- The paper introduces a two-phase training pipeline—rejection fine-tuning followed by multi-turn RL using DAPO—that significantly enhances software engineering agent performance.
- The study leverages novel algorithms like GRPO and DAPO to normalize rewards and stabilize policy updates in long-context, partially observable multi-turn environments.
- The approach minimizes reliance on proprietary models by successfully demonstrating competitive performance with open-weight models in complex software engineering tasks.
Training Long-Context, Multi-Turn Software Engineering Agents with Reinforcement Learning
This essay details a methodology for training long-context, multi-turn software engineering agents using reinforcement learning (RL). The paper's primary focus is on applying RL to domains requiring rich multi-turn interactions, such as software engineering (SWE), contradicting the common trend of focusing RL applications on single-turn problems.
Introduction
LLMs are increasingly integrated with autonomous agents to tackle complex tasks, with software engineering as a notable application domain. This integration promises significant economic benefits through automation of tasks like debugging, code generation, and software maintenance. Current methods for developing SWE agents typically employ proprietary LLM scaffolding, extensive inference-time scaling, or supervised fine-tuning of open-weight models. Despite their effectiveness, these approaches often depend on resource-intensive proprietary models, creating a demand for methods leveraging smaller, open-weight models. RL, with its ability to optimize agent policies via environment interaction, presents a promising alternative.
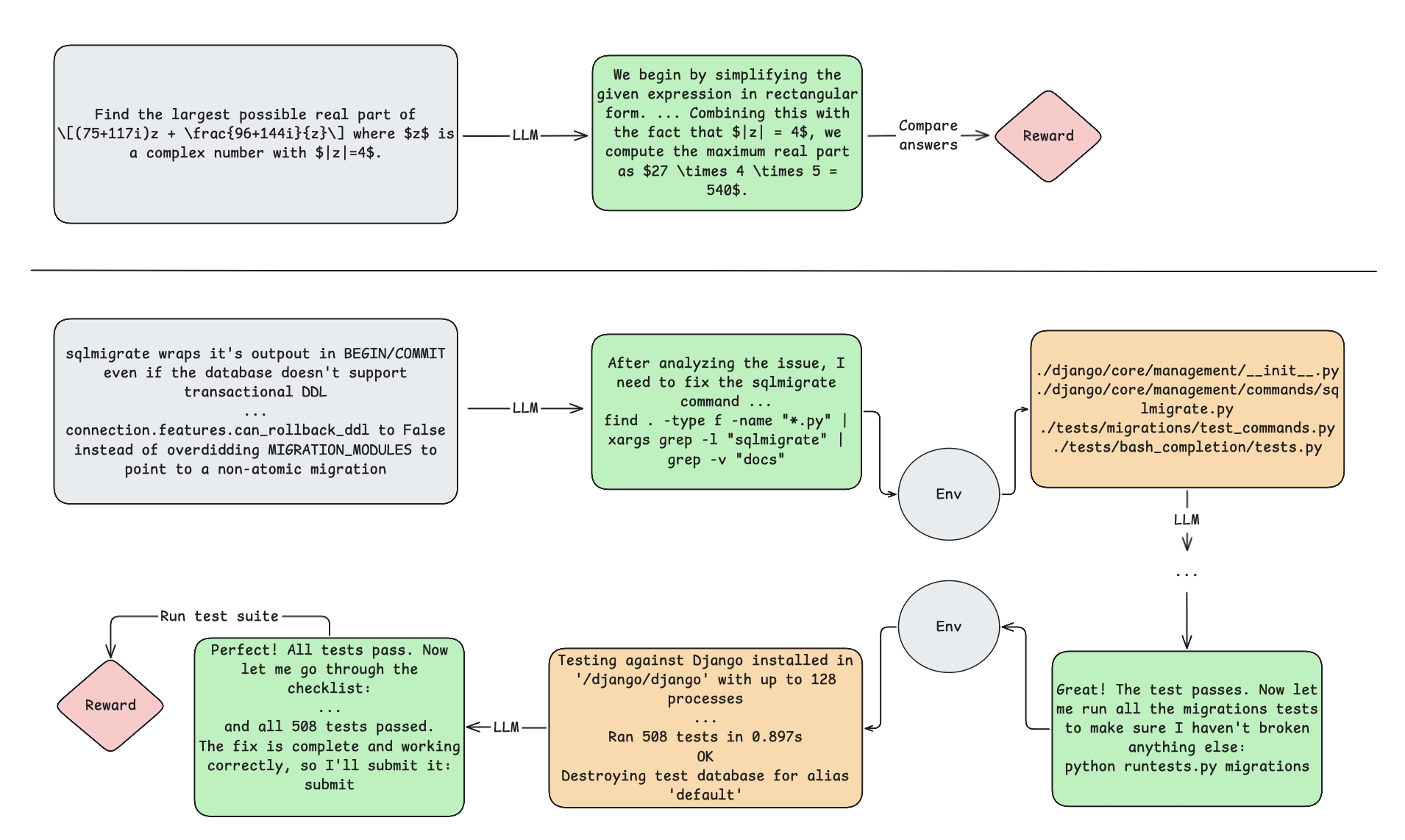
Figure 1: Illustration of task structure differences between bandit-style problems and POMDPs.
To harness RL's potential in SWE tasks, agents must manage long-horizon interactions and interpret complex feedback from stateful environments, overcoming challenges such as sparse rewards and expensive evaluations. This research addresses such challenges by developing a two-phase training pipeline comprising rejection fine-tuning (RFT) and a synchronous RL pipeline using DAPO.
Methodology
The task is formalized as a Partially Observable Markov Decision Process (POMDP), emphasizing multi-turn interactions with latent environment states. The agent's policy is trained to maximize expected cumulative rewards by observing and interacting with the environment over multiple turns.
Initially, Proximal Policy Optimization (PPO) was employed but replaced by Group-Relative Policy Optimization (GRPO). GRPO computes a trajectory's advantage by normalizing its terminal reward against the group's average reward. Subsequently, DAPO, an extension of GRPO, introduces practical improvements to stabilize and enhance training, including asymmetric clipping bounds and token-level loss computation.
Agent Scaffolding
The agent follows a structure similar to SWE-Agent, utilizing a ReAct-style loop with predefined tools for interaction. Tools range from shell commands to a submit command that concludes an episode, enabling efficient navigation and code edits within the environment.
Two-phase Training Pipeline
Data
The SWE-rebench dataset was curated with rigorous filtering to ensure high quality due to the constraints on task complexity and deterministic tests. This ensured effective task sampling for agent training and evaluation.
Phase 1: Rejection Fine-Tuning (RFT)
Starting with the Qwen2.5-72B-Instruct model, RFT was applied to warm up the model by masking incorrectly formatted commands, thus improving interaction adherence. Successful action trajectories were kept for supervised fine-tuning, nearly doubling the model’s initial performance on SWE-bench Verified.
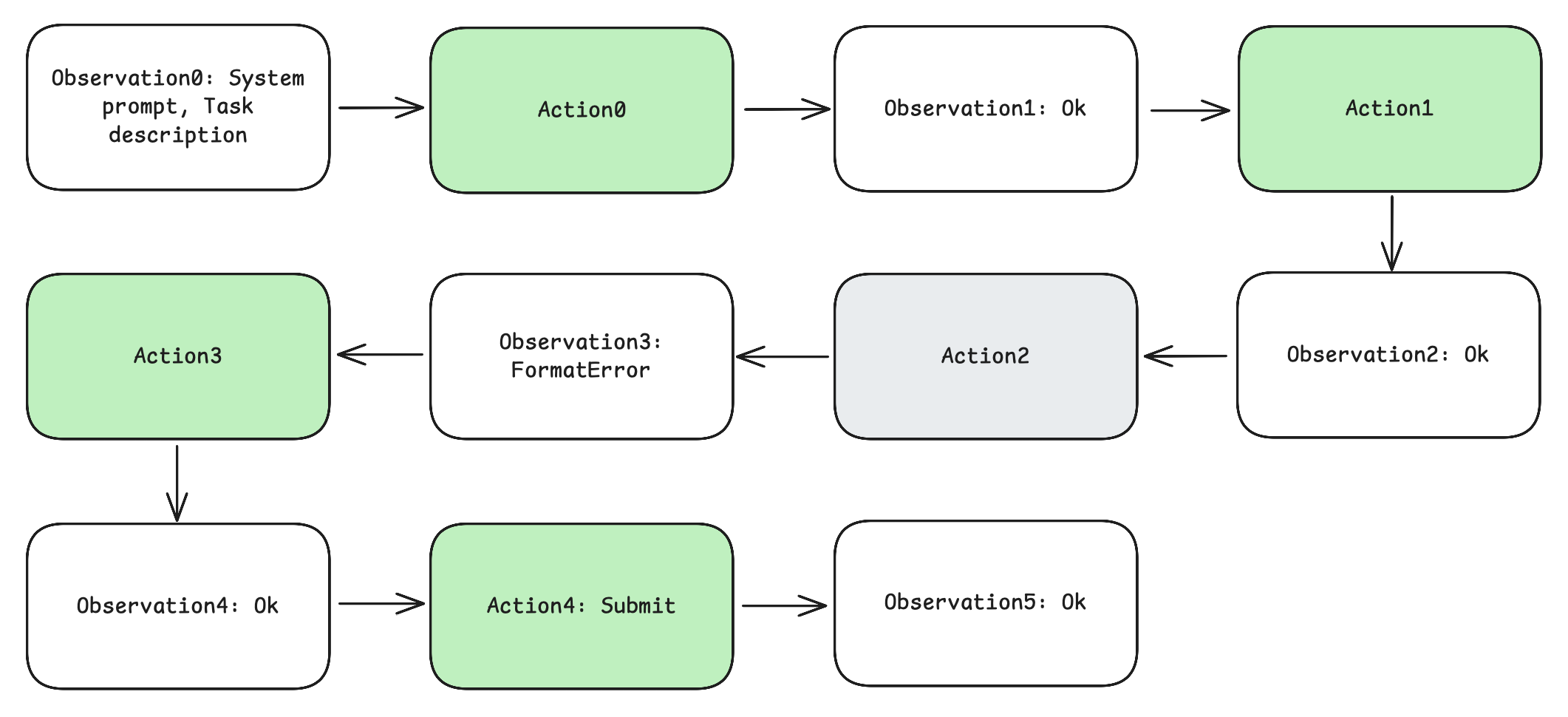
Figure 2: An example trajectory from the agent's interaction used in RFT.
Phase 2: Multi-turn RL
The RL training pipeline emphasizes iterative improvement via DAPO formulation, expanding context length and turn capacity. Two sequential stages refine the agent’s policy progressively, adapting rewards to reflect multi-turn challenges more accurately.
The meticulous design of task sampling, reward computation, advantage estimation, and optimization collectively pushed performance to competitive levels against larger, open-weight models.
Results and Findings
The agent exhibited robust improvements, markedly enhanced by transfer to extended context lengths in the second stage of training. While performance gains were substantial, discrepancies between sampling and training highlighted critical areas needing refinement. Biased sampling during rollout generation led to transient performance degradation, illustrating the importance of unbiased sampling strategies.
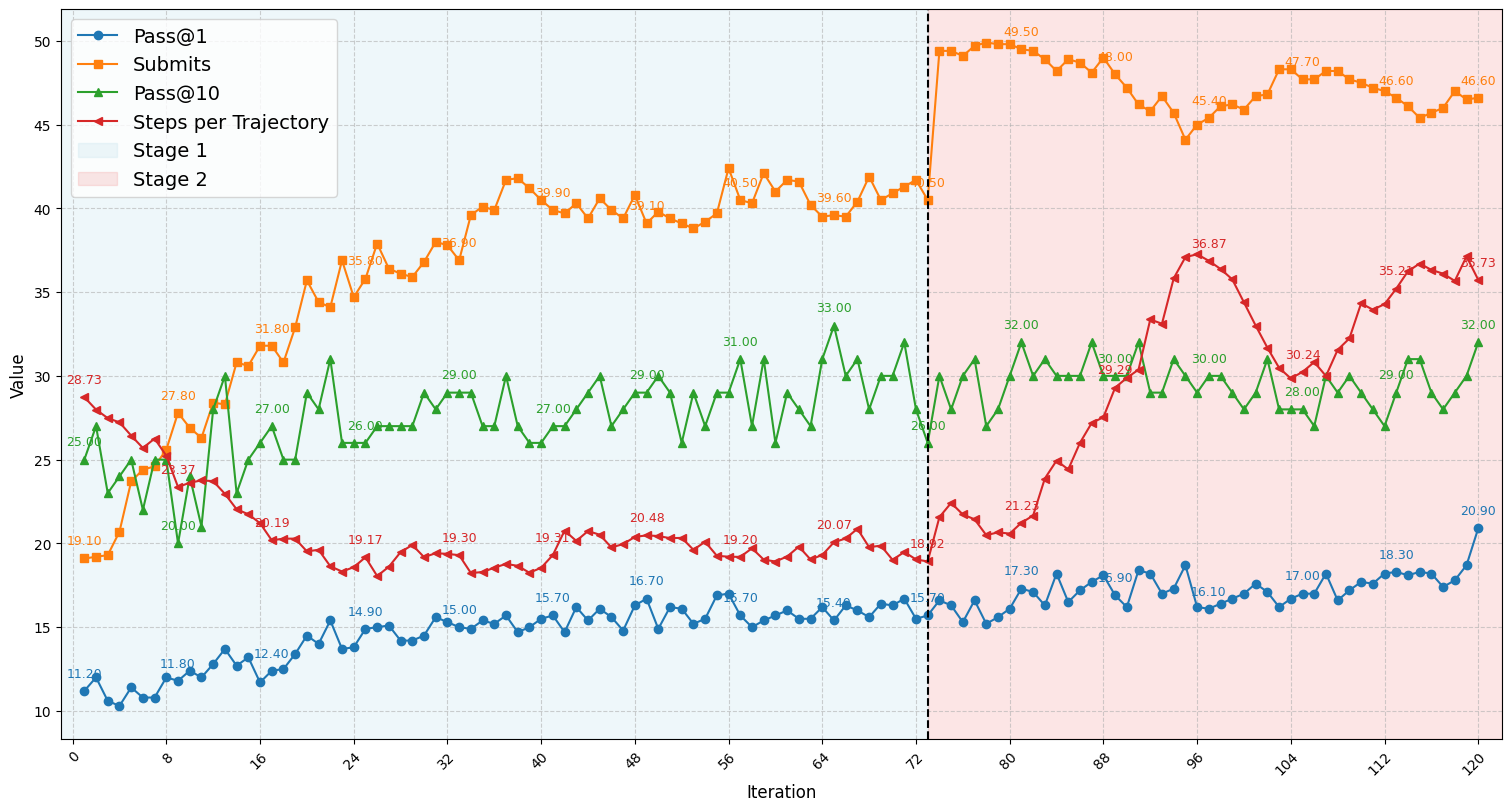
Figure 3: A detailed performance trend of the RL-trained agent over all iterations.
Discussion
The study validates RL's applicability to multi-turn, interactive SWE tasks, yet underscores challenges like sparse reward structures and evaluation noise that hinder efficient policy updates. Techniques such as reward shaping, auxiliary critic training, and uncertainty estimation could further enhance agent robustness.
Ultimately, the success of RL in training autonomous SWE agents demonstrates the viability of open-weight models for resource-efficient interaction task-solving, encouraging future research directions to refine credit assignment and extend agent capabilities.
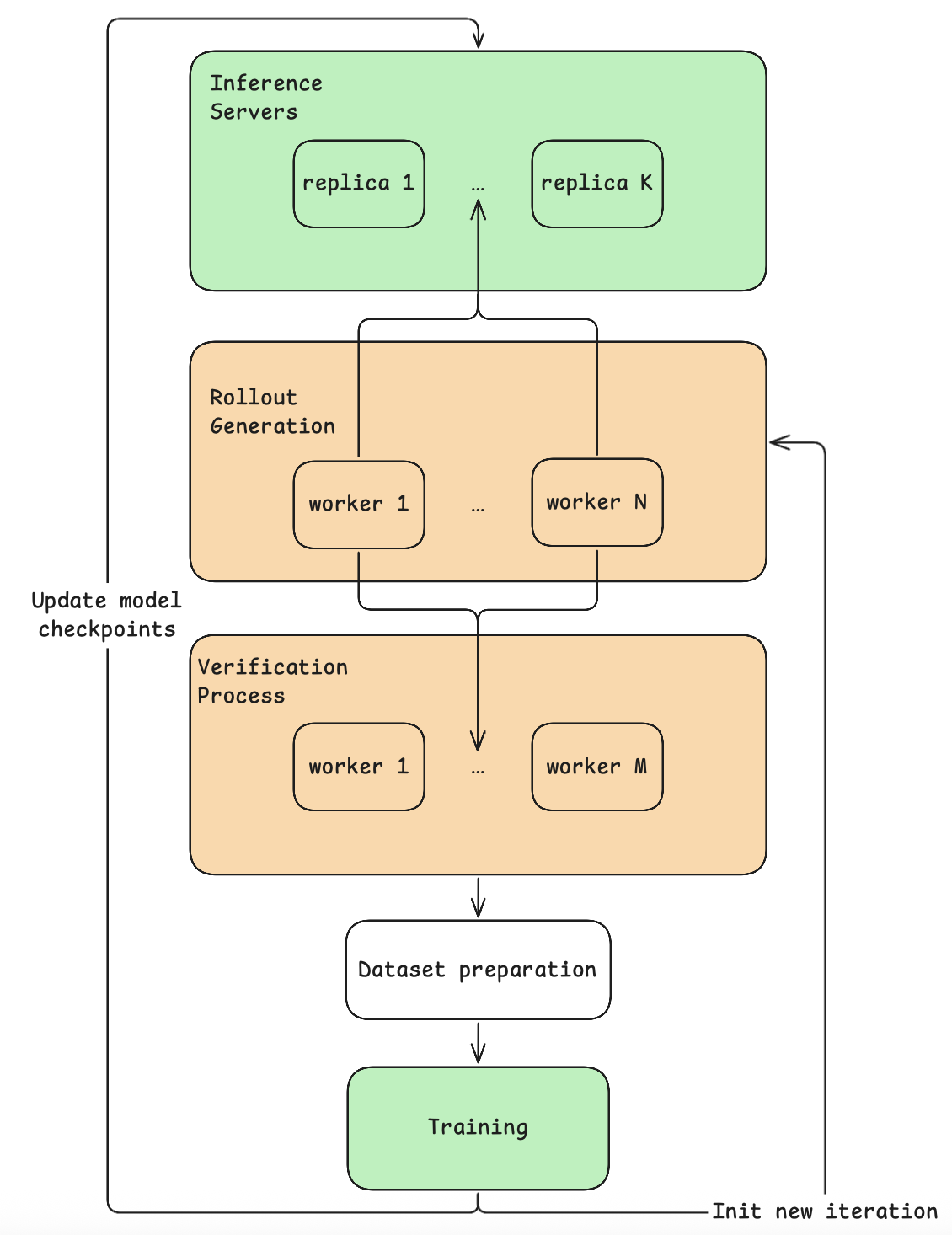
Figure 4: One synchronous iteration of the RL pipeline.
Conclusion
The paper presents a structured approach to training software engineering agents using RL, achieving competitive performance without reliance on proprietary models. Addressing inherent obstacles through adaptive training techniques contributes to advancing AI capabilities across complex, interactive domains, promising future innovation in agent-based learning and real-world application scenarios.