- The paper introduces RuscaRL, a rubric-scaffolded reinforcement learning framework that enhances LLM reasoning by guiding exploration.
- It employs explicit scaffolding and a verifiable reward system to balance exploration and exploitation, leading to faster model convergence.
- Experimental results on benchmarks like HealthBench-500 show significant performance gains over traditional LLM approaches.
Breaking the Exploration Bottleneck: Rubric-Scaffolded Reinforcement Learning for General LLM Reasoning
The paper "Breaking the Exploration Bottleneck: Rubric-Scaffolded Reinforcement Learning for General LLM Reasoning" presents RuscaRL, a novel framework aimed at enhancing the reasoning capability of LLMs by breaking the exploration bottleneck inherent in traditional reinforcement learning approaches. RuscaRL integrates instructional scaffolding into the reinforcement learning paradigm, utilizing checklist-style rubrics to guide exploration and exploitation phases.
Introduction to RuscaRL
RuscaRL is designed to address a critical limitation faced by reinforcement learning in LLMs—namely, the dependence on high-quality samples which are difficult to explore due to the inherent limitations of the models themselves. By introducing rubrics as an external scaffolding mechanism, the model can generate diverse and high-quality responses during the rollout phase, while rubrics also serve as verifiable rewards during training, encouraging effective learning on reasoning tasks.
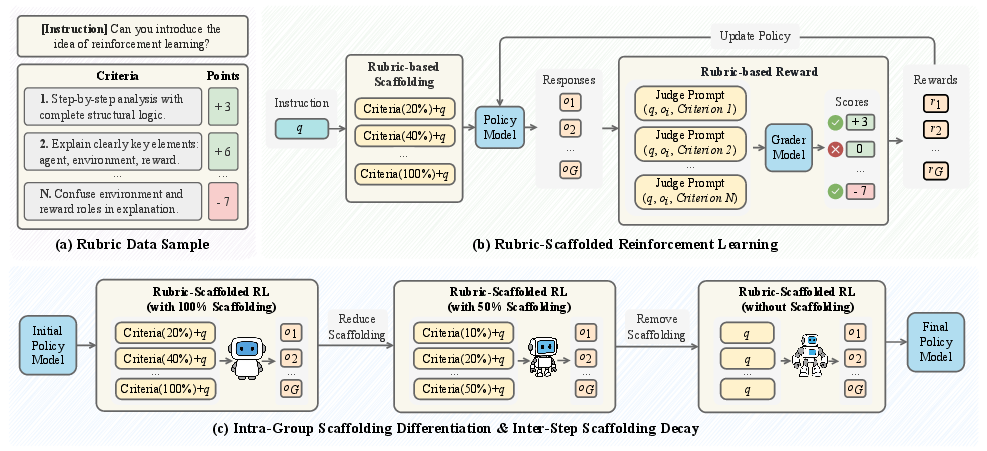
Figure 1: Overview of the RuscaRL framework: (a) Rubric data sample with criteria and points, (b) Rubric-scaffolded reinforcement learning with reward computation and policy updates, (c) Intra-group scaffolding differentiation and inter-step scaffolding decay mechanisms.
Methodology
RuscaRL utilizes a dual approach to integrate rubric-based scaffolding:
- Explicit Scaffolding: During rollout generation, rubrics guide response generation by providing external task instructions with varying levels of detail through intra-group differentiation. Inter-step scaffolding decay then gradually reduces reliance on this external guidance, encouraging the model to internalize the reasoning processes.
- Verifiable Reward System: The rubric-based reward mechanism employs an LLM as a grader to assess responses using checklists that capture multiple aspects of solution quality. This approach provides robust feedback signals suitable for complex reasoning tasks which lack a single verifiable answer.
Implementation Details
RuscaRL employs Group Relative Policy Optimization (GRPO) as its core RL algorithm to train LLMs using rubric-based rewards. The advantage of GRPO lies in its ability to eliminate the need for a value model by leveraging group-based advantage estimation, optimizing policy updates through a structured exploration of diverse high-reward responses.
To manage the exploration-exploitation trade-off, RuscaRL's scaffolding decay is controlled using a sigmoid function, which dynamically adjusts the scaffolding intensity based on training progression. This ensures that the model does not overfit due to prolonged scaffolding dependence and encourages the exploration of novel trajectories.
Experimental Results
RuscaRL demonstrates strong empirical performance across various benchmarks, significantly enhancing models like Qwen2.5-7B-Instruct and Qwen3-30B-A3B-Instruct. On HealthBench-500, RuscaRL achieves a marked improvement over baseline models, outperforming industry-leading LLMs such as OpenAI's counterparts.
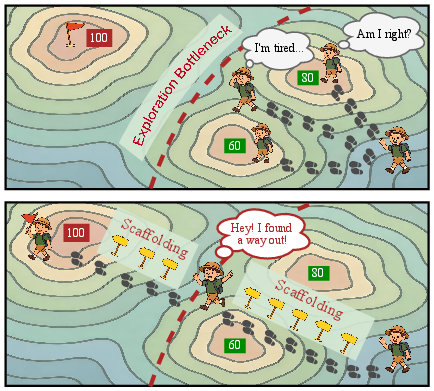
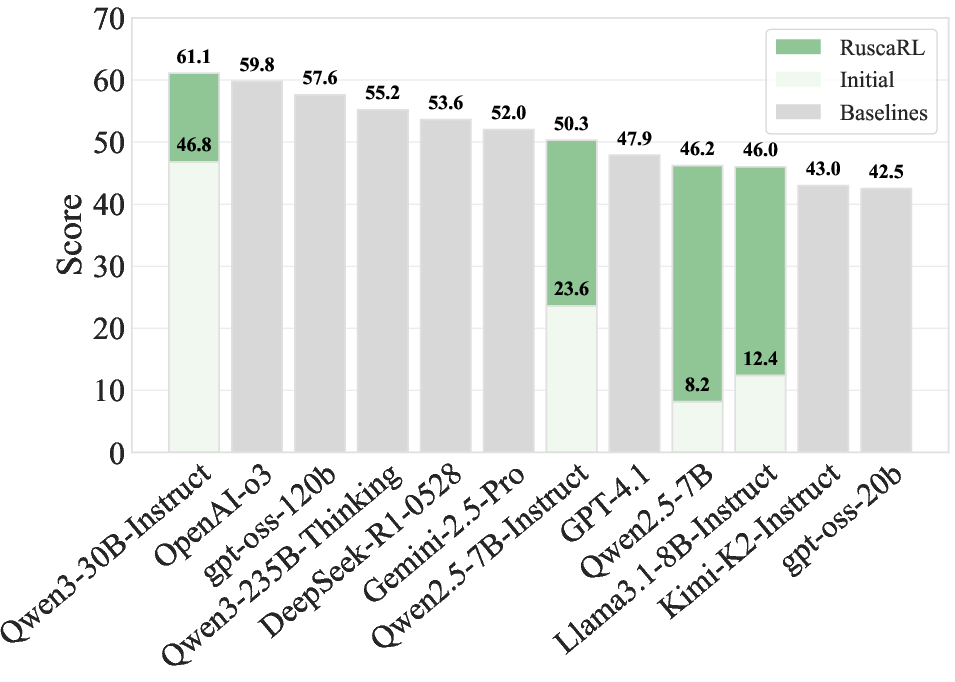
Figure 2: (Left) A conceptual illustration of exploration bottleneck and scaffolding. (Right) Performance comparison of different LLMs on HealthBench-500.
RuscaRL's structured approach to scaffolding not only facilitates faster convergence but also broadens the reasoning boundaries of the models, enabling them to achieve higher accuracy with fewer samples, as evidenced by improvements in both Best-of-N evaluation metrics and novelty scores derived from importance sampling.
Conclusion and Future Work
RuscaRL represents a significant advance in integrating instructional scaffolding into LLM training, enabling these models to overcome the exploration bottleneck traditionally impeding their reasoning capabilities. While demonstrating superior performance, the approach relies on high-quality rubric datasets and is sensitive to rubric design, highlighting the need for future work on developing broader and richer rubric datasets. Future research directions include extending RuscaRL to multi-modal tasks and enhancing its scaffolding strategies to further improve model generalization and robustness.