- The paper introduces DARAS, a deep learning framework that directly synthesizes room impulse responses from reverberant speech using dynamic segmentation and audio-room feature fusion.
- It leverages a CNN-based audio encoder, a Mamba SSM for blind room parameter estimation, and a hybrid cross-attention module to significantly enhance accuracy and reduce inference time by over 90%.
- Empirical evaluations on diverse real and simulated datasets demonstrate DARAS’s superior fidelity and real-time potential for applications in AR/VR, speech enhancement, and spatial audio rendering.
Deep Room Impulse Response Estimation via Dynamic Audio-Room Acoustic Synthesis
Introduction and Motivation
Accurate estimation of Room Impulse Responses (RIRs) is central to acoustic modeling tasks such as speech enhancement, ASR robustness, and audio rendering for AR/VR systems. Traditional blind estimation approaches—centered on inferring discrete acoustic parameters or relying on indirect signal processing hypotheses—demonstrate limited accuracy and adaptability in complex real-world spaces. The "DARAS: Dynamic Audio-Room Acoustic Synthesis for Blind Room Impulse Response Estimation" (2507.08135) paper introduces a deep learning architecture that directly estimates realistic RIRs from monaural reverberant speech by synthesizing both audio and room acoustic features and adaptively reconstructing the temporal structure of reverberation.
DARAS System Overview
DARAS employs a four-stage pipeline:
- Deep Audio Encoder: A CNN-based module that extracts high-dimensional nonlinear latent features from input reverberant speech.
- MASS-BRPE Module: Utilizes a Mamba-based state space model (SSM) for blind self-supervised estimation of essential room acoustic parameters and features.
- Hybrid-Path Cross-Attention Feature Fusion: Integrates audio and room parameter representations through parallel cross-attention mechanisms for robust reverberation-aware embeddings.
- Dynamic Acoustic Tuning (DAT) Decoder: Segments and independently models early reflections and late reverberation, driven by dynamically estimated boundary points to synthesize authentic RIRs.
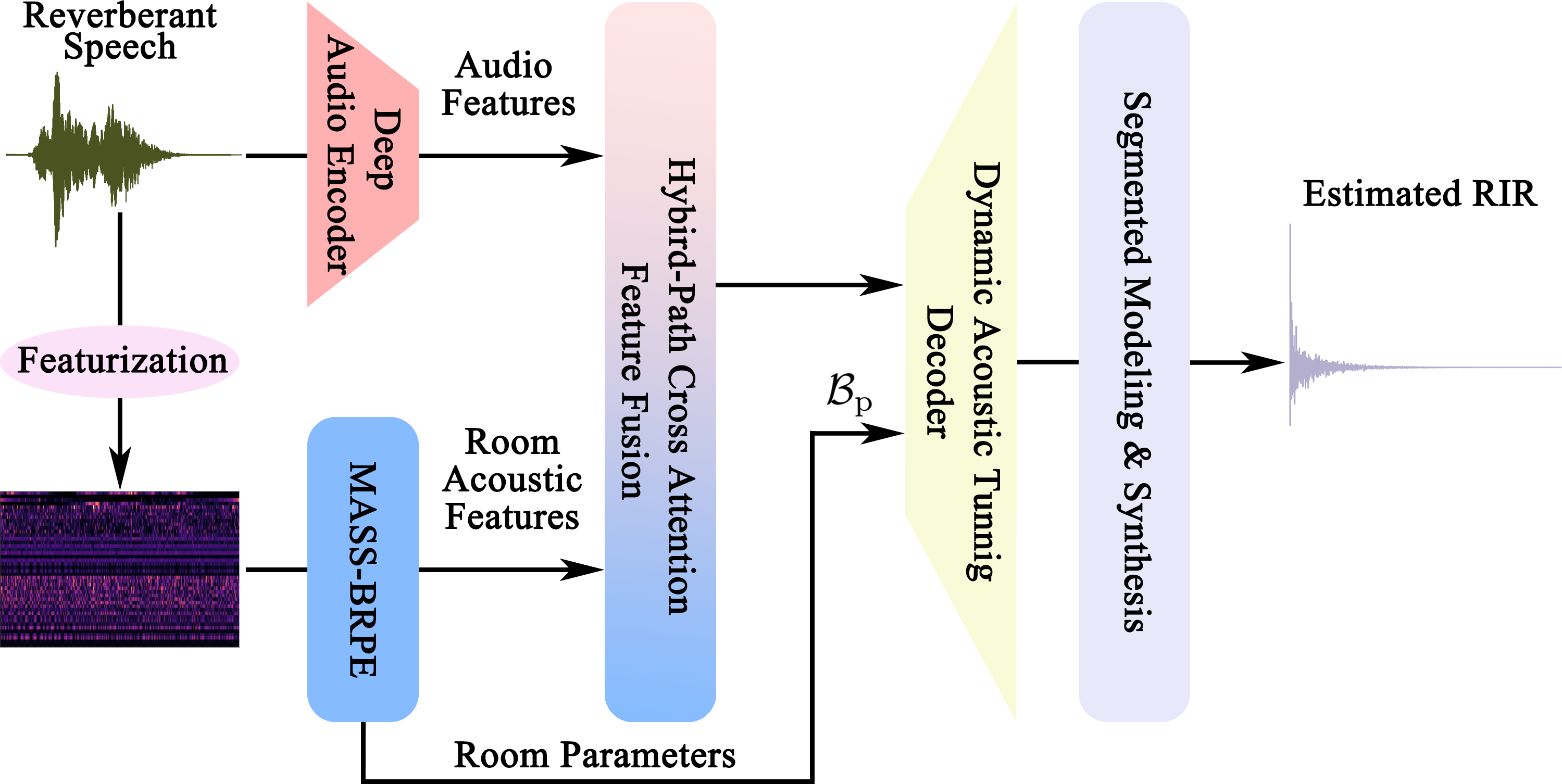
Figure 1: Overview of the DARAS model, illustrating the four-stage pipeline for blind RIR estimation from monaural reverberant speech.
Deep Audio Encoder: Nonlinear Feature Representation
The deep audio encoder leverages stacked convolutional blocks, batch normalization, and PReLU activations using residual connections to avoid vanishing gradients. Feature dimensionality is progressively increased (up to 512 channels) and finally compressed into a 128-dimensional representation of time-frequency audio features. Compared with shallow encoders, this architecture dramatically enhances representation capacity, addressing the sparsity and transient structure inherent to RIR signals.
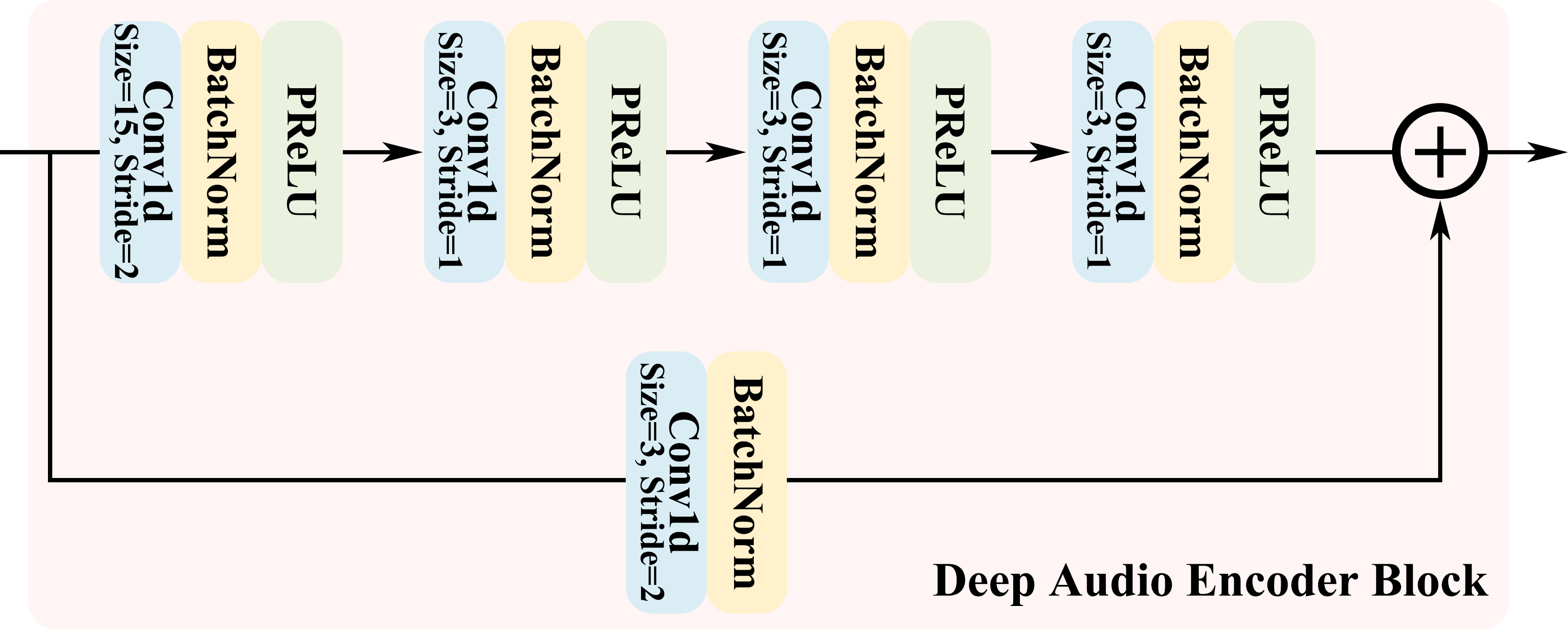
Figure 2: Architecture of the deep audio encoder block showing efficient nonlinear latent feature extraction.
Mamba-based Self-Supervised Room Parameter Estimation (MASS-BRPE)
MASS-BRPE replaces transformer-based (pure attention) architectures with bidirectional Mamba SSMs to estimate parameters including room volume (V), reverberation time (RT), and boundary point (Bp) between early and late reverberation. It processes multi-resolution Gammatone spectrogram features, efficiently capturing both magnitude and phase information. A self-supervised patch prediction regime (analogous to masked audio modeling) is used for pretraining, and fine-tuning adapts dimensions for discriminative and generative tasks.
Numerically, MASS-BRPE achieves superior estimation consistency with Pearson correlation coefficients (ρ) above 0.95 (RT, Bp), and inference time is reduced by over 90% (0.0768s vs. the baseline 0.8005s), with GPU memory cut by over half compared to transformer-based models.
Hybrid-Path Cross-Attention Feature Fusion
To achieve high-fidelity reverberation-aware feature integration, DARAS implements a parallel-path fusion mechanism. One path applies cross-attention from static room features (volume, RT) to dynamic audio features, focusing on global interaction guided by learnable projections and multi-head attention; the other enhances room acoustic features with feed-forward modules. MLPs align dimensions and concatenate fused outputs for final representation. Ablation experiments demonstrate a ~11–14% improvement in STFT loss and MAE over naive feature fusion approaches, confirming the necessity of deep multi-modal interaction.
Dynamic Acoustic Tuning Decoder
The DAT decoder adaptively segments RIRs based on estimated boundary points (Bp) rather than fixed heuristics (commonly 50ms). It utilizes FiLM-based conditional blocks and GAN-TTS inspired upsampling to synthesize early reflections and multi-path late reverberation (filtered noise signals modulated by learned time-domain masks). Empirically, dynamic boundary segmentation offers 6.1% performance gain in STFT loss, mitigating modeling error in environments with diverse geometry or absorption.
Experimental Results and Analysis
DARAS is extensively validated across seven real-world RIR datasets and augmented simulated rooms, covering broad geometric and acoustic distributions. Models are tested on unseen rooms to rigorously assess generalization. Multiple metrics (multi-resolution STFT, MAE, correlation, and error rates for RT and DRR) confirm DARAS’s superiority:
- On blind RIR estimation, DARAS achieves STFT loss of 1.3695 (vs. baseline Dbre 1.6643, FiNS 1.8342), with RT and DRR correlation (ρ) at 0.93 and 0.78, respectively.
- Subjective MUSHRA tests with 30 listeners show DARAS is rated perceptually closest to true reverberation, significantly outperforming all baselines with padj≪0.0001.
- Visualization of time-domain waveforms and spectrograms demonstrates that DARAS preserves both high-frequency detail in direct sound and decay structure in late reverberation, matching real measurements closely and outperforming competitors in both transient and noise-like regions.
Implications and Future Directions
DARAS advances blind RIR estimation toward real-use applicability in AR/VR, dereverberation, and spatial audio rendering, reducing annotation overhead and improving robustness. Contradicting prior beliefs, it demonstrates that integrating discriminative room parameter estimation with deep feature fusion and dynamic temporal segmentation is necessary for authentic sound field synthesis from reverberant speech alone. Strong computational efficiency and inference speed (enabled by the Mamba SSM) support real-time deployment scenarios.
Practically, this approach enables scalable non-intrusive acoustic characterization and realistic auralization without environmental measurement equipment. Theoretically, it opens further study into hybrid sequence models for room acoustics, fusion with visual or geometric modalities, and extension to multi-channel or binaural RIR prediction. Joint optimization with microphone/source calibration and integration with diffusion models may further enhance generalization and fidelity [Lemercier et al., 2025 unsupervised].
Conclusion
DARAS provides an effective framework for blind RIR estimation by uniting deep nonlinear audio feature extraction, efficient room parameter inference via Mamba SSMs, and advanced cross-attention-based multimodal fusion. Dynamic acoustic tuning achieves realistic segmentation and synthesis of RIRs, equaling the perceptual and objective qualities of measured responses in real environments. Future research should focus on integrating environmental visual data, source/mic responses, and evaluating generalization for new room types.

