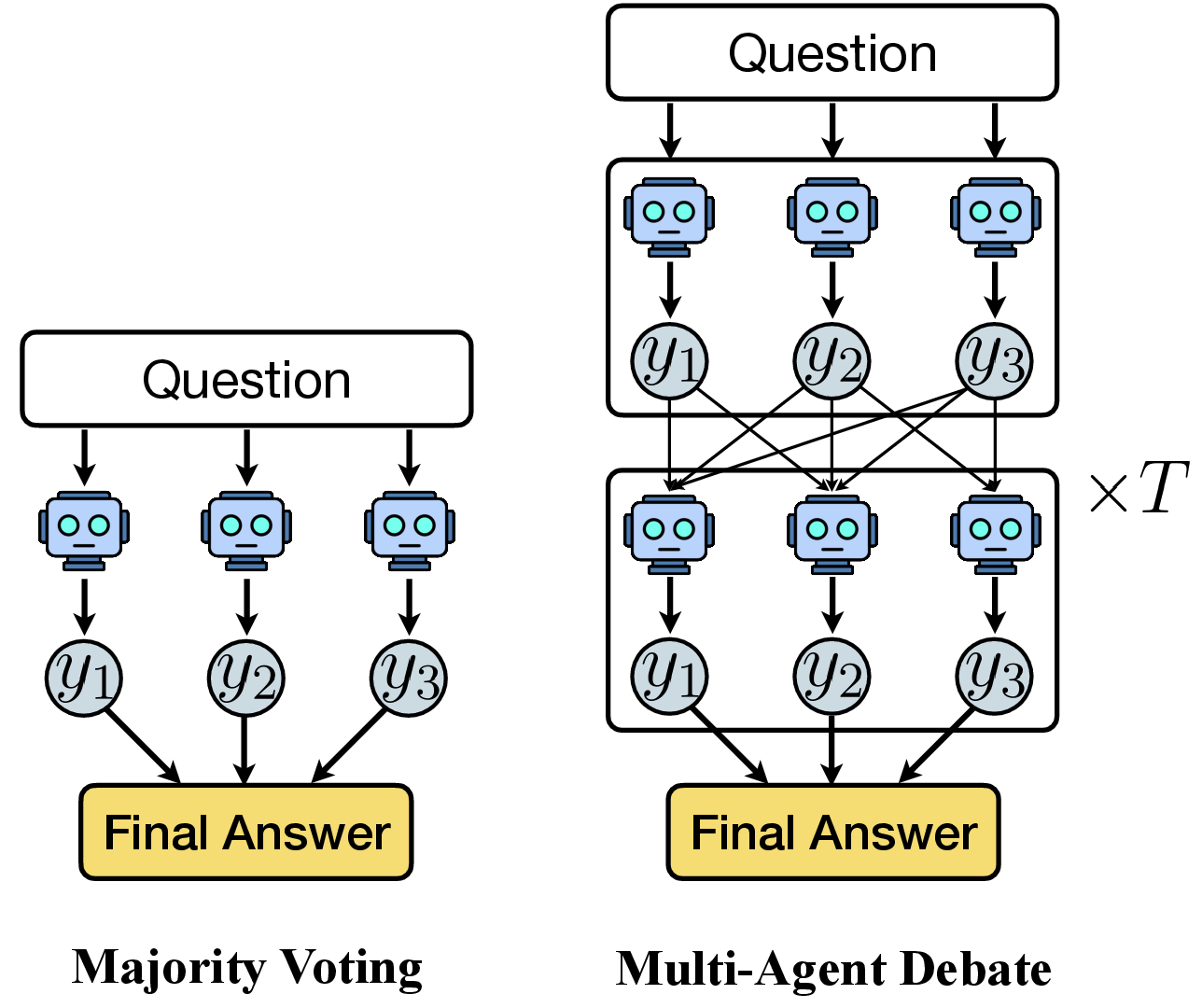
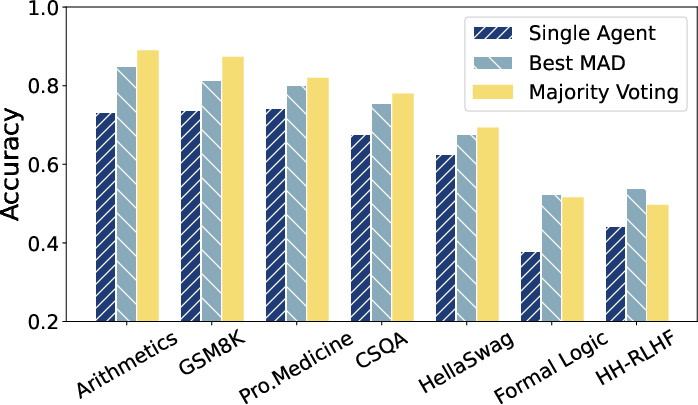
Figure 1: Majority Voting vs. MAD overview.
Theoretical insights reveal that debate, modeled as a stochastic process, constructs a martingale over agents' belief trajectories, indicating that the debate itself does not improve expected correctness. This implies that the popular MAD paradigms may not necessarily enhance model reasoning as previously thought, and highlights the substantial role of simple ensembling methods.
Theoretical Contributions
To elucidate these findings, the authors develop a theoretical framework that frames the debate process in multi-agent settings as a Bayesian belief update mechanism. The framework characterizes MAD as a martingale process in the belief update sequence, suggesting that without intervention, debate alone does not enhance correctness on average.
By focusing on the Dirichlet-Compound-Multinomial (DCM) distribution, the authors effectively capture how agent uncertainty and belief update dynamics operate during debate rounds. This rigorous approach demonstrates that while stochastic interactions among agents influence belief trajectories, they do not inherently improve the expected level of correctness without additional bias towards the correct answer.
Empirical Results
The empirical evaluation conducted across seven NLP benchmarks supports the theoretical insights by illustrating that the majority voting mechanism consistently matches or exceeds the performance of MAD across diverse linguistic tasks. This aligns with the observation that major performance benefits arise primarily from aggregating diverse outputs rather than relying on complex inter-agent communication.
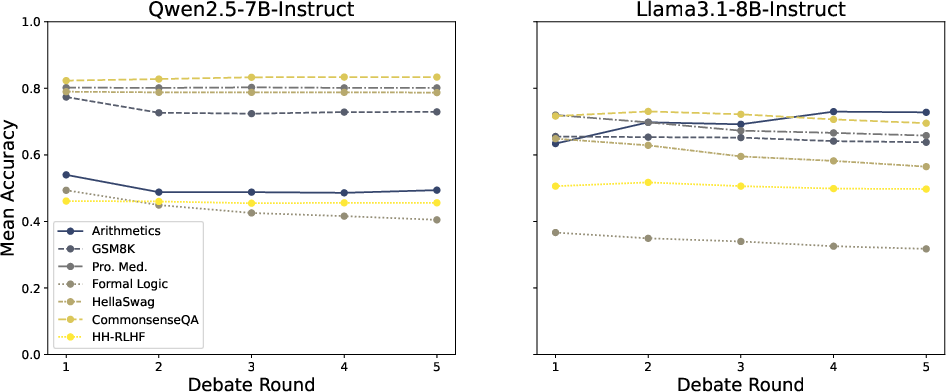
Figure 2: Martingale process of the mean agent accuracy across debate rounds.
Interestingly, the results reveal that as the number of agents increases, so too does the performance, further reinforcing the strong influence of ensembling in improving outcomes compared to sophisticated debate protocols.
Implications and Future Directions
The paper challenges the necessity of multi-agent debate frameworks by showing that simpler methods such as Majority Voting can achieve similar—if not superior—results under many circumstances. The implications for AI system design are profound: embracing simpler, more computationally efficient techniques could lead to more scalable and reliable AI applications.
Future research could explore ways to enhance MAD effectiveness through informed interventions that bias debate processes towards correctness, potentially using design strategies that modulate influence during inter-agent dialogue. Expanding theoretical models to include heterogeneous agent configurations is another promising direction. Additionally, exploring various debate formats beyond simultaneous communication could provide further insights into optimizing multi-agent AI strategies.
Conclusion
In summary, "Debate or Vote: Which Yields Better Decisions in Multi-Agent LLMs?" presents a compelling case for re-evaluating the necessity of complex multi-agent debate systems in favor of simpler ensemble methods like Majority Voting. Through rigorous theoretical development and comprehensive empirical analysis, the paper underscores the potential of leveraging simple yet robust techniques to achieve significant performance improvements in multi-agent LLMs.
