- The paper proposes Rubrics as Rewards (RaR) to generate structured, multi-dimensional reward signals for handling subjective evaluation in RL.
- The methodology employs both explicit and implicit rubric aggregation, leading to performance gains of up to 28% over traditional Likert-based methods.
- Experimental results in medicine and science show that rubric-guided RL improves judge alignment and scales effectively across different model sizes.
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Introduction
The paper "Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains" introduces a novel framework to enhance the training of LLMs where traditional Reinforcement Learning with Verifiable Rewards (RLVR) encounters limitations due to the absence of verifiable ground-truth answers. Real-world tasks often involve complex, subjective evaluations that are challenging to encapsulate within objective reward functions. The current reliance on preference-based rewards via human judgment is susceptible to bias and requires extensive annotation, presenting challenges in scalability and robustness. This paper proposes "Rubrics as Rewards" (RaR), a framework using structured, checklist-style rubrics as an interpretable reward mechanism, particularly effective in real-world domains like medicine and science.

Figure 1: Overview of Rubrics as Rewards (RaR). (i) Rubric Generation: We synthesize prompt-specific, self-contained rubric criteria using a strong LLM guided by four core design principles, with reference answers serving as proxies for expert supervision. (ii) GRPO Training: These rubrics are used to prompt an LLM judge for reward estimation, which drives policy optimization via the GRPO on-policy learning loop.
Rubrics as Rewards Framework
The RaR framework introduces structurally defined rubrics as dynamic rewards for on-policy reinforcement learning training with GRPO (Generalized Proximal Policy Optimization). Rubrics effectively decompose complex evaluation criteria into granular subgoals, which are aggregated into multi-dimensional, weighted reward signals.
Rubrics are synthesized through LLMs that generate prompt-specific criteria based on expert reference answers, following four guiding principles:
- Expert Guidance: Ensures rubrics capture essential facts, reasoning, and conclusions.
- Coverage: Spans multiple dimensions of response quality, with a typical range of 7-20 rubric items per prompt.
- Weighting: Assigns importance levels categorically (e.g., Essential, Important, Optional, Pitfall) for interpretable reward aggregation.
- Self-Containment: Each item is independently actionable and does not require additional context or domain expertise for evaluation.
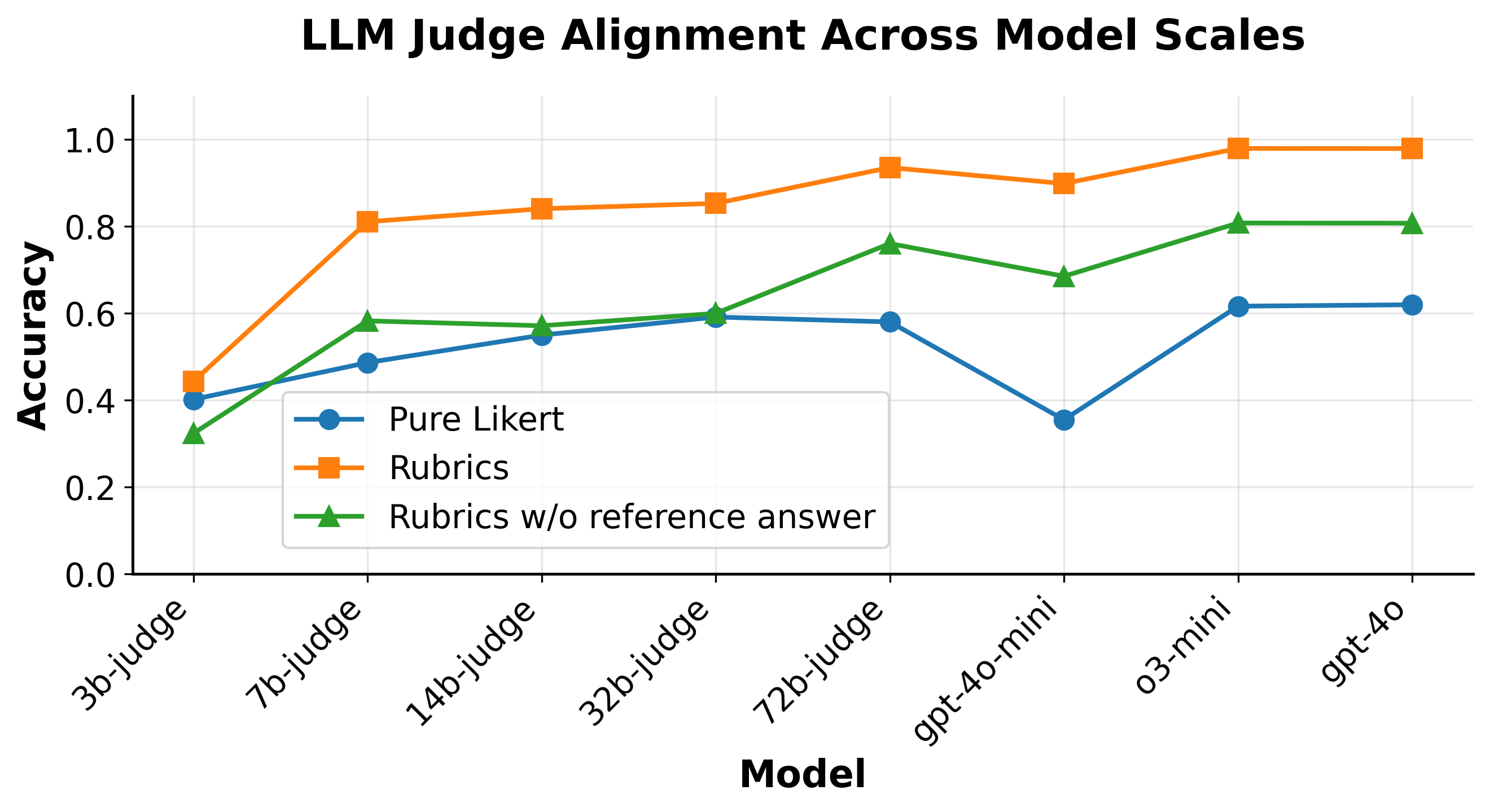
Figure 2: LLM Judge Alignment Across Model Scales. Rubric-guided evaluation (orange) consistently improves judge accuracy across model sizes compared to pure Likert-based scoring (blue). Rubrics without reference answers (green) perform better than Likert baseline, though still lag behind full rubric guidance. Smaller scale models benefit the most from rubric structure, narrowing the performance gap with larger judges.
Methodology
Rubric Generation and Synthesis
The authors propose using rubrics as a method for generating reward signals, thus providing a structured evaluation framework based on multiple criteria. Each rubric criterion is associated with a binary correctness function and a weighted importance label, detailed in the problem formulation:
r(x,y^)=∑j=1kwj∑j=1kwj⋅cj(x,y^)
The reward is calculated through either explicit or implicit rubric aggregation strategies:
- Explicit Rubric Aggregation: Utilizing binary correctness functions for each criterion, which are evaluated independently by a generative reward model.
- Implicit Rubric Aggregation: A description and weighting of criteria are input directly into an LLM-based judge, yielding a holistic scalar reward score.
These rubric-guided rewards bridge the gap between strictly verifiable RLVR and subjective preference models by allowing for transparent, structured signals that reflect multi-dimensional quality criteria.
\section{Experimental Evaluation on Benchmark Domains}
The study involves policy training using generated rubrics in two reasoning domains: Medicine and Science, with datasets RaR-Medical-20k and RaR-Science-20k providing diverse, high-quality prompts.
Experiments conducted on HealthBench-1k and GPQA_Diamond benchmarks demonstrate that rubric-based reward models significantly outperform traditional Likert-based approaches. Notably, the best variants using implicit rubric aggregation deliver up to a 28% relative improvement on HealthBench-1k and 13% on GPQA. The rubric-guided settings not only match but exceed the performance of models trained with direct reference-based Likert ratings.
Table~\ref{tab:main_results} highlights the advantage of harnessing rubrics over preference-based methods through detailed, transparent evaluation criteria. Structured rubrics outperform simple Likert rating across all model sizes when measuring judge alignment (Figure 2).
\section{Implications for Future Research}
The paper highlights several avenues for future research:
- Generalizability Across Domains: While the current study focuses on specific domains, future work could explore rubric-based RLVR in broader contexts, especially where subjective or multi-step judgment criteria are prevalent.
- Improved Judge Models: Dedicated LLM judges or developing more advanced reward models could enhance rubric evaluation fidelity, supporting complex aggregation and improved reasoning capabilities.
- Dynamic Weighting and Adaptive Curriculum: The semantic structure of rubrics provides a natural foundation for curriculum learning by progressively adapting the weight of different criteria.
- Investigating Reward Hacking: The impact of rubrics on reward robustness remains to be explored. Future research could shed light on using this structured approach to resist adversarial gaming.
In conclusion, this paper proposes a novel framework, Rubrics as Rewards, to bridge the gap between verifiable and subjective evaluation domains in reinforcement learning settings. By offering an interpretable, multi-criteria reward mechanism, rubric-based RL enhances alignment with human preferences, bringing us closer to general solutions for real-world tasks that defy simplistic evaluation. The framework holds promise for extension across diverse domains and new research directions, enriching the field of reinforcement learning by mitigating current limitations of reward designs.

