- The paper presents a novel RL approach that significantly enhances LLM agents in cryptographic CTF challenges, achieving a Pass@8 improvement from 0.35 to 0.88.
- It leverages the procedurally generated Random-Crypto dataset to enable structured, multi-step inference and accurate tool-augmented problem solving.
- Results demonstrate robust generalization with notable performance gains across both cryptographic and non-cryptographic tasks, including external benchmarks like picoCTF.
Improving LLM Agents with Reinforcement Learning on Cryptographic CTF Challenges
Introduction
The paper "Improving LLM Agents with Reinforcement Learning on Cryptographic CTF Challenges" (2506.02048) introduces a methodology to enhance LLM agents through the application of Reinforcement Learning (RL) on cryptographic Capture The Flag (CTF) challenges. The authors present Random-Crypto, a procedurally generated CTF dataset, which serves as an ideal RL testbed for cryptographic reasoning. The dataset is designed to accommodate structured multi-step inference, precise validation, and reliance on computational tools. The approach leverages the Group Relative Policy Optimization (GRPO) algorithm to fine-tune a Python tool-augmented Llama-3.1-8B model, achieving notable improvements in generalization across cryptographic and non-cryptographic tasks.
Methodology
Random-Crypto Dataset
Random-Crypto encompasses a diverse set of over 5,000 cryptographic challenges derived from 50 algorithmic families. These procedurally generated tasks provide an abundant source of training data, enabling LLM agents to improve their cryptographic reasoning abilities. Each challenge instantiates a multi-stage process, selecting a cryptographic subtype, randomizing parameters, and embedding a narrative generated by an LLM. The dataset ensures verifiable outcomes, making it an effective tool for RL-based training, particularly in encouraging agents to develop multi-step logical inference competencies.
Reinforcement Learning Approach
The paper employs GRPO to adapt the Llama-3.1-8B model within a secure Python execution environment. This methodology notably increases the model's Pass@8 metric on novel tasks from 0.35 to 0.88. The approach supports structured, tool-augmented problem solving using a flexible interface for algorithmic interaction. GRPO operates by rewarding models for correct solutions and efficient decision-making processes, fostering improvements in reasoning capabilities and tool-use efficiency across a range of cryptographic challenges.
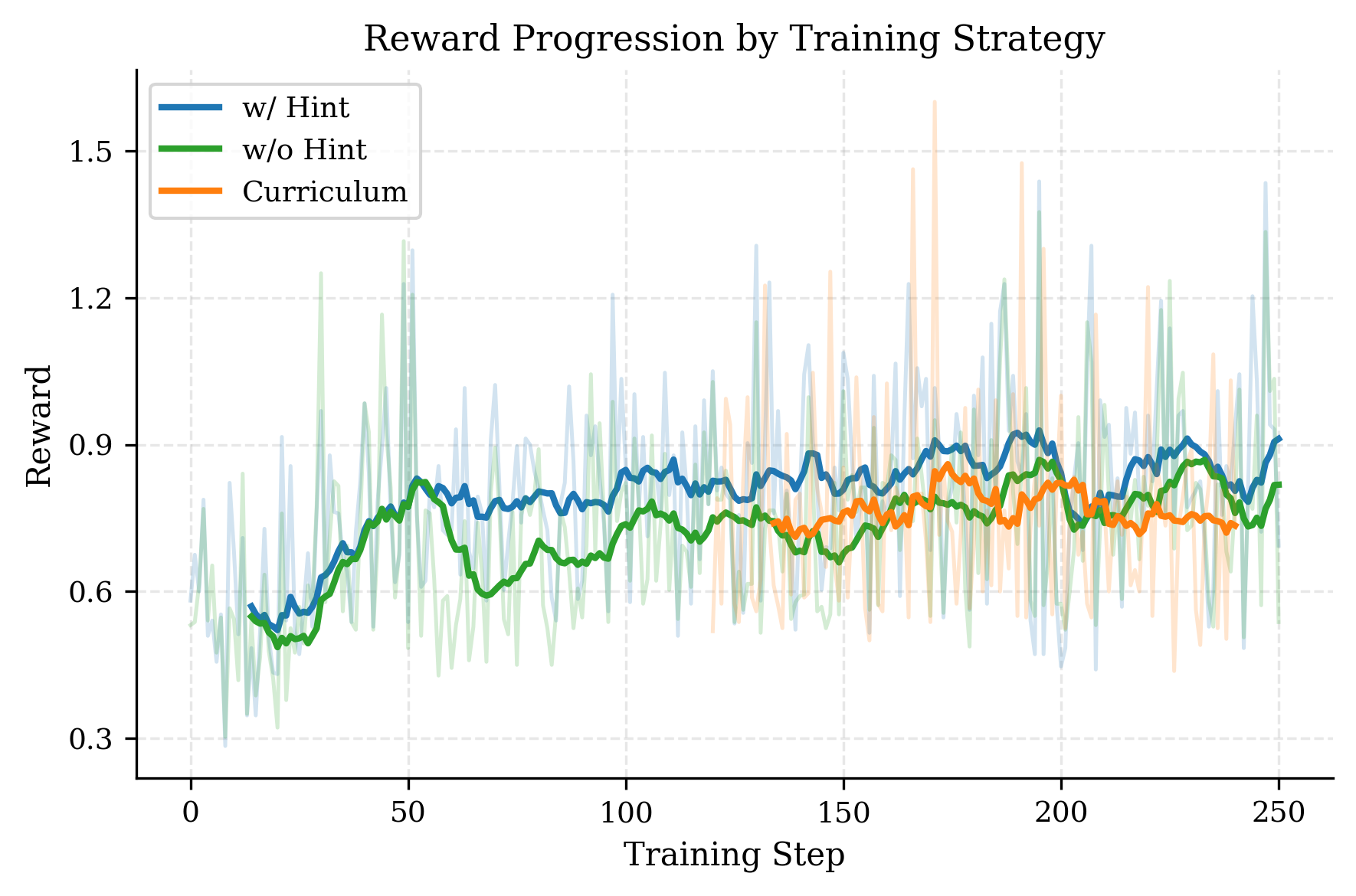
Figure 1: Reward gained during training. The bright lines mark the average, while the shaded lines mark the actual data points. One data point shows the average of all rewards given out in a training step to all benchmarks.
Results
The Random-Crypto dataset yields significant performance gains across evaluated benchmarks, with RL-fine-tuned models outperforming baseline configurations. The trained agent demonstrates notable Pass@8 improvements, and the gains extend to external datasets like picoCTF and AICrypto MCQ. This generalization signals the robustness of strategies acquired through RL, underscoring the potential for cross-domain applicability of the skills learned.
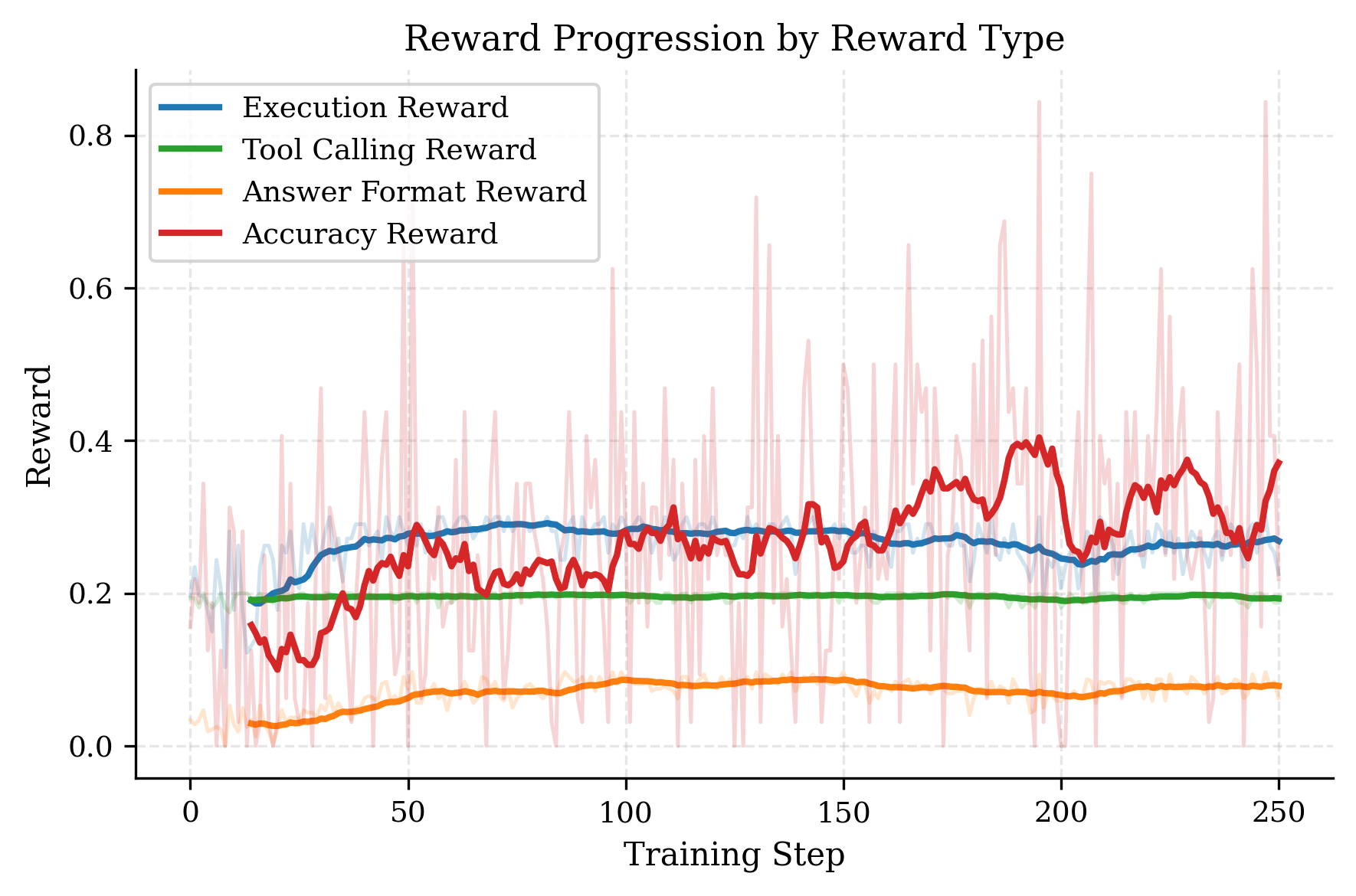
Figure 2: Reward types gained during training. The bright lines mark the average, while the shaded lines mark the actual data points. One data point shows the average of all rewards given out in a training step to all benchmarks. We can observe the biggest threefold improvement in the accuracy of the model, indicating successful challenge resolution.
Applicability and Implications
The research offers evidence that RL can substantially enhance the problem-solving capabilities of LLM agents in critical domains, such as cybersecurity. The integration of RL not only optimizes model outputs but also cultivates internal problem-solving routines. The Random-Crypto dataset, with its emphasis on cryptographic reasoning, positions itself as a pivotal resource in developing adaptable and intelligent cybersecurity models. The adaptation strategies learned by models can support varied security tasks, promoting the integration of LLM agents within real-world defensive and offensive security frameworks.
Conclusion
The paper validates the efficacy of RL in enhancing LLMs for security-sensitive tasks. Procedurally generated challenges via Random-Crypto facilitate scalable and agent-centric training environments. The improvements realized underscore the feasibility of developing RL-fine-tuned agents with generalized problem-solving capabilities. This work lays a foundational framework for advancing LLM agents' application in cybersecurity domains, promoting the exploration of RL strategies in developing robust cybersecurity defense and penetration testing systems. Future research may further refine these methodologies, extending their applications across broader task sets and refining the integration of real-time tool interactions for enhanced model performance.