- The paper introduces ARC-Hunyuan-Video-7B that integrates visual, audio, and text inputs for temporally-aware structured video comprehension.
- It employs a multi-stage training regimen, including ASR warm-up and reinforcement learning fine-tuning, to achieve fine-grained temporal grounding and captioning.
- Quantitative evaluations on ShortVid-Bench demonstrate superior performance in real-world video understanding, outperforming several baseline models.
ARC-Hunyuan-Video-7B: Structured Video Comprehension of Real-World Shorts
Introduction
ARC-Hunyuan-Video-7B addresses the increasingly critical need to effectively comprehend user-generated short videos, which are prevalent on social media platforms like TikTok and WeChat. The brief, fast-paced nature of these videos, combined with their rich visual and audio components, poses distinct challenges for traditional multimodal models. Existing models often fall short in delivering temporally structured and deep video comprehension capabilities necessary for advanced video-centric applications including search, recommendation, and intelligent services.
The ARC-Hunyuan-Video model introduces Structured Video Comprehension by integrating visual, audio, and text signals to achieve a detailed and temporally aware understanding of video content. This capability enables tasks such as multi-granularity timestamped video captioning, summarization, open-ended question answering, and temporal grounding, addressing the need for sophisticated multimodal reasoning.
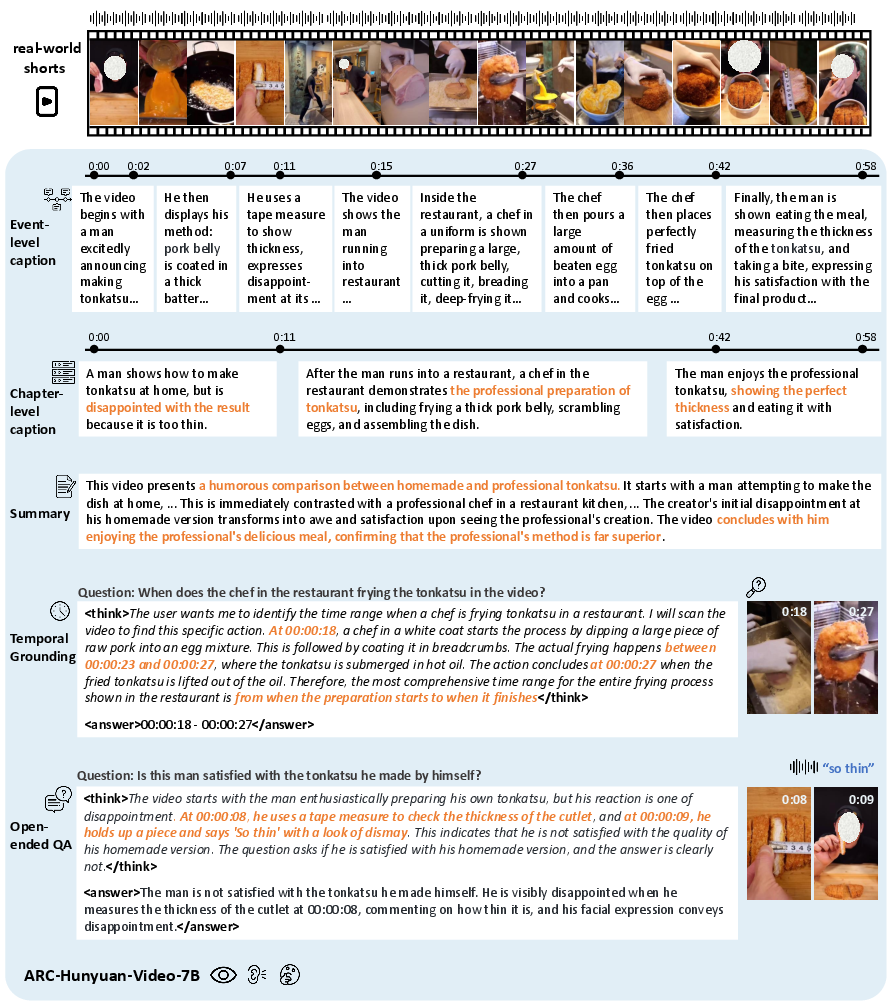
Figure 1: Model capabilities of -7B, which supports multi-granular timestamped captioning (output time span and corresponding description), summarization, temporal grounding, and open-ended question answering through integrating and reasoning over both visual and audio cues in the user-generated short videos.
Model Architecture
ARC-Hunyuan-Video is based on the Hunyuan-7B Vision LLM (VLM) and includes enhancements for structured video comprehension. Key components of the architecture include an audio encoder for synchronization of visual and audio inputs and the use of timestamp overlay mechanisms on visual frames to ensure temporal awareness.
The model architecture consists of the following:
- Visual Encoding: Videos are sampled at one frame per second (fps), with up to 150 frames used for longer videos. Each frame receives a timestamp in HH:MM:SS format to aid in temporal localization. These frames are processed by a Vision Transformer (ViT) encoder.
- Audio Encoding: Audio data is processed using OpenAI's Whisper audio encoder, which segments audio into 30-second chunks aligned with visuals for simultaneous processing.
- Visual-Audio Synchronization: A parameter-free strategy adapts synchronization based on video duration, fusing audio and visual tokens for temporally aligned multimodal embeddings.
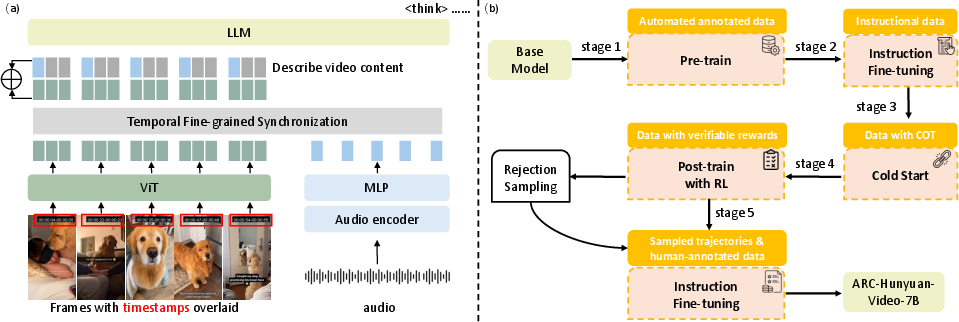
Figure 2: (a) Model architecture. Built upon the Hunyuan-7B VLM, we incorporate an audio encoder with fine-grained visual-audio synchronization to obtain temporally aligned multimodal inputs. Timestamps are overlaid on visual frames to provide the model with temporal awareness. (b) Training stages including pre-training, instruction fine-tuning, cold start initialization, RL post-training and final instruction fine-tuning using high-quality human-annotated data and trajectories selected via rejection sampling.
Methodology
ARC-Hunyuan-Video's development involved a multi-stage training regimen leveraging an extensive annotation pipeline. The automated bootstrapped annotation process extracts timestamped audio, generates frame-based descriptions, and synthesizes meta-information via an LLM, ultimately refining annotations through iterative improvement.
Pre-training stages:
- Warm-up with ASR: Focuses on adapting the model to handle audio inputs alongside visual understanding capabilities.
- Multimodal integration: The model undergoes full multimodal training with next-token prediction, freezing encoder parameters to maintain feature extraction while updating adapter layers and LLM core.
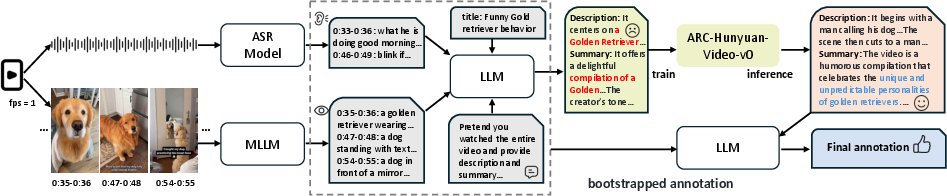
Figure 3: Our automated bootstrapped annotation pipeline for pre-training. It extracts timestamped speech via ASR model and frame-level descriptions via MLLM; these, along with meta information (e.g., title), are input to an LLM for initial video annotation. The annotated data is used to train an initial version of the model, whose inference results are further integrated to produce the final annotations.
Post-training
Pilot experiments demonstrated the benefits of optimizing comprehension through reinforcement learning (RL), particularly with tasks like temporal grounding and multiple-choice question answering which offer clear reward signals.
The post-training regime includes:
- Initial Instruction Fine-tuning: Focuses on aligning the model with instruction-based tasks using a diverse dataset.
- Cold Start Initialization: Establishes a reasoning foundation across tasks through CoT prompting.
- Reinforcement Learning with GRPO: Fine-tunes the model on verifiable tasks, refining its ability to handle subjective data.
- Final Instruction Fine-tuning: Integrates high-quality human-annotated trajectories, leveraging the enhanced understanding from previous training stages.
Experiments
Qualitative evaluations illustrate ARC-Hunyuan-Video's superior capabilities in joint audio-visual reasoning, fine-grained temporal grounding, and thematic understanding across varied video scenarios.

Figure 4: An example of -7B. Given an instructional short video, our model can accurately identify and summarize the content of each step along with the corresponding time spans.
Quantitative evaluations show that the model achieves outstanding results on the ShortVid-Bench, attesting to its ability to manage real-world video comprehension with remarkable efficiency and accuracy, outperforming several baseline models.

Figure 5: A qualitative comparison between baseline models and our model in understanding short videos with rich visual information.
Downstream Applications
The fine-tuning of specific tasks like brief summaries, detailed summaries, and extended browsing words illustrates ARC-Hunyuan-Video's adaptability to real-world applications such as video retrieval and recommendation systems (Figure 6). These applications demonstrate significant improvements in user interaction metrics and experience quality post-deployment.

Figure 6: Demonstration of -7B's versatility through minimal fine-tuning for various downstream applications.
Conclusion
ARC-Hunyuan-Video sets a new standard for structured video comprehension, providing a foundation for sophisticated AI-driven video services. Its ability to integrate multimodal data with deep reasoning capabilities makes it a versatile tool for both research and industrial applications, enhancing the comprehensiveness and user engagement in video-centric platforms.
This work not only pushes the boundaries of video understanding but also opens doors for further research in the domain, aiming to refine and expand the capabilities of structured video comprehension models.

