- The paper introduces differentiable artificial reverberation models that enable end-to-end training by replacing non-differentiable IIR filters with FIR filters using a frequency-sampling method.
- It implements three DAR models (FVN, AFVN, and DN) and leverages a convolutional encoder with multi-scale spectral loss for robust reverberation parameter estimation.
- Empirical evaluations using objective metrics and subjective listening tests demonstrate improved estimation accuracy, reduced computational overhead, and enhanced perceptual quality.
Differentiable Artificial Reverberation: A Comprehensive Overview
The paper "Differentiable Artificial Reverberation" (2105.13940) investigates the integration of digital signal processing (DSP) techniques with deep learning to enhance artificial reverberation (AR) models. By introducing differentiable artificial reverberation (DAR) models, the authors aim to facilitate end-to-end training of neural networks for parameter estimation in AR applications. This essay provides an in-depth analysis of the methodologies, evaluation, and implications of this research, focusing on its technical contributions and future potential.
Methodologies and Implementations
Differentiable Artificial Reverberation Models
The authors propose three DAR models: Filtered Velvet Noise (FVN), Advanced Filtered Velvet Noise (AFVN), and Delay Network (DN). These models replace infinite impulse response (IIR) components with finite impulse response (FIR) filters using a frequency-sampling method. This transformation allows for efficient training on parallel processors such as GPUs by eliminating the bottlenecks associated with IIR filters.
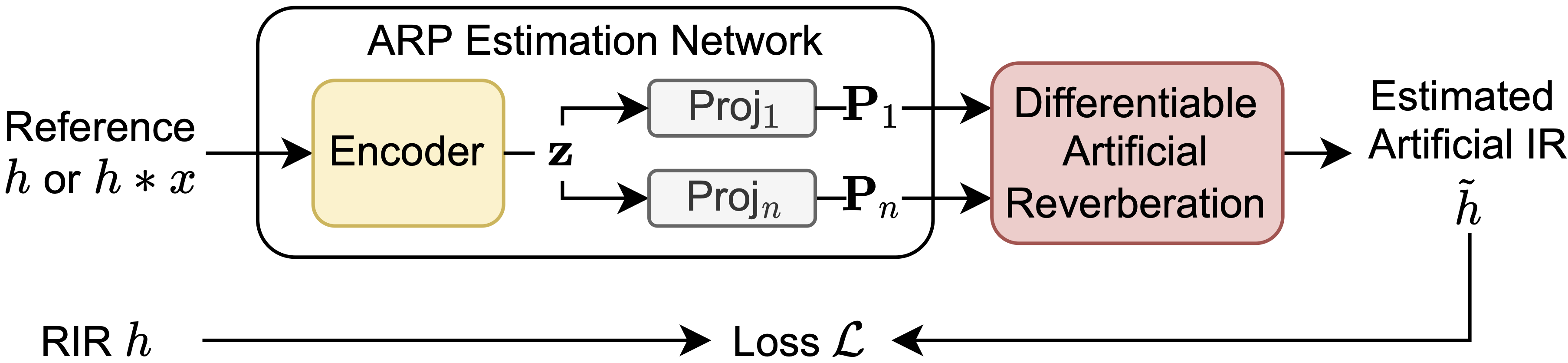
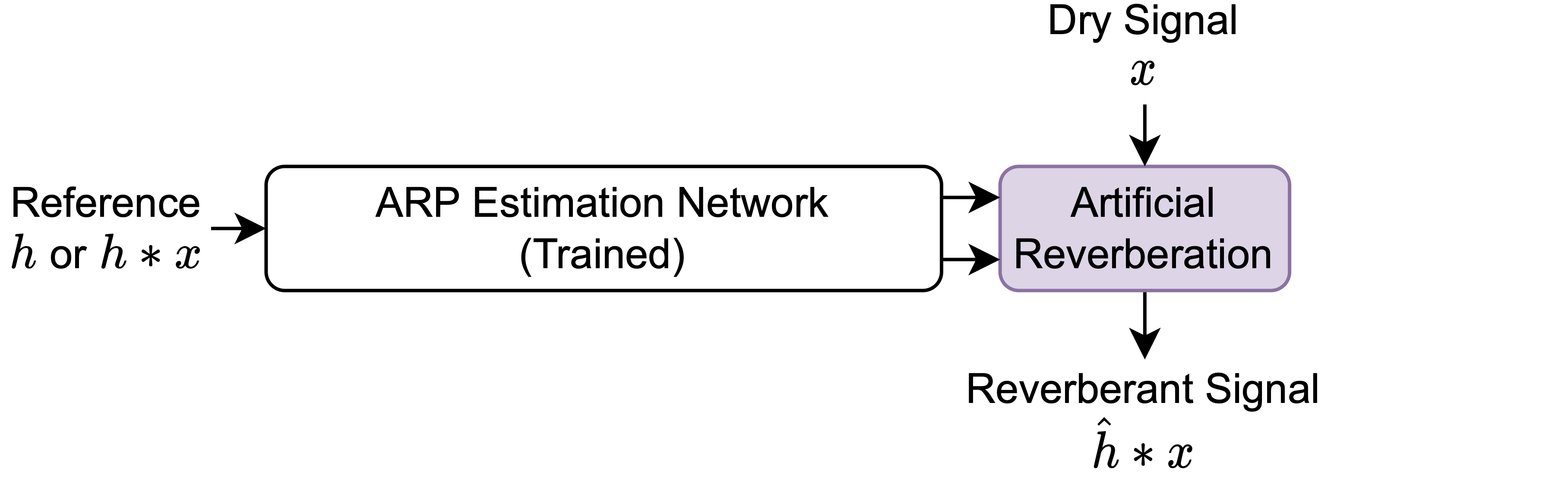
Figure 1: The proposed ARP estimation framework. (a) With the DAR models, loss gradients ∂L/∂P1,⋯,∂L/∂Pn can be back-propagated through the DAR models.
In the FVN and AFVN models, the approach segments the target room impulse response (RIR), applying velvet noise filtered through tailored allpass and coloration filters. The differentiable implementation leverages SVFs parameterized directly for improved performance and control. DN models, on the other hand, are refined to use fewer delay lines and include time-varying feedback components for enhanced echo density build-up.
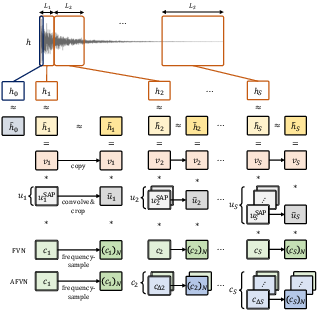
Figure 2: Modified FVN, AVFN's RIR approximation, and their differentiable implementation strategy.
Frequency-Sampling Method
The DAR models employ a frequency-sampling technique to approximate the IIR filters with FIR filters. This method is validated through analytical results that demonstrate the minimal error in frequency response approximation, making it a reliable alternative for differentiability in AR models.
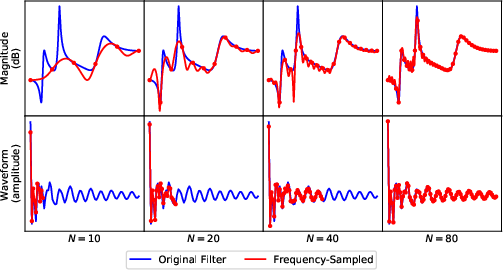
Figure 3: The frequency-sampling method with a various number of sampling points N. Blue curves represent its magnitude response ∣H(ejω)∣.
Network Architecture for ARP Estimation
The paper introduces an ARP estimation network that uses a shared latent space generated by a convolutional encoder. This space is then projected into ARP-specific outputs using specialized projection layers. The network is trained to optimize a multi-scale spectral loss, facilitating robust parameter estimation across both analysis-synthesis and blind estimation tasks.
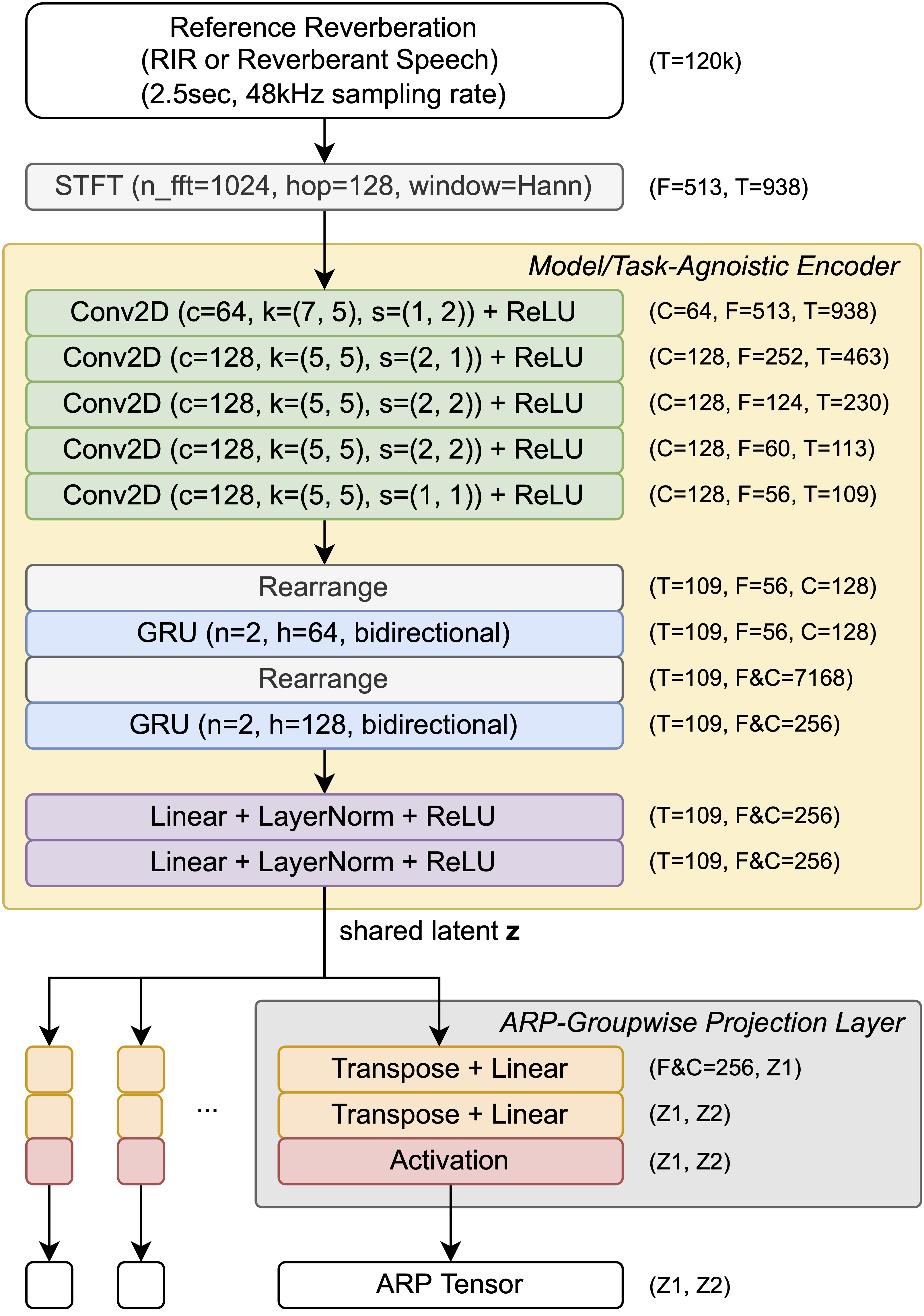
Figure 4: Architecture of the ARP estimation network. For each two-dimensional convolutional (Conv2D) layer, c, k, and s denote number of output channel, kernel size, and stride.
Evaluation and Results
Objective and Subjective Metrics
The proposed methods were evaluated using objective metrics such as match loss and EDR distance, as well as subjective listening tests. The results highlighted superior performance of the end-to-end trained networks over parameter-matching baselines, with significant improvements in reverberation parameter estimation accuracy and perceptual quality.
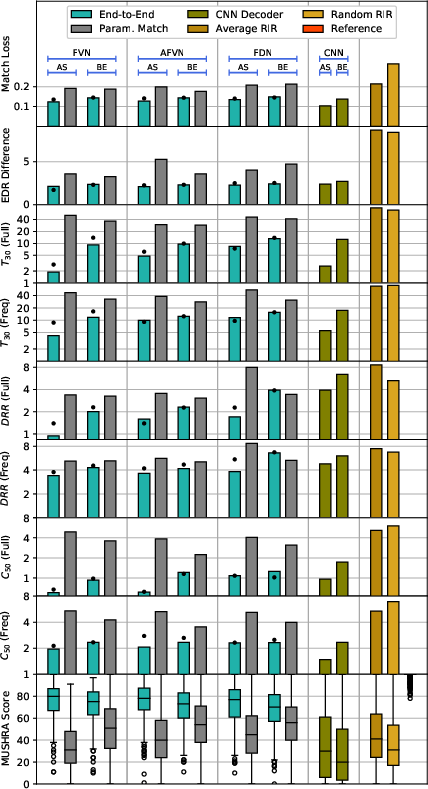
Figure 5: ARP estimation results on various tasks with the AR/DAR models. AS and BE denote analysis-synthesis and blind estimation, respectively.
The DAR models demonstrated high reliability with minimal deviation from their original AR counterparts, as evidenced by the negligible differences in the evaluated metrics. The research further establishes a trade-off between model complexity and estimation performance, underscoring the advantages of integrating structured DSP components with deep learning.
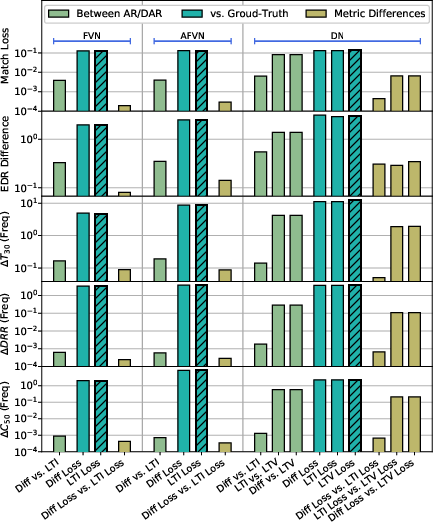
Figure 6: Reliability of the DAR models. Diff, LTI, and LTV denote the differentiable, original LTI, and the time-varying model.
Implications and Future Prospects
The integration of DAR models with deep learning frameworks provides a powerful tool for ARP estimation, advancing the state of the art in artificial reverberation. This approach offers significant practical benefits, including improved real-time control and reduced computational overhead. The authors suggest avenues for future research, such as the exploration of more "deep-learning-friendly" models and the potential application of these methods in varied acoustic environments.

Figure 7: EDR plots of the reference RIRs and their estimations with the trained networks.
Conclusion
The paper presents substantial advancements in the field of artificial reverberation by introducing differentiable models that enable end-to-end learning of AR parameters. By addressing the limitations of traditional non-end-to-end training schemes, this research not only enhances the performance of AR models but also opens up new possibilities for real-time audio processing and control. Future work could focus on refining model architectures and expanding the applicability of these innovations in diverse acoustic scenarios.

