Supervised Reinforcement Learning: From Expert Trajectories to Step-wise Reasoning
Abstract: LLMs often struggle with problems that require multi-step reasoning. For small-scale open-source models, Reinforcement Learning with Verifiable Rewards (RLVR) fails when correct solutions are rarely sampled even after many attempts, while Supervised Fine-Tuning (SFT) tends to overfit long demonstrations through rigid token-by-token imitation. To address this gap, we propose Supervised Reinforcement Learning (SRL), a framework that reformulates problem solving as generating a sequence of logical "actions". SRL trains the model to generate an internal reasoning monologue before committing to each action. It provides smoother rewards based on the similarity between the model's actions and expert actions extracted from the SFT dataset in a step-wise manner. This supervision offers richer learning signals even when all rollouts are incorrect, while encouraging flexible reasoning guided by expert demonstrations. As a result, SRL enables small models to learn challenging problems previously unlearnable by SFT or RLVR. Moreover, initializing training with SRL before refining with RLVR yields the strongest overall performance. Beyond reasoning benchmarks, SRL generalizes effectively to agentic software engineering tasks, establishing it as a robust and versatile training framework for reasoning-oriented LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Supervised Reinforcement Learning: From Expert Trajectories to Step‑wise Reasoning — A Simple Explanation
What is this paper about?
This paper is about teaching AI LLMs to solve hard, multi-step problems (like tricky math questions or fixing real code bugs). The authors introduce a new training method called Supervised Reinforcement Learning (SRL). It helps small models learn better by giving them feedback at each step of their reasoning, not just on the final answer.
What questions are the researchers trying to answer?
They focus on three main questions:
- How can we help smaller AI models learn tough step-by-step reasoning when they almost never get the full answer right during practice?
- Can we use expert solutions to guide the model without forcing it to copy every word exactly?
- Is it better to train the model to think and act in steps, with feedback after each step, instead of grading only the final answer?
How did they try to solve it?
The paper compares three ways to train models:
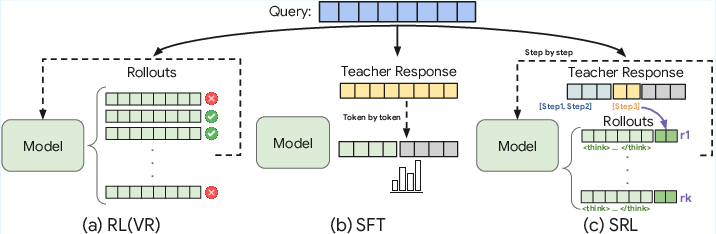
- Supervised Fine-Tuning (SFT): The model copies “teacher” answers word-by-word. This can make it overfit (memorize) and struggle when the problems are different.
- Reinforcement Learning with Verifiable Rewards (RLVR): The model tries many answers and gets a reward only if the final answer is correct. This fails when the model can’t find any correct answers to learn from.
- Their method: Supervised Reinforcement Learning (SRL)
Here’s how SRL works, in everyday terms:
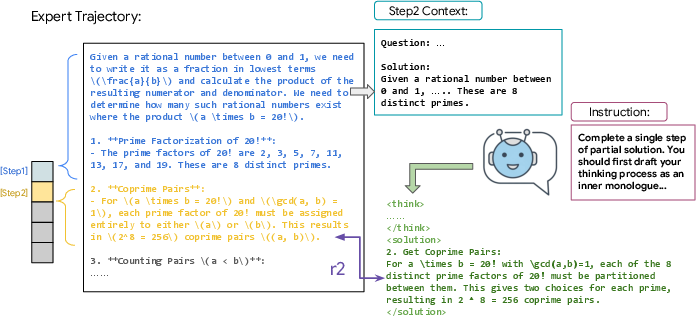
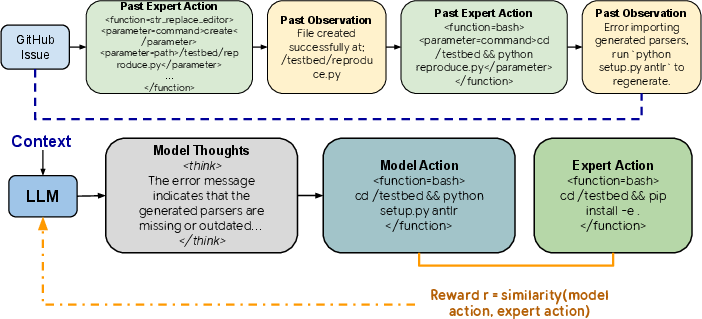
- Break the expert’s solution into steps: Think of solving a problem like following a recipe, one action at a time.
- The model thinks, then acts: Before each action, the model writes its “inner thoughts” (like scratch work), then proposes the next step.
- Step-by-step feedback: After each step, the model gets a score based on how similar its action is to the expert’s action for that step. This is like a coach checking each move in chess instead of only checking if you won at the end.
- Flexible thinking: The score only compares the action (what the model does), not its inner thoughts. So the model can develop its own way of thinking as long as it takes the right actions.
- Efficient scoring: They use a tool (like a text comparison program) to measure how close the model’s action is to the expert’s action. If the output is in the wrong format, it gets a penalty.
- Smarter practice selection: If a training question isn’t teaching the model anything (all attempts look the same), they skip it and pick a more informative one.
In technical terms (kept simple):
- They convert expert solutions into many “partial problems,” where the model must write the next step.
- They train with an RL-style algorithm (GRPO) but use the step similarity score as the reward.
- This gives “dense” rewards (lots of helpful feedback), not “sparse” rewards (only at the end).
What did they find, and why does it matter?
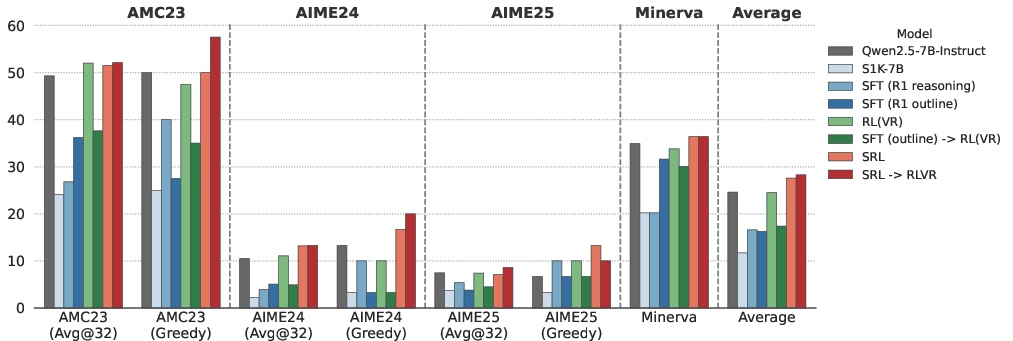
On hard math problems:
- Training by copying (SFT) actually made the model worse on a very challenging dataset.
- Training with only final-answer rewards (RLVR) gave small gains.
- SRL clearly beat both methods.
- Best of all, doing SRL first and then RLVR worked the best overall. In other words, learn good steps first, then polish with final-answer rewards.
On real software engineering tasks (fixing real GitHub bugs):
- Their SRL-trained coding model solved far more issues than baselines.
- With “oracle file edit” (the model is told exactly which file to change), the SRL model fixed 14.8% of issues vs. 8.4% for a strong SFT model.
- In a full end-to-end setting (the model must find the bug and fix it), SRL still doubled performance (8.6% vs. 4.2%).
They also noticed:
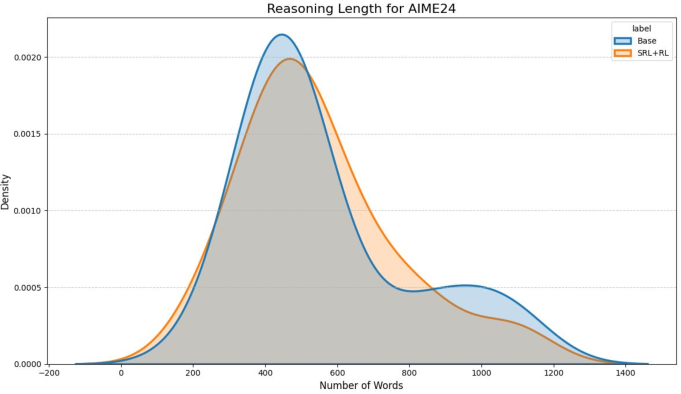
- SRL models plan and check their work more naturally. They sometimes outline steps first, adjust their plan mid-way, and verify their answers before finishing.
- The improvements did not come from just writing longer answers; they came from better-quality reasoning.
Why is this important?
- It helps small, open-source models learn difficult reasoning skills that used to be out of reach.
- It avoids the main problems of SFT (over-copying) and RLVR (no reward when everything is wrong).
- It works not just for math, but also for complex, real-world coding tasks.
- It suggests a practical recipe: train step-by-step with SRL, then fine-tune with final-answer RL to get the best results.
Simple takeaways and future impact
- Think of SRL as “coached practice”: the model gets guidance after every move, not just a pass/fail at the end.
- This approach makes training more stable, more efficient, and more general-purpose.
- It could lead to better tutoring AIs, coding assistants, and problem-solving agents that reliably explain their steps and fix mistakes along the way.
- As AI is asked to do more multi-step tasks in the real world, teaching it to plan, act, and self-check—step by step—will be key. SRL is a strong step in that direction.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues, uncertainties, and missing explorations that future work could address.
- Generalization beyond explicitly structured demonstrations: SRL relies on teacher trajectories with clear, numbered step boundaries (e.g., DeepSeek R1). How to robustly decompose unstructured or noisy reasoning traces into actions across domains without step annotations?
- Action segmentation and alignment: The paper does not specify a principled algorithm for extracting and aligning “actions” from teacher traces. How sensitive are results to segmentation heuristics, and can dynamic alignment (e.g., edit-distance alignment or learned segmentation) better handle branching or reordering?
- Reward semantics vs. surface similarity: The sequence-similarity reward (difflib.SequenceMatcher) is token/character-oriented and may reward superficial copying over semantic equivalence. Can embedding-based, programmatic, or verifier-informed rewards better capture correctness while tolerating paraphrase and diverse solution strategies?
- Multiple correct strategies: SRL’s reward centers on matching a single expert action sequence. How to avoid penalizing equally valid alternative actions/plans and handle tasks with high solution diversity?
- Teacher quality and error propagation: SRL implicitly inherits teacher errors (both step structure and content). What mechanisms (e.g., trajectory filtering, verifier-in-the-loop, confidence-weighted rewards) mitigate training on flawed or suboptimal expert actions?
- Format-driven incentives: Assigning −1 reward for format violations may overemphasize formatting compliance. What is the trade-off between format adherence and substantive reasoning skills, and how should the penalty scale be chosen?
- Inner monologue quality and utility: SRL does not reward or evaluate the “think” monologue. Does monologue quality matter for downstream reasoning, and could process-level rewards (e.g., step correctness explanations, consistency checks) improve the learned reasoning?
- Outcome-aware rewards in software agents: In SWE tasks, rewards are computed on textual commands rather than environment outcomes. Can outcome-aware or offline RL signals (e.g., tool execution success, test pass/fail) be feasibly integrated to reduce reliance on command-string similarity?
- Long-context constraints: Step-wise prompting concatenates prior steps, which may exceed context limits in large codebases or long math solutions. How does context truncation or memory management affect SRL, and what scalable context strategies are needed?
- Dynamic sampling bias: Filtering based on reward variance may favor samples where the model is already close to the expert, potentially skipping the hardest queries. What curriculum or sampling strategies maintain coverage of difficult problems while preserving training stability?
- Hyperparameter sensitivity and stability: The paper does not explore sensitivity to GRPO clipping, KL coefficient β, group size G, reward-variance threshold ε, or the reward scaling (−1 vs. [0, 1]). Systematic ablations and stability analyses are needed.
- Reference policy and KL regularization details: The choice and dynamics of the reference policy p_ref in GRPO are unspecified. How does p_ref selection impact exploration, stability, and performance in SRL?
- Compute and sample efficiency: Training budgets (wall-clock time, rollout counts, GPU hours), and sample efficiency curves are not reported. What are the compute/efficiency trade-offs of SRL vs. RLVR and SFT at different scales?
- Baseline strength and breadth: RLVR baselines use GRPO with dynamic sampling but omit stronger process-supervised RL variants and richer reward designs. How do SRL gains compare against state-of-the-art RL baselines under matched budgets and tuning?
- Statistical robustness: Results use single runs and best checkpoints without reporting variance, confidence intervals, or significance testing. Do improvements hold across seeds, replicates, and broader evaluation suites?
- Data exclusions and potential bias: Math data points not matching the expected step format were excluded. What is the effect of this filtering on generalization, and can SRL be made robust to nonconforming data?
- Step title leakage: Providing step titles as additional context reportedly boosts performance. Does this scaffold induce label leakage or unrealistic conditioning, and how well does SRL generalize without step titles?
- Per-step correctness assessment: SRL optimizes action similarity but does not report per-step correctness (e.g., math validity checks). Can step-level verifiers improve training signals and reduce reward hacking via surface matching?
- Branching, backtracking, and re-planning: SRL rewards a linear action sequence. How should rewards be adapted when correct plans require branching, detours, or backtracking, especially in exploratory tasks (agents, proofs, debugging)?
- Domain breadth and transfer: Experiments cover math and SWE with a single model family (Qwen2.5). How well does SRL transfer to other domains (scientific QA, tool use, planning), larger/smaller models, multilingual and multimodal settings?
- Combination schedule with RLVR: SRL → RLVR shows gains, but the order, schedule, and mixing ratio are not explored. What curriculum and annealing strategies most effectively combine SRL and outcome-based RL?
- Evaluation coverage and contamination: Only a subset of math benchmarks is used; contamination risks are unaddressed. Broader, contamination-controlled evaluations (and verifier-based metrics) would strengthen claims.
- Reward scaling and calibration: Positive rewards ∈ [0, 1] and format penalty −1 may skew gradients. How should rewards be calibrated (e.g., normalization, baselines) to balance exploration, imitation, and stability?
- Safety and alignment of hidden thoughts: Training models to produce inner monologues raises security and alignment questions (prompt injection, disclosure risks). What safeguards and evaluation protocols ensure safe use of “think” tags?
- Reproducibility of preprocessing: The exact parsing rules for step extraction, action definition (math vs. SWE), and data cleaning pipelines are not fully specified. Publishing code and detailed procedures would enable reliable replication.
- Measuring reasoning quality beyond length: The paper shows no increase in reasoning length but does not quantify reasoning quality (e.g., plan coherence, verification frequency, error correction). What reliable process-level metrics correlate with SRL gains?
Glossary
- Advantage function: A measure used in reinforcement learning to estimate the benefit of an action compared to a baseline, guiding policy updates. "The advantage function, , is defined as the group-level normalized reward."
- Agentic software engineering: Tasks where an AI agent autonomously interacts with software systems to diagnose and fix issues. "Beyond reasoning benchmarks, SRL generalizes effectively to agentic software engineering tasks,"
- Autoregressively: A token-by-token generation process where each token is conditioned on previous tokens. "The response is produced autoregressively,"
- Average@32: An evaluation metric averaging accuracy over 32 sampled outputs per problem. "we report the average@32 score with a temperature of 1.0"
- Chain-of-Thought (CoT): Explicit step-by-step reasoning traces included in model outputs or training data. "long Chain-of-Thought (CoT) rationales"
- Clipping threshold: A limit used in policy optimization to constrain update magnitude for stability. "introduces a token-level loss and relaxes the policy update constraint by increasing the clipping threshold."
- Conditional probability: The likelihood of an output given an input context, fundamental to language modeling. "maximize the conditional probability of generating the target response"
- Dynamic sampling: A training strategy that filters or resamples batches to maintain informative reward variance. "DS stands for dynamic sampling."
- End-to-end evaluation: A holistic assessment where the agent performs all steps from problem understanding to patch generation. "End-to-end evaluation: This setting uses the Agentless-mini agent scaffold"
- Greedy sampling: Decoding that selects the highest-probability token at each step without exploration. "report the accuracy of greedy sampling."
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm that uses group-based relative advantages and clipping for updates. "Group Relative Policy Optimization (GRPO) algorithm"
- Group-level normalized reward: A reward normalization across multiple rollouts to compute relative advantages. "is defined as the group-level normalized reward."
- Holistic sequence similarity reward: A reward computed by comparing the entire generated solution to the full expert trajectory in one shot. "Holistic sequence similarity reward: The model generates a complete solution in a single step."
- Imitation learning: Learning by mimicking expert demonstrations rather than optimizing outcome-based rewards. "An alternative approach is imitation learning, commonly implemented via Supervised Fine-Tuning (SFT) on expert demonstrations"
- Internal reasoning monologue: Private reasoning text generated by the model before committing to actions. "generate an internal reasoning monologue"
- KL divergence: A regularization term measuring the difference between two probability distributions (policy and reference). "the KL-divergence penalty"
- LLM: A neural model that defines a probability distribution over token sequences to generate text. "A LLM is formally defined"
- Negative log-likelihood loss: The standard supervised objective minimizing the negative log probability of target sequences. "negative log-likelihood loss function"
- Oracle file editing evaluation: A setting where the correct files to modify are provided, isolating patch generation ability. "Oracle File Edit"
- Outcome-based RL: Reinforcement learning that rewards only on final outcome correctness, not intermediate steps. "outcome-based RL methods"
- Pass@k rate: The probability of obtaining at least one correct solution within k sampled attempts. "when the pass@ rate remains zero even after sampling rollouts"
- Policy model: The model acting as a policy in RL, mapping states to action distributions. "the policy model receives reward signals purely based on the final answer correctness."
- Policy update ratio: The ratio between new and old policy probabilities used in clipped policy optimization. "the clipping range for the policy update ratio"
- Reinforcement Learning (RL): A learning paradigm optimizing actions via rewards from interactions. "Reinforcement Learning (RL)."
- Reinforcement Learning with Verifiable Reward (RLVR): RL that uses correctness-verified outcomes as rewards. "RL with verifiable reward (RLVR)"
- Resolve rate: The percentage of issues correctly fixed in software engineering benchmarks. "resolve rate (\%)"
- Rollout budget: The number of sampled trajectories allowed per input during training or evaluation. "limited rollout budget"
- Rollouts: Sampled trajectories of model outputs used to compute rewards and policy gradients. "sampling rollouts"
- Sequence similarity reward: A dense step-level reward based on similarity between generated and expert actions. "With the sequence similarity reward in SRL,"
- Self-reflection: A reasoning strategy where the model evaluates and corrects its own intermediate steps. "problem-solving strategies such as self-reflection"
- Step-wise inner thoughts: Interleaved private reasoning blocks accompanying each action step. "the model generates a next step action along with its step-wise inner thoughts"
- Supervised Fine-Tuning (SFT): Training a model to predict expert outputs via supervised learning on labeled pairs. "Supervised Fine-Tuning (SFT)."
- Supervised Reinforcement Learning (SRL): A framework combining step-wise supervision with RL-style rewards aligned to expert actions. "Supervised Reinforcement Learning (SRL)"
- Solution trajectory: The full sequence of reasoning steps and actions leading to a final answer. "Given an expert solution trajectory "
- Verifiable outcome reward: A reward computed from the correctness of the final answer that can be automatically checked. "RL with verifiable outcome reward"
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, grounded in the paper’s findings on step-wise action supervision, dense sequence-similarity rewards, and the SRL → RLVR training curriculum.
- Small-model reasoning upgrades for AI/ML teams (Software/AI)
- What: Adopt the SRL training recipe to boost multi-step reasoning in 7B-scale open-source models, and optionally refine with RLVR for further gains.
- How: Decompose teacher trajectories into step actions; train with sequence-similarity rewards (e.g., difflib.SequenceMatcher) and dynamic sampling; follow with outcome-based RLVR.
- Tools/workflows: SRL training pipeline, action parsers for step titles, reward calculators, GRPO with dense rewards, dynamic batch filtering.
- Assumptions/dependencies: High-quality, structured expert trajectories (e.g., R1-style numbered steps); base model has basic instruction-following; available compute; verifiers for RLVR.
- Math tutoring and formative assessment (Education)
- What: Deploy SRL-trained small models as math tutors that provide step-by-step hints, interleaved planning, and self-verification—improving correctness without longer outputs.
- How: Use SRL on curated math CoT datasets (e.g., s1k), serve per-step feedback, and track partial correctness via sequence-similarity.
- Tools/workflows: Student-facing tutor apps, per-step hint generation, targeted error feedback, average@k evaluation harnesses.
- Assumptions/dependencies: Coverage of curricula; properly parsed step structures; guardrails to prevent revealing full solutions prematurely.
- CI/CD issue triage and patch suggestion (Software engineering)
- What: Integrate SRL-trained code agents into CI pipelines to propose verified patches or reproduction steps, improving SWE-Bench resolve rates and reducing triage time.
- How: Train on step-wise agent trajectories with environment-consumable actions (e.g., bash/file edits), then plug into Agentless-mini-like scaffolds.
- Tools/workflows: Safe sandboxes, test runners, patch verification, human-in-the-loop approval gates.
- Assumptions/dependencies: Repository access, deterministic test suites, execution environment isolation, trajectory quality.
- Structured tool-using copilots for knowledge work (Software/business productivity)
- What: Build step-wise copilots that perform sequences of API/tool calls (search → retrieve → transform → report), guided by expert action templates.
- How: Treat each tool call as an action; train with SRL to align to expert sequences while allowing flexible internal planning.
- Tools/workflows: Connectors to office suites/BI tools; action schema libraries; monitoring dashboards.
- Assumptions/dependencies: Reliable tool APIs; standardized action schemas; format compliance (action blocks vs. inner “think” tags).
- Step-wise dataset augmentation from expert traces (Academia/AI training)
- What: Multiply training instances by creating N−1 partial contexts per complete solution, improving data efficiency for small models.
- How: Parse structured teacher traces to produce step-conditioned targets; use step titles to contextualize next-step prediction.
- Tools/workflows: Parsing scripts; data curation pipelines; validation splits for step-level tasks.
- Assumptions/dependencies: Consistent formatting (numbered steps, titles); licenses permitting derivative datasets.
- Training curriculum design: SRL → RLVR (AI/ML ops)
- What: Adopt SRL-first then RLVR as a standard curriculum for reasoning-oriented LLMs to achieve best overall performance.
- How: Initialize with dense, step-wise rewards; refine with outcome-verifiable RL; apply dynamic sampling to avoid zero-gradient batches.
- Tools/workflows: GRPO variants; reward density checks; advantage normalization; KL constraints.
- Assumptions/dependencies: Availability of verifiers for RLVR; monitoring of training stability; compute budgets.
- Safer generation via interleaved planning and verification (Software/content generation)
- What: Prompt and train models to insert self-checks before committing answers (e.g., “verify step” blocks), reducing hallucinations and brittle chains.
- How: Use SRL to encourage structured inner monologue (think tags) and external action alignment; enforce format validators.
- Tools/workflows: Prompt templates with planning/verification slots; format checkers; error-correction steps.
- Assumptions/dependencies: Clear separation of “thinking” vs. user-facing content; adherence to tagging conventions; user experience tuning.
- Partial-credit evaluation for student work and LLM outputs (Education/academia)
- What: Use sequence-similarity rewards as a practical proxy for step-level correctness to grade solutions that are partially correct.
- How: Compare student or model steps to reference actions using non-overlapping matching blocks; penalize format violations separately.
- Tools/workflows: Automated grading rubrics; similarity dashboards; per-step feedback reports.
- Assumptions/dependencies: Reference solutions sufficiently representative; calibration of similarity thresholds; fairness considerations.
- Compliance/audit logs for AI decisions (Policy/compliance)
- What: Record step-wise action sequences and internal verification checkpoints to support auditability of AI reasoning.
- How: Persist action traces; confirm alignment to policy-defined process steps; report deviations.
- Tools/workflows: Structured audit trails; process similarity checks; compliance dashboards.
- Assumptions/dependencies: Defined policy action schemas; privacy controls for internal monologue; governance for storage and review.
- Personal study assistants for problem solving (Daily life)
- What: Provide step-wise help in math and logic puzzles with concise plans and verification, running on small local models.
- How: Distill small models using SRL on high-quality traces; offer hints and checks rather than full solutions.
- Tools/workflows: Mobile/desktop apps; local inference; cached step libraries.
- Assumptions/dependencies: On-device optimization; curated datasets; guardrails to prevent answer leakage.
Long-Term Applications
The following opportunities require further research, scaling, domain adaptation, or policy development before broad deployment.
- Cross-domain agent training (Robotics/RPA/industrial automation)
- What: Extend SRL to embodied or robotic agents by mapping “actions” to low-level controls or high-level skills.
- Potential: More learnable curricula for complex, multi-step tasks (assembly, inspection, process control).
- Dependencies: Action schema design; high-fidelity simulators; safe reward shaping; real-world transfer and safety certification.
- Clinical decision support with audited reasoning (Healthcare)
- What: Use step-wise reasoning aligned to clinical guidelines for diagnosis/treatment planning, with verification steps.
- Potential: Transparent assistants that provide auditable decision chains and partial-credit grading for differential diagnoses.
- Dependencies: Expert, guideline-grounded trajectories; rigorous evaluation; bias/safety controls; regulatory approvals.
- Legal and compliance automation with policy-aligned steps (Legal/policy)
- What: Encode policy checklists as action schemas and train models to follow them, rewarding similarity to compliant sequences.
- Potential: Automated contract review or regulatory filings with traceable adherence.
- Dependencies: High-quality legal datasets; frequent policy updates; liability frameworks; human oversight.
- Autonomous software maintenance at scale (Software/SRE)
- What: End-to-end agents that triage, patch, verify, and deploy fixes with SRL → RLVR training loops.
- Potential: Continuous improvement via offline SRL from verified trajectories and online RLVR from test outcomes.
- Dependencies: Robust automated verifiers; rollback/kill-switches; security reviews; organizational change management.
- Standardized auditability of AI reasoning (Policy/standards)
- What: Adopt step-wise action logs as a regulatory norm for AI accountability and incident review.
- Potential: Sector-wide standardization of process similarity metrics and format compliance.
- Dependencies: Standards bodies; interoperable schemas; privacy and IP considerations.
- On-device reasoning assistants (Consumer devices)
- What: Deploy SRL-boosted 7B models on edge devices for private, fast step-wise assistance.
- Potential: Better local tutoring, spreadsheet logic checks, and planning tools without cloud dependency.
- Dependencies: Model compression/quantization; memory footprint management; hardware acceleration.
- SRL-first training platforms (AI infrastructure/MLOps)
- What: Productize SRL pipelines with modular reward services, data parsers, and dynamic samplers.
- Potential: “SRL-as-a-service” for enterprises to convert internal SOPs/expert traces into trainable action curricula.
- Dependencies: Integration with data lakes; governance; cost control; support for domain-specific action schemas.
- Scientific research planning assistants (Academia/industrial R&D)
- What: Train assistants to produce step-wise experimental plans, checks, and analyses aligned to lab protocols.
- Potential: Improved reproducibility and transparent methodology with partial-credit evaluation of plans.
- Dependencies: Domain trajectories; LIMS integration; safety constraints; peer-review-compatible logging.
Collections
Sign up for free to add this paper to one or more collections.