- The paper introduces SPEAR, a novel framework for cost-effective evaluation of retrievers in Retrieval-Augmented Generation systems using automated subset-sampling.
- It employs a Pseudo GT generation technique that aggregates recall across retrievers to overcome the challenges of manual annotation and high computational cost.
- The framework demonstrates practical efficacy in applications like knowledge-based QA and travel assistants, optimizing retriever configurations for improved performance.
Understanding SPEAR: A Framework for Evaluating Retrieval-Augmented Generation Systems
This essay presents a detailed overview of the SPEAR framework, which offers a novel approach to the evaluation of Retrieval-Augmented Generation (RAG) systems. SPEAR introduces a cost-effective, automated method for evaluating retrievers within these systems by leveraging subset-sampling techniques for performance evaluation. The framework aims to provide optimal retrievers tailored to specific business contexts, thereby enhancing the overall effectiveness of RAG applications.
Motivation and Core Challenges
Retrieval effectiveness crucially determines the quality of responses generated by RAG systems. These systems, pivotal in AI applications such as knowledge-based QA and travel assistants, often entail complex retriever configurations involving multiple hyperparameters. Tuning these parameters demands expensive computational resources. Traditional evaluation methods are either cost-prohibitive or lack relevance to domain-specific applications. Thus, SPEAR focuses on addressing the significant challenge of evaluating retrievers effectively without the prohibitive cost of exhaustive ground truth labeling.
Data Acquisition and Subset Sampling
One principal challenge is the acquisition of complete ground truth data, which is resource-intensive both in terms of time and cost. Manual annotation is often unruly, while model-based approaches can be costly. Random sampling reduces computational needs but risks inaccurate representations of original distributions. SPEAR employs an innovative subset-sampling technique, generating Pseudo GT by aggregating recall results across retrievers. This ensures that positive samples remain intact while reducing negatives proportionally, enabling aligned performance assessments across retrievers.
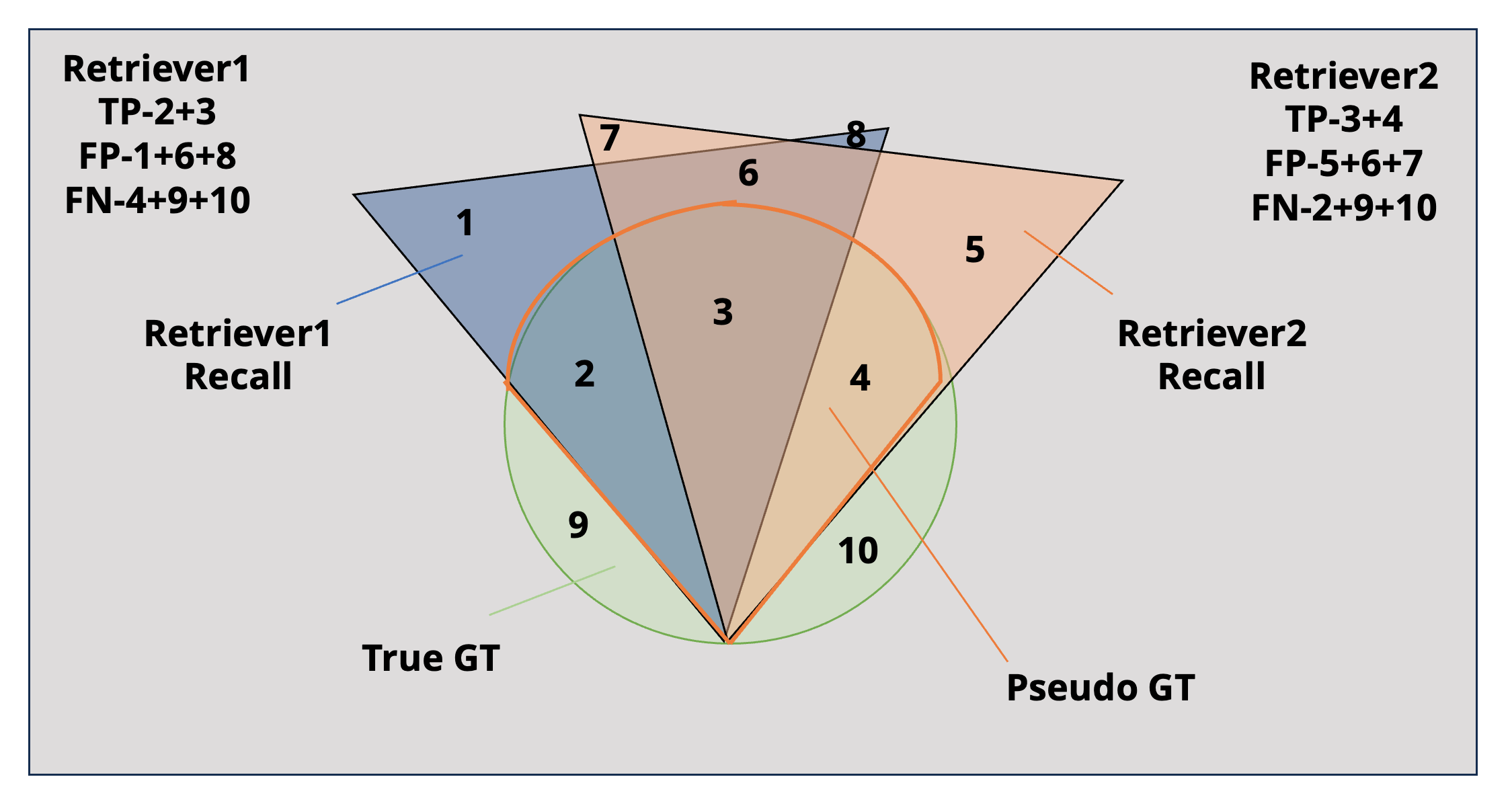
Figure 1: With our subset sampling method, we can get relative comparison between different retrievers.
Evaluation Metrics
RAG systems encounter trade-offs in segmentation strategies—larger chunks can improve recall at the expense of precision. To address this, SPEAR eschews traditional precision-recall balances (such as the F-beta score) for PR-AUC (Precision-Recall Area Under Curve) metrics. PR-AUC distinctly evaluates model performance on imbalanced data by emphasizing positive identification, surpassing ROC-AUC's shortcomings in imbalance sensitivity. This approach obviates the determination of fixed precision-recall weights, allowing performance assessment across thresholds for robust retriever comparison.
Cross-Retriever Evaluation
Comparing retrievers with different segmentation strategies introduces complexity due to varying chunk lengths. LLM-based minimal retrieval facts generation is proposed, which extracts minimal relevant text using LLMs, discarding redundant information. This ensures fair and accurate cross-retriever comparisons by mitigating segmentation-induced computational errors.
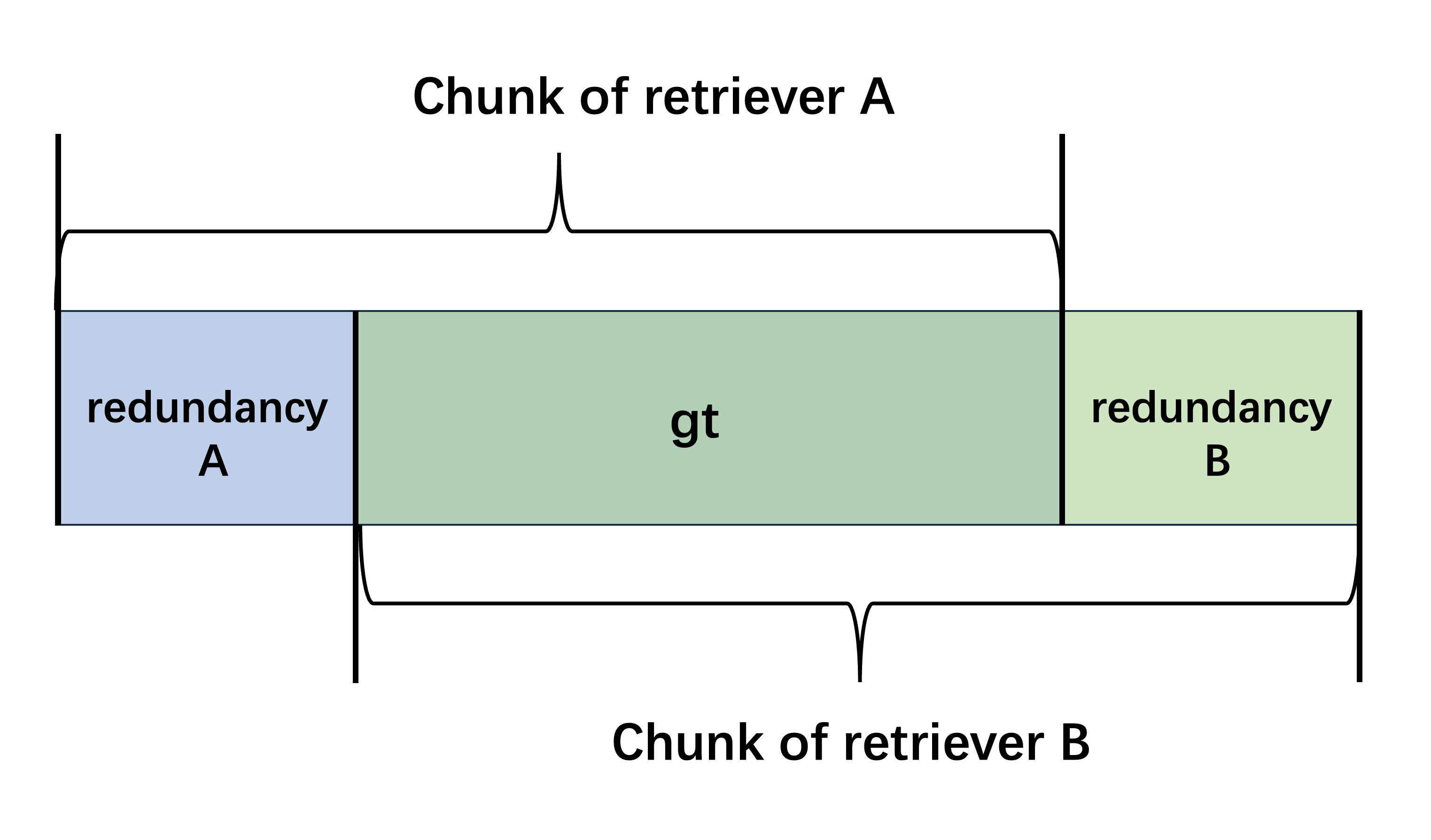
Figure 2: The challenge of comparison between retrievers with different segmentation strategy.
Applications of SPEAR in RAG Systems
SPEAR's application spans classic RAG scenarios, exemplified by its deployment in two key applications at rednote: a knowledge-based QA assistant named Linghang Shu and a travel-oriented generative assistant. These applications corroborate SPEAR's efficacy in optimizing retrievers for diverse contexts.
Linghang Shu: Knowledge-Based QA
Linghang Shu serves as a self-service consultation assistant for rednote employees. The retrieval strategy for optimizing this QA system involved combinations of segmentation, retrieval, and embedding models, evaluated using SPEAR on real user queries. Notably, the integration of Conan-embedding within a hybrid retrieval strategy emerged as superior, enhancing precision and recall metrics. These findings validate SPEAR’s capacity to fine-tune RAG systems using real-world queries for deriving optimal configurations.
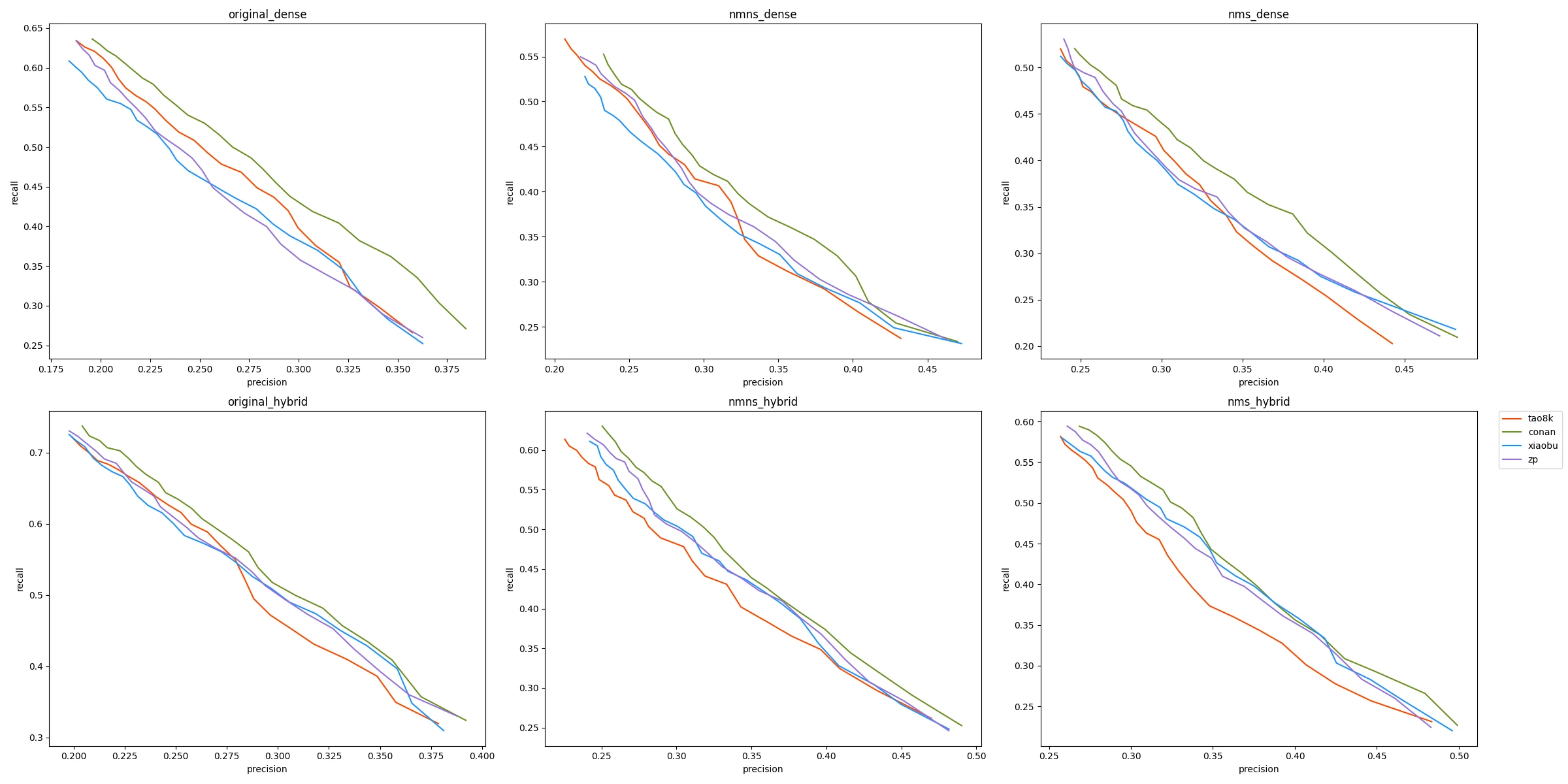
Figure 3: Evaluation Result of Embedding Model.
Travel Assistant
In the travel domain, SPEAR facilitated the identification of optimal retriever configurations by analyzing interactions amongst query rewriter, filter, and reranker components. Evaluations highlighted the importance of component interplay in retriever performance, emphasizing comprehensive evaluation over isolated component optimization. Two optimum configurations were identified: a full-feature set for precision-prioritized scenarios and a filter-only approach for recall-prioritized ones.

Figure 4: Evaluation Result of Using Rewriter.
Implications and Limitations
The SPEAR framework presents clear advantages in cost-effective retriever evaluation, offering significant scope for real-time adaptability in performance optimization. However, it faces limitations in balancing computational efficiency with accuracy, notably in the absence of mechanisms explicitly addressing unanswerable queries or differentiating query answerability. Future advancements must bridge these gaps, potentially enhancing SPEAR’s utility across different real-world applications.
Conclusion
SPEAR provides a robust, automated solution for evaluating and optimizing retrievers in RAG systems, broadening the potential for effective deployment in various industrial applications. The framework stands out for its cost-efficiency and adaptability to real user queries, marking a substantial contribution to the landscape of retrieval evaluation in AI systems. SPEAR's deployment across diverse applications testifies to its practical significance and underscores its potential impact on enhancing the operational efficacy of RAG systems.