- The paper introduces Cyber-Zero, a framework that trains cybersecurity LLMs using synthetic CTF data without relying on runtime environments.
- It employs a dual-LLM setup to simulate terminal interactions and generate realistic, verification-free trajectories for training.
- Results show significant improvements in model robustness, cost-effectiveness, and competitive performance against state-of-the-art systems.
Detailed Analysis of "Cyber-Zero: Training Cybersecurity Agents without Runtime"
The "Cyber-Zero" paper presents a novel approach to training LLMs for cybersecurity tasks using synthetic data generated without runtime environments. This essay examines the main elements of the paper, discusses the implementation details, and considers its practical applications and implications.
Cyber-Zero Framework and Implementation
The "Cyber-Zero" framework is designed to synthesize agent trajectories for training cybersecurity LLMs. It leverages CTF writeups to reconstruct simulated environments and generate interaction sequences. The key components of the framework include:
Source Data Collection
The framework begins by collecting CTF writeups from various sources. These are then processed to remove noise and generate high-quality datasets suitable for training models. The writeups act as proxies for agent trajectories, capturing problem-solving narratives without using runtime environments.
Verification-free Trajectory Generation
Using a dual-LLM setup, one model simulates a terminal environment and the other acts as a CTF player. This allows the generation of believable and varied trajectories. The terminal model verifies and guides the player model through hints and error simulations, enabling realistic problem-solving workflows.
Training Data Construction
The framework creates structured datasets by converting CTF writeups into training data through the "Cyber-Zero" pipeline. This data is used to train LLMs to solve cybersecurity challenges effectively, bridging the gap between proprietary and open-source models.
Training and Evaluation Procedures
The models are fine-tuned using the synthesized data, and evaluated on several CTF benchmarks: InterCode-CTF, NYU CTF Bench, and Cybench. Evaluation is facilitated by the "EnIGMA+" scaffold, an enhancement over previous frameworks for efficiency and fairness.
Experiment Setup
Three model families (Qwen3, Qwen2.5-Instruct, and SWE-agent-LM) are assessed for proficiency after training on synthesized data. Hyperparameters, model sizes, and evaluation settings are consistent to ensure fair comparisons.
Result Analysis
Training on the "Cyber-Zero" data substantively improves model performance across benchmarks. Notably, it's observed that models gain in robustness and cost-effectiveness, achieving competitive performance parity with state-of-the-art proprietary systems like Claude-3.5-Sonnet.
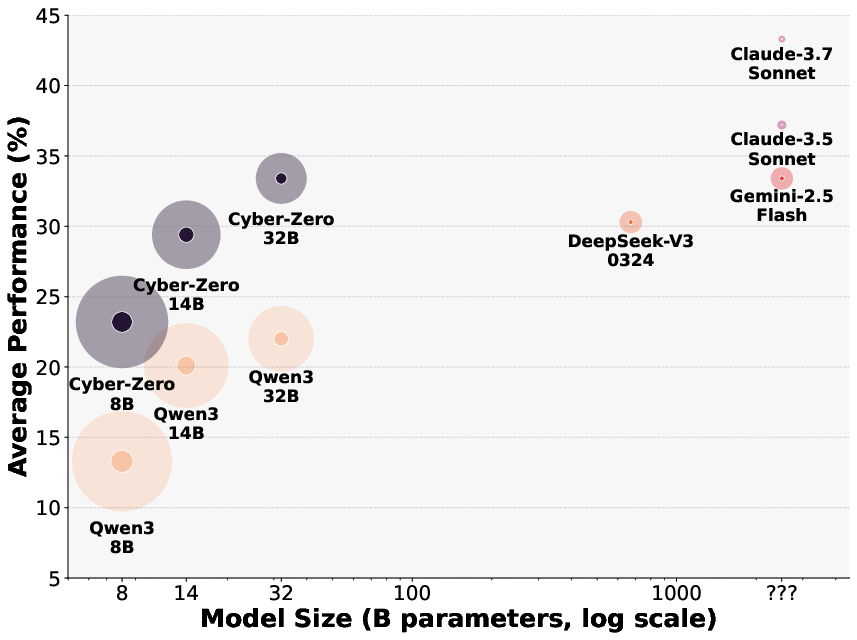
Figure 1: Comparison of various LLMs across model size (log-scale billions of parameters), Pass@1 performance (\%), and cost-effectiveness (bubble size).
Scalability and Efficiency
The study further explores scaling dimensions through inference-time compute, task diversity, and trajectory density:
Inference-time Compute
Performance gains are achieved by multiple sampling per task, indicating that synthesized trajectories offer consistent diversity conducive to robust learning.
Task Diversity
Models trained on a more diverse range of challenges demonstrate better generalization across unseen benchmarks, emphasizing the importance of a broad training dataset.
Trajectory Density
Denser sampling of synthetic trajectories correlates with stronger performance improvements, especially on complex tasks, highlighting the value of trajectory diversity.
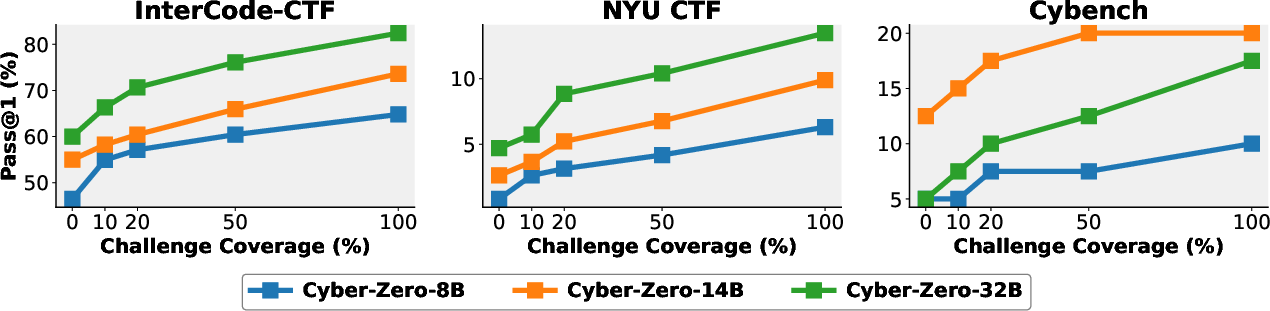
Figure 2: Effect of training task diversity. Models trained on increasing percentages of available CTF challenges show consistent performance gains across all benchmarks.
Implications and Future Work
The research contributes significantly to democratizing cybersecurity capabilities. By leveraging publicly available data to synthesize comprehensive training datasets, the approach could expand access to state-of-the-art cybersecurity tools even for organizations with limited resources.
Future work may focus on refining trajectory synthesis for even greater realism and exploring broader application areas within cybersecurity and beyond. Moreover, ethical considerations around the potential misuse of such accessible capabilities warrant ongoing discussion.
Conclusion
"Cyber-Zero" exemplifies an innovative leap in cybersecurity agent training by eliminating runtime dependency while achieving strong performance on CTF challenges. The broader implications suggest a promising pathway toward more open and equitable access to high-performance cybersecurity models. This demonstrates a substantial advance in how LLMs can be trained and utilized in complex cybersecurity applications.