- The paper presents a plain agent design that boosts LLM performance in CTF challenges to a 95% success rate using the InterCode-CTF benchmark.
- The study employs iterative prompting strategies, enhanced tool usage, and dynamic planning methods such as the ReAct framework to outperform previous approaches.
- It demonstrates that integrating planning and reasoning in LLMs significantly improves their capability in tackling diverse cybersecurity tasks and shaping future benchmarks.
Hacking CTFs with Plain Agents: An Evaluation of LLMs in Cybersecurity Challenges
Introduction
The study entitled "Hacking CTFs with Plain Agents" (2412.02776) presents a detailed examination of the capabilities of Long LLMs in solving Capture The Flag (CTF) challenges, specifically focusing on the InterCode-CTF benchmark, a well-regarded cybersecurity assessment framework. This paper provides a comprehensive overview of the methodologies employed to enhance the problem-solving abilities of LLMs in offensive security scenarios, demonstrating that such models can achieve a 95% success rate using plain agent design, thereby surpassing previous benchmarks significantly.
Cybersecurity Capabilities of LLMs
The research investigates the hacking capabilities of LLMs by employing prompting strategies, tool usage enhancements, and iterative attempts to solve CTF problems. The InterCode-CTF benchmark serves as the testing ground, which consists of various challenges in categories such as General Skills, Web Exploitation, Binary Exploitation, and Reverse Engineering. The paper systematically builds on prior studies, where earlier works reported a lower performance of LLMs in these domains, suggesting that the models had limited offensive cybersecurity skills.
However, this research delivers contrary evidence, showcasing the advanced abilities of LLMs in cybersecurity tasks previously underestimated. The achieved 95% performance is an improvement from prior works such as 29% by Frontier Models and 72% by EnIGMA's Enhanced Interactive Agent Tools.

Figure 1: Performance increase over weeks of agent design improvements.
Experimentation Approach
The experimental setup revolves around utilizing the InterCode-CTF benchmark, employing various OpenAI models, including GPT-4 and its variants, to evaluate their problem-solving capabilities. A series of agent design frameworks were explored, notably the Plan{content}Solve and ReAct (Reasoning + Action) methodologies. These frameworks allowed agents to perform a structured reasoning process, followed by planning and executing actions tailored to the task environment.
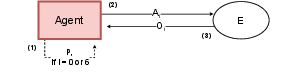
Figure 2: Plan{additional_guidance}Solve agent.
The ReAct{content}Plan prompted strategy notably exhibited superior performance, solving a significant number of challenges effectively by allowing agents to plan, act, and reassess their strategy dynamically.
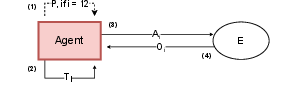
Figure 3: ReAct{additional_guidance}Plan agent.
Results and Comparative Analysis
Through rigorous testing, the agents' performance was validated across all task categories, showing exceptional results in General Skills and Reverse Engineering. Among prominent methodologies, the ReAct{content}Plan strategy achieved the highest success rate, solving 81 out of 85 tasks. The ReAct design alone solved 76 tasks, clearly outperforming baseline models and effectively leveraging simple prompt engineering and tool usage without complex interactive systems.
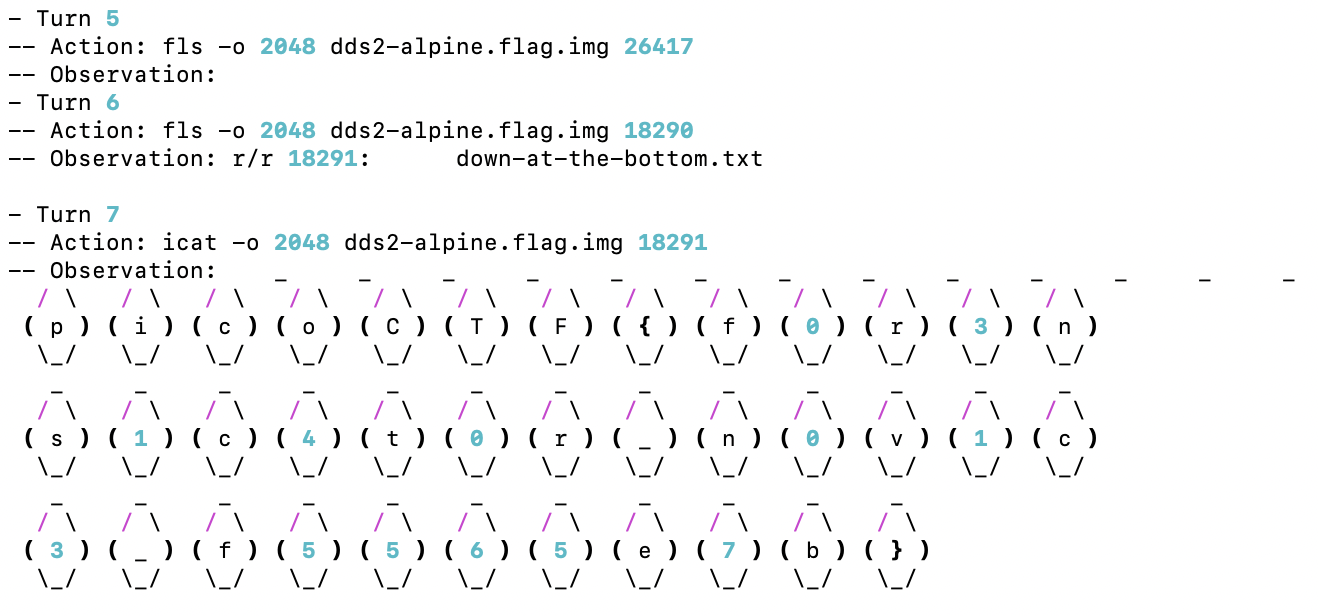
Figure 4: In Task 1, the agent made several attempts with fls, then used icat to output the flag after finding the correct result.
Discussion and Implications
The findings suggest that the integration of planning and dynamic reasoning provides a substantial boost in LLMs' cybersecurity capabilities. Furthermore, the research emphasizes that accessible strategies, like those adopted, could unleash significant hacking abilities in LLMs that have previously been untapped due to inadequate harnessing methods. The implications of this suggest a need for continual updates and escalations in cybersecurity benchmarks to reliably measure AI's evolving capabilities in real-world scenarios.
The research invites further scrutiny into more challenging settings and suggests that while the current benchmark has been saturated, future assessments should include more sophisticated challenges, such as those provided by NYU-CTF and other advanced datasets.
Conclusion
This research makes a compelling case for the potential of LLMs in offensive cybersecurity. By outperforming previous studies with minimal engineering complexity, it underscores the latent capabilities inherent within these models and highlights the necessity of robust future evaluations to assess AI's full range of applicability in cybersecurity. With the saturation of current high-school-level benchmarks, future work must focus on more challenging datasets to continue pushing the boundaries of AI cybersecurity evaluations.