- The paper introduces the CoRE benchmark to assess how LLMs process emotional stimuli through cognitive appraisal dimensions.
- It employs a rigorous three-stage dataset construction pairing scenarios with 16 appraisal questions across 15 emotion categories.
- Results indicate that while LLMs mirror human-like appraisal structures, they exhibit notable biases and varying performance across complex emotions.
Cognitive Appraisal Analysis of LLMs
This paper explores the emerging capabilities and limitations of LLMs in emotional reasoning via cognitive appraisal dimensions. By moving beyond the basic emotional recognition tasks, it establishes a new benchmark, CoRE, to systematically analyze how LLMs process emotionally charged stimuli through cognitive dimensions grounded in appraisal theory.
Initial Considerations
Dataset Construction
The benchmark CoRE was constructed using scenarios designed to evoke self-appraisals across 15 emotion categories. Scenarios were created through a detailed three-stage process involving seeding, prompting, and filtering for quality. Each scenario is paired with 16 appraisal questions evaluating core cognitive dimensions. This extensive dataset ensures a comprehensive evaluation of LLMs on emotional reasoning.
Benchmarking Models and Setup
Multiple LLMs, both proprietary and open-source, were evaluated on CoRE. Each model was tasked with not only identifying emotions from scenarios but also generating corresponding cognitive appraisals. This setup allows for an assessment of whether models inherently favor certain cognitive dimensions and how these are used to characterize specific emotions.
Cognitive Evaluation Insights
Latent and Predictive Dimensions
The analysis revealed that LLMs largely align with human data concerning appraisal structures. Notably, valence-related features dominate initial principal components, closely followed by effort and agency dimensions. This suggests models comprehend some fundamental constructs of human emotion appraisal.
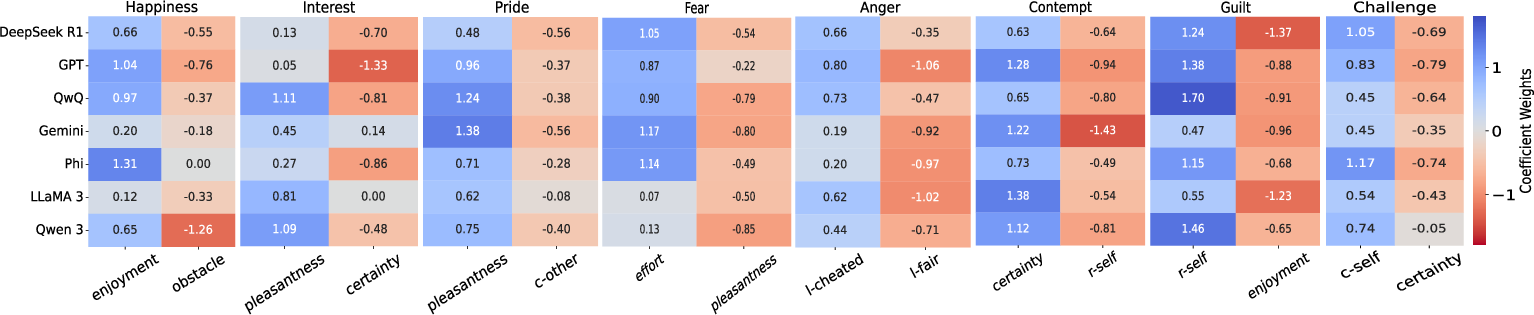
Figure 1: The feature weights/coefficients for Logistic Regression with L2 regularization.
Certain emotions showed predictable cognitive associations, e.g., Fear correlated with effort, and Anger with perceptions of unfairness, indicating nuanced model behavior underpinned by distinct appraisal patterns.
Model-Specific Nuances
Although broad trends were observed, significant disparities arose in finer details. LLMs show plausible reasoning patterns but struggle with complex emotional states such as Hope or Challenge. Identifying how models prioritize features like agency or valence revealed inherent biases likely shaped by their training.
Inter-Model Translation
Within-Model Consistency
LLMs demonstrated a shared latent structure in emotion appraisal, substantiating emotion topologies akin to valence-based separation (Figure 2). However, models had limitations distinguishing mixed emotions like Surprise or Challenge. Understanding these shared structures could advance the development of universally reliable emotional AI.
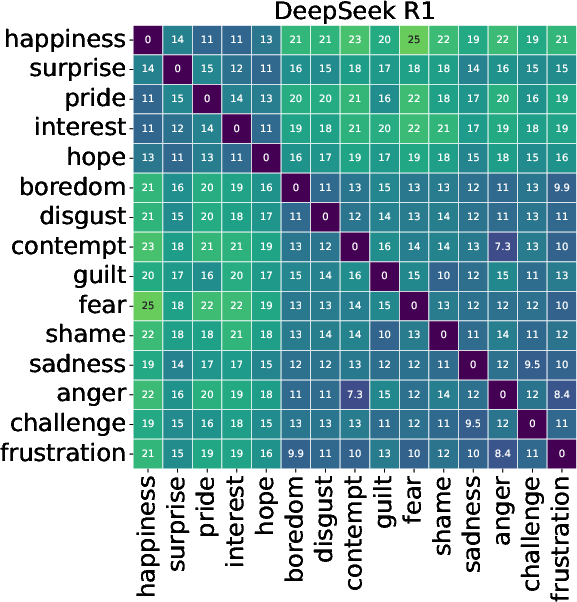
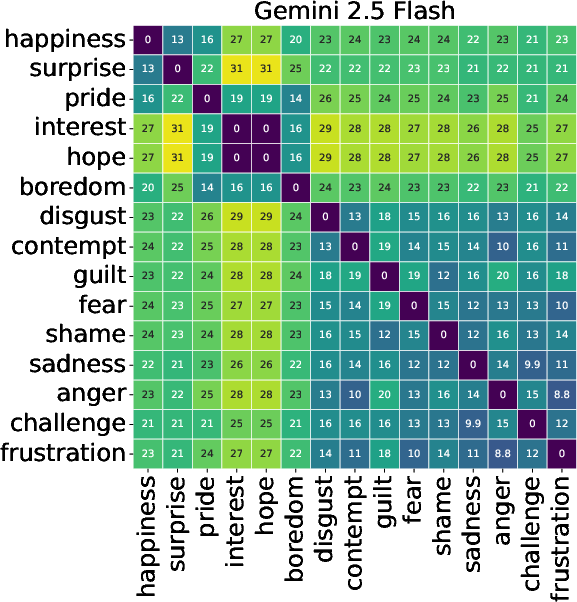
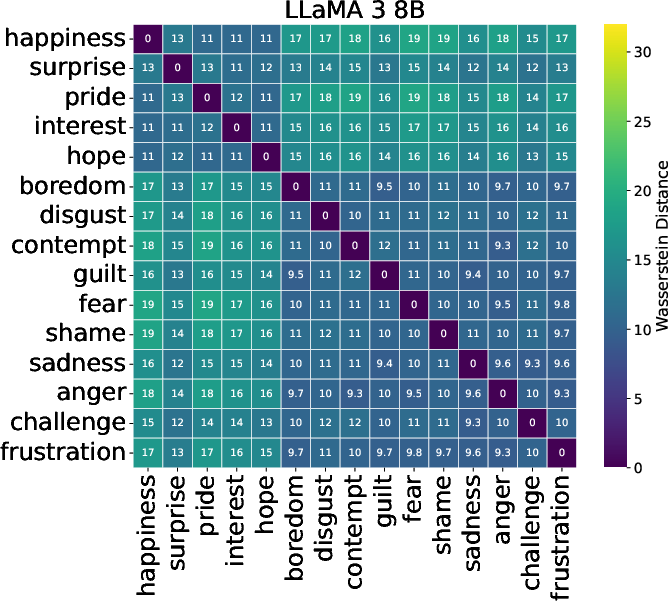
Figure 2: Distances between distributions of each emotion category, shown for each LLM.
Cross-Model Variability
Cross-model variability was marked. No universal appraisal structure was detected, with each model expressing unique biases in emotional representation, questioning the feasibility of transferring emotion models between systems. Some showed closer alignment with theoretical norms, exemplifying potential superior architectures for affective computing applications.
Practical and Theoretical Implications
These findings emphasize the complexity embedded in comprehending and simulating human-like emotional response in AI. The diverse appraisal patterns between and within models suggest that while LLMs make strides in simulating emotional cognition, challenges remain in achieving nuanced, context-sensitive emotional intelligence.
Advancements necessitate addressing these inherent discrepancies and biases. A deeper understanding of cognitive foundations can propel LLMs toward more holistic affective models, optimizing their integration into socially interactive AI systems.
Conclusions
LLMs are progressively replicating certain aspects of human emotional cognition through various appraisal mechanisms. However, significant strides are required to ensure robust emotion representation and processing. Future directions could include extending benchmarks to encompass more varied appraisal dimensions and investigating the role of fine-tuning in aligning machine cognition with human expectancy.
These paradigms—hovering between nascent associative logic and deep cognitive insight—serve as a cornerstone for AI-driven emotional reasoning, setting the stage for future developments bridging the AI-human emotion recognition chasm.

