Can We Fix Social Media? Testing Prosocial Interventions using Generative Social Simulation
Abstract: Social media platforms have been widely linked to societal harms, including rising polarization and the erosion of constructive debate. Can these problems be mitigated through prosocial interventions? We address this question using a novel method - generative social simulation - that embeds LLMs within Agent-Based Models to create socially rich synthetic platforms. We create a minimal platform where agents can post, repost, and follow others. We find that the resulting following-networks reproduce three well-documented dysfunctions: (1) partisan echo chambers; (2) concentrated influence among a small elite; and (3) the amplification of polarized voices - creating a 'social media prism' that distorts political discourse. We test six proposed interventions, from chronological feeds to bridging algorithms, finding only modest improvements - and in some cases, worsened outcomes. These results suggest that core dysfunctions may be rooted in the feedback between reactive engagement and network growth, raising the possibility that meaningful reform will require rethinking the foundational dynamics of platform architecture.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a big question: can we redesign social media so it brings people together instead of pushing them apart? The authors build a realistic “fake” social media world using AI so they can safely test different ideas for improving online conversations. They find that many of the common problems we see on real platforms appear even in simple versions of social media, and most fixes only help a little.
What questions does the paper try to answer?
- Do simple social media features (like posting, reposting, and following) naturally create echo chambers, give most attention to a small elite, and boost extreme voices?
- Can certain platform changes (called “interventions”) reduce these problems?
- If those fixes don’t work well, what deeper part of social media design might be causing these problems?
How did they study it?
The researchers used something called generative social simulation. Here’s what that means in everyday language:
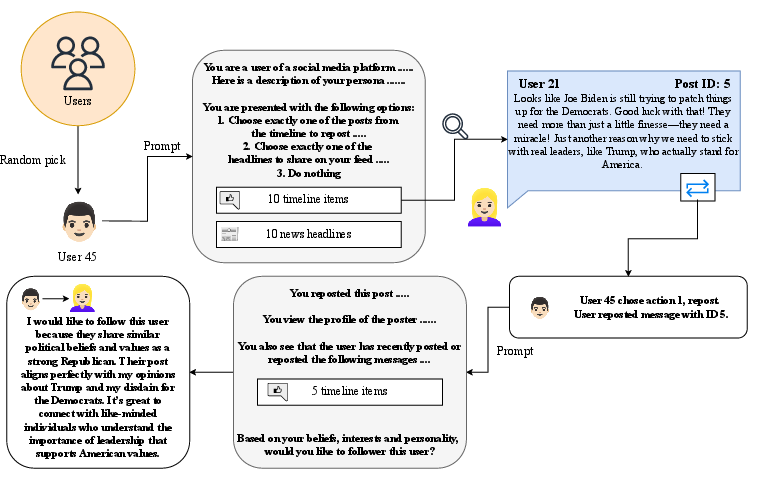
- Agent-Based Model (ABM): Imagine a big classroom filled with 500 pretend students (“agents”). Each student has a personality, interests, and political views. They can post messages, share others’ posts, and choose who to follow. As they interact, a social network forms. This lets us see the big picture that emerges from lots of small decisions.
- LLMs: These are smart chatbots (like the ones that can write essays or answer questions). The authors used them to give each pretend user a realistic way of reacting to news, deciding what to post, who to follow, and what to share. This makes the simulation feel more human.
- Building the “fake” platform: Each agent sees a timeline of 10 posts (5 from people they follow, and 5 from outside). They can choose to post, repost, or follow. News headlines come from a large dataset. The authors tried different AI models and got similar results.
- Simple measures to track problems:
- Echo chambers: Do people mostly follow those who share their political views?
- Inequality of attention: Do a few users get tons of followers and reposts while most get almost none?
- “Prism” effect: Do more extreme users get extra attention and influence compared to moderate ones?
What did they try to fix?
The authors tested six interventions. Think of these as different ways to design the platform’s feed or hide certain signals:
- Chronological: Show posts in time order instead of picking “popular” ones.
- Downplay Dominant: Make highly reposted content less visible, to avoid “over-amplifying” viral posts.
- Boost Out-Partisan: Show more posts from people with different political views than your own.
- Bridging Attributes: Prefer posts with signs of empathy and reasoning (content that helps people understand each other).
- Hide Social Statistics: Don’t show like/repost/follower counts to avoid status chasing.
- Hide Biography: Don’t show user bios when suggesting who to follow, to reduce identity-based sorting.
Main findings
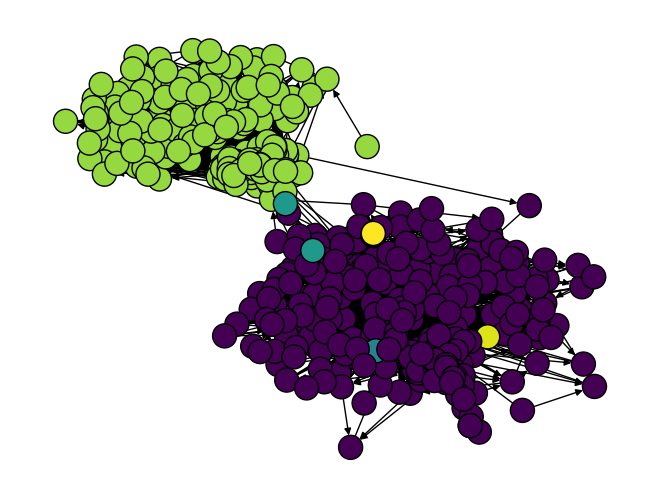
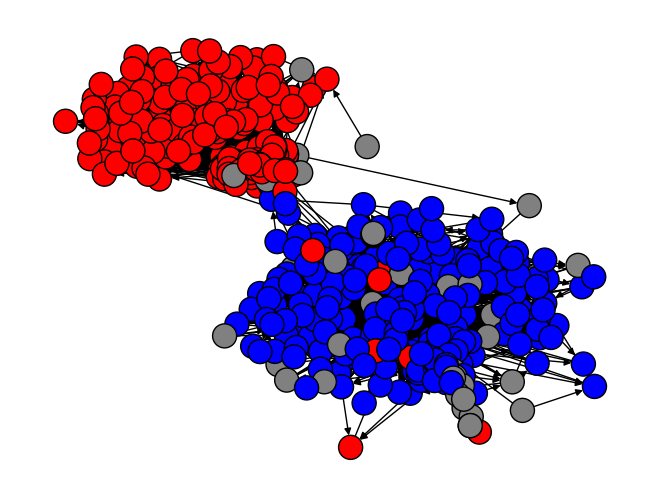
- Even the simple social media model (no fancy recommendation algorithms) produced three big problems:
- Echo chambers: People mostly followed others who shared their political side.
- Attention inequality: A small group of users got most of the followers and reposts.
- “Prism” effect: Politically extreme users got slightly more attention and influence.
What helped, and what didn’t:
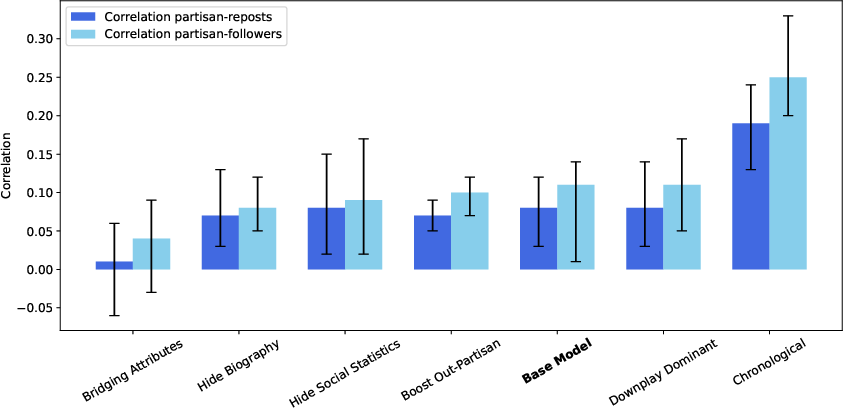
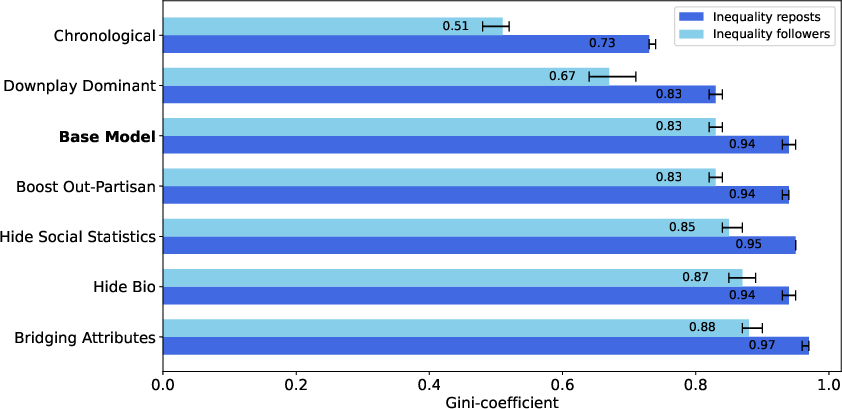
- Chronological feeds reduced attention inequality a lot (fewer superstar accounts), but surprisingly made the “prism” effect worse: extreme content stood out more without algorithmic filtering.
- Downplaying dominant content modestly reduced inequality but didn’t fix echo chambers or the prism effect.
- Boosting out-partisan content changed little. People still mostly engaged with like-minded posts.
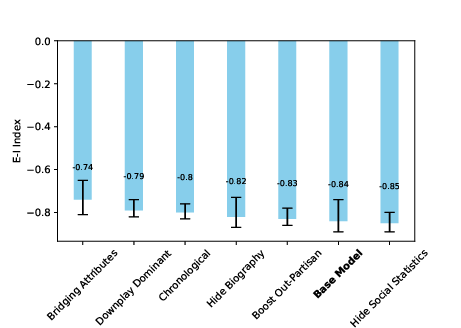
- Bridging Attributes lowered the link between extremism and attention and slightly increased cross-party following, but it also increased inequality (a few “high-quality” posts got most of the attention).
- Hiding social stats increased following and reposting a bit (people had less status bias), but didn’t change the deeper problems.
- Hiding biographies had minimal effects on the overall structure of the network.
In short: some changes helped a little, but none solved the core issues. Often fixing one thing made another problem worse.
Why does this matter?
The study suggests these problems might be baked into how social media works at a deep level. Here’s the key idea: when people repost emotionally charged or partisan content, those posts get seen more; then the authors of those posts get more followers; then their future posts spread even further. That loop—reactive sharing leading to network growth—can naturally build echo chambers, boost extreme voices, and create inequality, even without complex algorithms.
This implies that real reform may require rethinking the foundation of social media: how content spreads, how networks form, and what signals drive visibility—not just tweaking the feed.
What are the limits, and what’s the potential impact?
- Limits: This is a simulation, not a live platform. AI “pretend users” can be biased, and the model doesn’t consider user satisfaction or business needs. Also, running these simulations is expensive and time-consuming.
- Impact: Despite limits, generative social simulation offers a safe, flexible way to test “what if” designs that real platforms won’t try live. The study’s message is clear: small design tweaks alone won’t fix the biggest problems. To build more prosocial platforms—ones that encourage understanding and fair participation—we may need to redesign the core rules that control who sees what and how networks grow.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of unresolved issues and concrete gaps that future research could address.
- External validity and generalizability: The simulation is grounded in U.S. ANES personas and English-language news; it is unclear whether findings hold across cultures, languages, or different political systems and media environments.
- Limited behavior space: The platform includes only posting, reposting, and following; it omits replies/comments, quote-retweets, likes, blocks/mutes, search/hashtags, groups/communities, and DMs, which likely change exposure and network formation dynamics.
- Static attitudes and learning: Agents do not update beliefs, attitudes, or norms over time; the model does not capture persuasion, social influence, or the evolution of affective polarization.
- Activity heterogeneity: Users are selected uniformly at random to act; real platforms have heavy-tailed activity distributions. The impact of realistic activity heterogeneity on inequality and homophily remains untested.
- Initial conditions sensitivity: The starting network and exposure conditions are not systematically varied; robustness to different initial tie structures (e.g., pre-existing social ties, seed elites) is unknown.
- Content modality constraints: Only text-based news headlines are used to seed posts; the effects of images, videos, memes, and multi-modal content on engagement and network growth are unexamined.
- Non-human and adversarial actors: Bots, coordinated inauthentic behavior, spam, and strategic manipulation (e.g., gaming “downplay-dominant” rules) are excluded; intervention robustness to adversarial adaptation is unknown.
- Recommender realism: The “algorithmic amplification” proxy (repost probability) is a coarse stand-in for modern recommender systems; no comparison is made against realistic learning-to-rank, diversity, or fairness-aware recommenders.
- Mechanism identification: The proposed core mechanism—feedback between reactive engagement and network formation—is not isolated via ablation studies or causal tests, leaving its necessity and sufficiency unverified.
- Measurement of “extremity”: Operationalization of partisan extremity is underspecified; it is unclear whether extremity reflects ideological distance, affective language, or moral-emotional content. Validation against human labels is missing.
- Outcome metric scope: Analyses focus on E–I index, Gini coefficients, and simple correlations; other relevant metrics (e.g., modularity Q, assortativity, exposure diversity, reciprocity, centralization, persistence of exposure) are not reported.
- Temporal dynamics: The paper reports end-state summaries; it does not analyze transient regimes, tipping points, or how interventions perform over time (e.g., early vs. late deployment effects).
- Intervention realism and viability: Interventions are “upper bound” and idealized; the trade-offs with user satisfaction, retention, and platform revenue are not measured, leaving practical viability unknown.
- Combined or staged interventions: Only single interventions are tested; interactions, sequencing (e.g., friction + bridging), and dose–response effects are unexplored.
- Content-quality trade-offs: Bridging-attribute re-ranking reduced partisan amplification but increased inequality; how to mitigate this trade-off (e.g., multi-objective optimization) is not explored.
- Chronological feed side-effects: The increase in “prism” correlations under chronological ordering is hypothesized but not causally probed; the specific drivers (e.g., salience effects) remain unclear.
- Fairness and subgroup impacts: Differential effects of interventions across demographic, ideological, or interest subgroups are not analyzed; potential disparate impacts are unassessed.
- Moderation and governance: No content moderation, enforcement (e.g., repeated offenders), or reputation systems are modeled; interactions between interventions and governance policies are unknown.
- Exposure channels: Follow formation is driven by feed exposure and reposts; other discovery channels (search, trending, external links, offline ties) are omitted, potentially biasing network growth dynamics.
- Sensitivity and ablations: Parameter sweeps (e.g., timeline length, follow/repost propensities, news-topic mix) and prompt- or architecture-level ablations are limited; robustness to modeling choices is not established.
- LLM dependence and bias: While three LLMs are tested, systematic auditing for ideological bias, prompt sensitivity, non-stationarity across LLM updates, and their effects on outcomes is lacking.
- Content analysis validation: Use of Perspective API “Bridging Attributes” is not audited for bias or validated on the generated content; it is unclear whether elevated posts are actually more constructive by human judgment.
- Scale and computational limits: Results are shown for 500 agents; whether dynamics (and intervention efficacy) change at larger scales or under different agent-to-content ratios is unknown.
- Domain dynamics and exogenous shocks: The news stream is treated as exogenous and static; the effects of real-time events, crisis spikes, or topic salience shifts on network/pathology formation are untested.
- Real-world benchmarking: There is no quantitative calibration to, or out-of-sample comparison with, empirical platform data (e.g., degree distributions, engagement tails), leaving external validation incomplete.
- Reproducibility over time: LLMs evolve; stability of results across model versions, API changes, and prompt tweaks is not assessed, posing questions for longitudinal reproducibility.
Glossary
- Agent-Based Models (ABMs): Computational frameworks that simulate the actions and interactions of autonomous agents to assess their effects on the system. "generative social simulation -- that embeds LLMs within Agent-Based Models to create socially rich synthetic platforms."
- Attention economies: Systems where human attention is the scarce resource that platforms compete to capture and monetize. "winner-take-all dynamics characteristic of attention economies"
- Attention inequality: Unequal distribution of visibility and engagement among users or content on a platform. "homophily, attention inequality, partisan amplification"
- Bridging algorithms: Ranking strategies designed to surface content that promotes understanding and reduces polarization. "from chronological feeds to bridging algorithms"
- Bridging Attributes: Constructiveness signals (e.g., empathy, curiosity) used to identify and elevate bridge-building content. "Bridging Attributes produced the largest reduction in homophily (â0.74 vs. â0.84 in the base model)"
- Chronological feed: A timeline ordered by the time posts were made, without algorithmic ranking. "Twitterâs chronological feed disseminated less low-quality news than its algorithmic counterpart."
- Communicative action: Exchange oriented toward mutual understanding rather than strategic manipulation. "constructive debate requires communicative (rather than strategic) action"
- Complex systems approach: Modeling perspective focusing on interacting components and emergent behaviors rather than fine-grained calibration. "we adopt a complex systems approach to model design."
- Deliberative democracy: Democratic theory emphasizing inclusive, reasoned discussion as the basis for legitimate decision-making. "undermine deliberative democracy, which requires that all participants have an equal opportunity to contribute to and shape public discourse"
- E–I index: A network measure comparing external (cross-group) to internal (within-group) ties; values near −1 indicate strong homophily. "EâI index (measuring homophily)"
- Engagement metrics: Quantitative signals such as likes, reposts, and follower counts used to infer content popularity or influence. "Engagement metrics have been identified as drivers of inequality of attention, vulnerability to misinformation, and amplification of outrage"
- Generative social simulation: Method that embeds LLMs within ABMs to produce socially rich, synthetic environments for testing interventions. "a novel approach -- generative social simulation -- that embeds LLMs within Agent-Based Models (ABMs)"
- Gini coefficient: A statistic measuring inequality in a distribution, with 0 being equal and 1 being maximally unequal. "The average Gini coefficient for followers is 0.83"
- Homophily: Tendency for individuals to connect with similar others (e.g., co-partisans). "1) political homophily"
- Label-propagation algorithm: Community detection method that assigns nodes to clusters based on label diffusion through the network. "Communities detected by the label-propagation algorithm in a simulated follower network."
- LLMs: AI models trained on vast text corpora to generate and interpret language in context. "This paper addresses this gap using a novel approach -- generative social simulation -- that embeds LLMs within Agent-Based Models (ABMs)"
- Minimal modeling: Strategy that prioritizes simple, general mechanisms over detailed empirical calibration. "Following the tradition of minimal modeling"
- Moral-emotional language: Content expressing moral judgments with strong affect, often increasing virality. "negative and moral-emotional language is more likely to go viral"
- Pearson correlation: Statistic measuring linear association between two variables. "Average Pearson correlation between a user's partisan extremity and their number of followers"
- Perspective API: Tool that scores text on attributes like toxicity and constructiveness, used to inform ranking. "using Perspective APIâs Bridging Attributes"
- Preferential attachment dynamics: Process where popular nodes attract more links, amplifying existing advantages. "This is in line with a preferential attachment dynamics, in which attention attracts attention"
- Power-law dynamics: Heavy-tailed distributions where a small number of items account for most of the mass (e.g., attention). "replicating the power-law dynamics and elite concentration observed on real-world platforms"
- Prosocial interventions: Design changes intended to foster constructive, inclusive, and respectful online interactions. "Can these problems be mitigated through prosocial interventions?"
- Social media prism: Distortion where extreme or sensational content is overrepresented, skewing perceptions of discourse. "creating a ``social media prism'' that distorts political discourse."
- Sociotechnical system: An environment shaped by intertwined social and technical components and feedback loops. "social media as a sociotechnical system shaped by structural and cultural feedback loops"
- Viewpoint diversification: Recommender strategy that increases exposure to opposing perspectives to reduce segregation. "Such ``viewpoint diversification'' strategies have been proposed to broaden exposure to cross-cutting perspectives and reduce ideological segregation"
- Winner-take-all dynamics: Competitive processes where few actors capture most benefits or attention. "digital participation is governed by winner-take-all dynamics characteristic of attention economies"
Practical Applications
Immediate Applications
The following applications can be piloted or deployed now, drawing directly from the paper’s method (generative social simulation) and its measured intervention effects. Each bullet notes relevant sectors and feasibility assumptions.
- Platform “sandbox” for pre-deployment testing of recommender and UX changes
- Sectors: software/social media, academia
- Tools/workflows: Use the released GitHub code to embed LLM agents in ABM scenarios; run counterfactual simulations of feed ranking, follow prompts, and UI changes; monitor E–I index (homophily), Gini (attention inequality), and “prism” correlations (partisan extremity vs. influence) as governance KPIs.
- Assumptions/dependencies: LLM agent behavior approximates user reasoning; persona sampling represents target population; adequate compute budget and MLOps integration; acceptance that results are upper-bound effects rather than ground truth.
- Compliance risk assessments for platform governance
- Sectors: policy/regulation (EU DSA, UK Online Safety Act), platform trust and safety
- Tools/workflows: Generate simulation-based risk reports quantifying polarization/homophily, attention inequality, and amplification of extremes for proposed algorithm changes; attach “discourse health” metrics to compliance filings or internal governance boards.
- Assumptions/dependencies: Regulators or internal governance bodies accept simulation evidence; methods documented and reproducible; independent audit or replication capacity.
- Bridging-attribute re-ranking for comments and replies
- Sectors: media/journalism, community platforms, education
- Tools/products: Apply Perspective API’s Bridging Attributes to re-rank comments toward empathy, curiosity, and reasoning; deploy “constructiveness mode” in comment sections and class forums to reduce partisan amplification and modestly improve cross-partisan ties.
- Assumptions/dependencies: Content scoring accuracy; editorial acceptance of trade-offs (paper finds inequality can increase under bridging); potential bias audits of the scoring model.
- Chronological feed option with guardrails
- Sectors: social media product, UX
- Tools/products: Offer a toggle for reverse-chronological ordering of non-followed content to flatten attention inequality; pair with clear user education and complement with de-amplification of viral content to mitigate the observed increase in “prism” effects.
- Assumptions/dependencies: Willingness to accept potential engagement drops; need to monitor prism score (partisanship–influence correlation) and user satisfaction.
- De-amplification of viral content (down-weight highly reposted posts)
- Sectors: recommender systems, platform integrity
- Tools/products: Invert or soften engagement weighting for non-followed content to reduce winner-take-all dynamics; incorporate into discovery feeds.
- Assumptions/dependencies: Product acceptance of reduced virality; careful tuning to avoid suppressing legitimate public-interest content; minimal observed effect on homophily per paper.
- Experiments hiding social influence cues (follower/like counts)
- Sectors: UX/design, creator tools
- Tools/products: AB test “stat-lite” views that hide or minimize repost/follower counts; track follow/repost behavior and discourse KPIs; offer optional creator dashboards to preserve analytics for professionals.
- Assumptions/dependencies: Paper finds limited structural change but some behavioral shifts; creator community expectations; need for careful rollouts to avoid backlash.
- Standardized “discourse health” dashboards for data teams
- Sectors: data science/analytics, trust and safety
- Tools/workflows: Integrate E–I index, Gini coefficients (followers/reposts), and prism correlations into platform observability; run in both live AB tests and simulation pre-tests.
- Assumptions/dependencies: Reliable partisan/extremity labeling pipeline; ethical review of labeling and measurement; cross-team buy-in.
- Newsroom and civil-society moderation pilots
- Sectors: journalism, NGOs, community moderation
- Tools/products: Pair bridging re-ranking with constructive prompts for contributors (empathy, evidence-based reasoning); use simulation to pre-test moderation rule changes before live deployment.
- Assumptions/dependencies: Editorial standards; volunteer moderator capacity; calibration of prompts to local community norms.
- Academic teaching and research replications
- Sectors: academia, social computing
- Tools/workflows: Use the open-source simulator for coursework and research to test platform interventions, replicate stylized facts (homophily, inequality), and explore theory around reactive engagement and network formation.
- Assumptions/dependencies: Compute resources; transparent reporting of prompts/persona generation; multi-model robustness checks (as the paper did).
- Daily practice guidance for users and community managers
- Sectors: daily life, community management
- Tools/practices: Encourage “bridging behaviors” (empathy, curiosity, justification) in posts and moderation to improve visibility without amplifying outrage; discourage knee-jerk reposts of sensational content to avoid reinforcing elite concentration; educate communities about the limits of cross-partisan exposure alone (per paper, exposure without norms rarely bridges divides).
- Assumptions/dependencies: Community norms and incentives; availability of constructive prompts; awareness campaigns.
Long-Term Applications
These applications require further research, validation, scaling, or foundational redesign, consistent with the paper’s conclusion that core dysfunctions are rooted in feedback loops between reactive engagement and network growth.
- Deliberation-first platform architectures that decouple network growth from reactive sharing
- Sectors: software/social media, civic tech
- Tools/products: Redesign “follow” formation to be driven by curated diversity and topic-based matching rather than reshare exposure; introduce friction to reposts (cool-downs, contextualization prompts); create structured debate rooms with reasoning-centered ranking rather than raw engagement.
- Assumptions/dependencies: Significant product re-architecture; user acceptance; careful UX to maintain satisfaction while curbing outrage-driven virality; rigorous experimentation to verify effects.
- Simulation-based regulation standards and audit ecosystems
- Sectors: policy/regulation, independent audit labs
- Tools/workflows: Establish standards requiring pre-deployment generative social simulations for high-risk algorithm changes; certify third-party labs to run scenario audits; publish “discourse health” KPIs and risk narratives alongside transparency reports.
- Assumptions/dependencies: Methodological validation; governance frameworks for model bias and reproducibility; legal clarity about admissibility of simulation evidence.
- Digital twins of social platforms for continuous governance
- Sectors: platform governance, applied AI
- Tools/products: Integrate live telemetry with generative simulation “twins” to forecast discourse outcomes under candidate changes; use shadow traffic to validate; automate early-warning signals for rising inequality or prism effects.
- Assumptions/dependencies: Secure data access and privacy safeguards; high compute; robust calibration pipelines linking live data to agent personas and behaviors.
- Simulation-as-a-service for complex social systems
- Sectors: enterprise software, public sector
- Tools/products: Offer LLM–ABM simulation stacks to governments, NGOs, and companies to test interventions in online communities, civic platforms, and knowledge ecosystems.
- Assumptions/dependencies: Standard APIs for persona generation, prompt governance, and metrics; affordability and ease of use; domain-specific validation.
- Cross-domain intervention design for health and climate communication
- Sectors: healthcare, environment/climate, education
- Tools/products: Use generative social simulation to test misinformation-curbing strategies (e.g., bridging re-ranking, friction on reshares, empathy prompts) in health forums and climate discussions; develop domain-specific metrics for constructiveness and trust.
- Assumptions/dependencies: Domain-specific personas and content datasets; expert oversight to avoid harmful bias; ethical approvals.
- Agent integrity and interpretability R&D
- Sectors: AI research, platform safety
- Tools/workflows: Develop constrained, auditable LLM agents for social simulations (bias mitigation, transparency of decision rules, controllable persona attributes); publish benchmarks for realism and reliability in social reasoning.
- Assumptions/dependencies: Advances in interpretability and controllability; open evaluation datasets; multi-model comparisons.
- Sector-wide “Discourse Health KPI” standardization
- Sectors: industry consortia, policy
- Tools/products: Formalize a shared KPI suite (E–I index, follower/repost Gini, prism correlation, constructiveness rates) for cross-platform reporting; align on measurement protocols and validation.
- Assumptions/dependencies: Consensus-building; independent stewardship; calibration against real-world outcomes.
- Education and civic literacy programs
- Sectors: education, civil society
- Tools/products: Interactive labs using generative simulations to teach dynamics of polarization, attention inequality, and algorithmic trade-offs; citizen curricula on constructive online engagement.
- Assumptions/dependencies: Curriculum integration; instructor training; accessible platforms and compute.
- Creator economy redesign to reward constructive norms
- Sectors: creator platforms, monetization
- Tools/products: Shift monetization and recommendation incentives toward constructive content (bridging attributes, evidence-based posts); experiment with “deliberation badges” or trust signals; decouple payout mechanics from raw engagement.
- Assumptions/dependencies: Business model shifts; robust, fair constructiveness scoring; creator buy-in and fairness assurances.
- Multi-stakeholder governance models for platform reforms
- Sectors: platform governance, policy
- Tools/workflows: Co-design reforms with users, creators, civil society, and regulators using simulation-driven deliberations; run participatory scenario planning to balance engagement, equity, and discourse health.
- Assumptions/dependencies: Institutional capacity; transparent processes; simulation literacy among stakeholders.
These applications are grounded in the paper’s core finding that reactive engagement drives network formation and visibility, which in turn reinforces homophily, inequality, and the amplification of extreme content. Immediate steps can mitigate specific harms (flatten inequality, elevate constructive content), while durable change will likely require architectural shifts, validated simulation standards, and new incentives aligned with deliberative norms.
Collections
Sign up for free to add this paper to one or more collections.

