- The paper presents an automated Elo-based framework, RAGElo, that leverages LLM-generated synthetic queries and LLM-as-a-judge methods to evaluate RAG-Fusion systems.
- It employs rank-fusion techniques to merge query variations, resulting in improved document retrieval quality and more complete, diverse answers.
- Evaluations reveal that while RAG-Fusion enhances answer completeness, traditional RAG systems exhibit higher precision, highlighting a trade-off between comprehensiveness and focus.
Evaluating RAG-Fusion with RAGElo: an Automated Elo-based Framework
Introduction
"Evaluating RAG-Fusion with RAGElo: an Automated Elo-based Framework" presents an innovative approach to addressing the challenges of evaluating Retrieval-Augmented Generation (RAG) systems, particularly in enterprise settings where domain-specific knowledge is crucial. The paper details an evaluation framework that leverages LLMs to generate synthetic queries and employ LLM-as-a-judge for automatic evaluation, culminating in the RAGElo system. The framework is designed to overcome issues of hallucination and the absence of standardized benchmarks, especially in environments where private, in-domain documents are involved.
RAG-Fusion and Rank Fusion
RAG-Fusion (RAGF) enhances traditional RAG systems by incorporating rank-fusion techniques, specifically Reciprocal Rank Fusion (RRF), to improve the quality of fetched documents and generated answers. Instead of relying on a single query, RAGF creates variations of a user query to produce a more diverse set of documents. This process involves generating multiple query variations using an LLM, retrieving relevant documents for each query, and finally merging these results using RRF. As opposed to traditional RAG, RAGF aims to provide more comprehensive and higher-quality answers by leveraging the diversity in document retrieval.
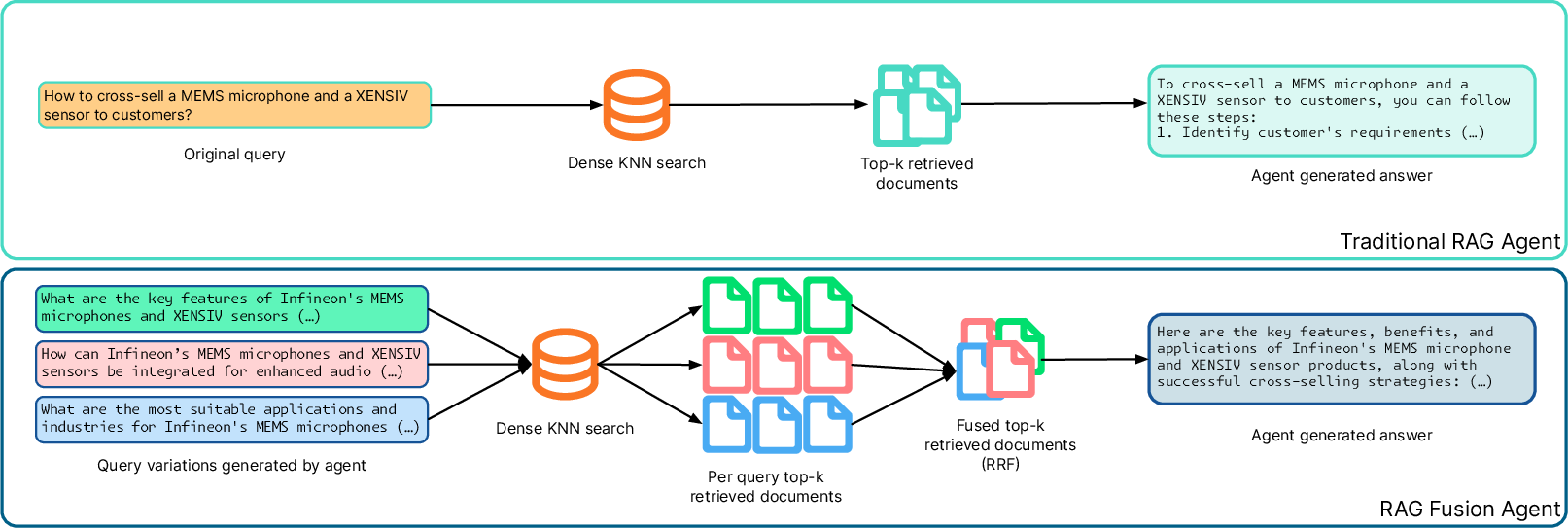
Figure 1: A traditional RAG pipeline compared to a RAGF pipeline, demonstrating the integration of query variations in RAGF.
Synthetic Queries and Automated Evaluation
A key aspect of the proposed framework is the generation of synthetic queries to create a test set for evaluating the RAG systems. The paper outlines a process similar to InPars, where synthetic queries are generated by prompting LLMs with document passages and few-shot examples drawn from real user questions. This approach enables the creation of high-quality evaluation datasets in the absence of extensive real query logs.
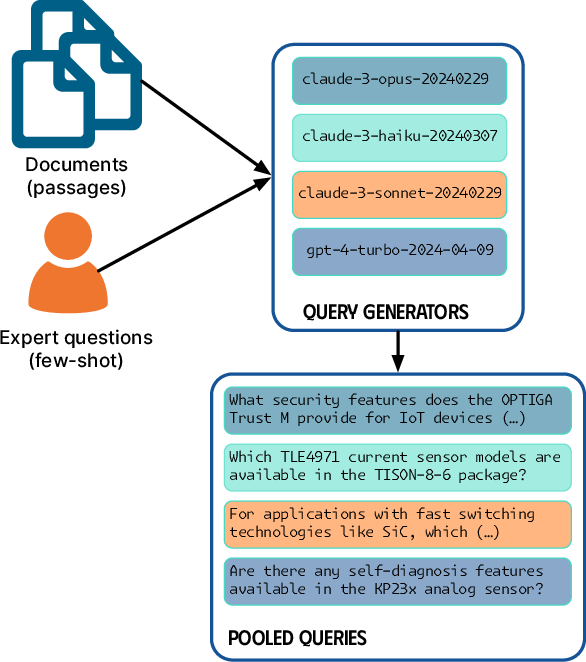
Figure 2: Process for creating synthetic queries using LLMs, incorporating existing user queries as few-shot examples.
The evaluation of answers utilizes an LLM-as-a-judge methodology, where answers generated by RAG systems are assessed by another strong LLM. This two-tier evaluation considers both the relevance of retrieved documents and the quality of generated answers. RAGElo, a tool inspired by the Elo rating system, facilitates the comparison by scoring competing RAG implementations through synthetic tournaments, thereby providing an automated and scalable evaluation mechanism.
Multiple configurations of RAG systems, including variations using BM25, KNN, and Hybrid retrieval methods, are evaluated via RAGElo. The paper presents strong evidence that RAGF outperforms traditional RAG concerning completeness and answer quality, although it may lack precision in some cases. Mean Reciprocal Rank @5 (MRR@5) metrics show that RAGF generally achieves higher scores in retrieving both somewhat and very relevant documents compared to traditional RAG systems.
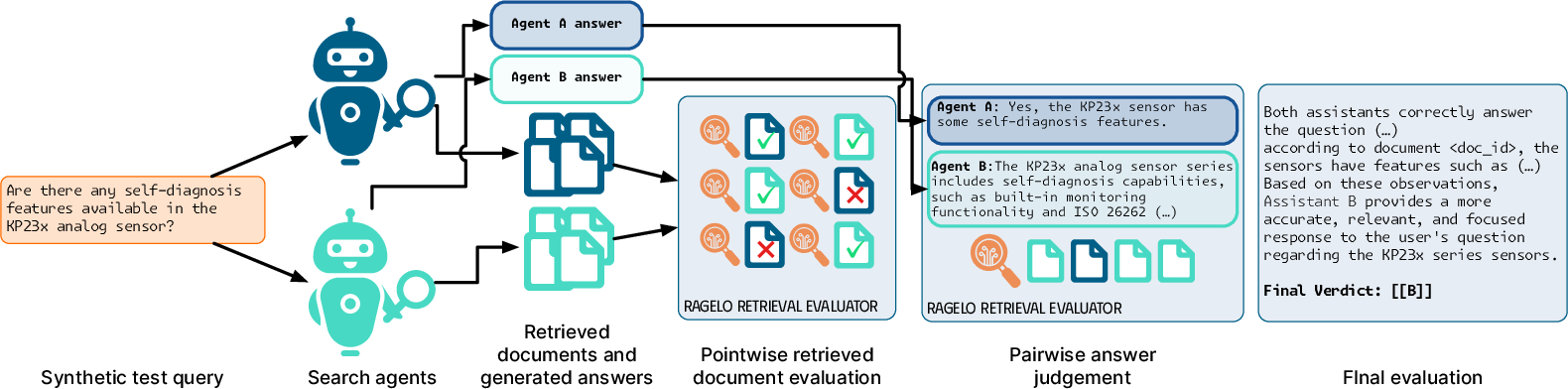
Figure 3: The RAGElo evaluation pipeline showing the document and answer evaluation sequence.
The RAGElo framework demonstrated a positive alignment with human evaluations in terms of assessing relevance, accuracy, and completeness. However, while RAGF provided more complete answers, traditional RAG excelled in precision, highlighting a trade-off between comprehensiveness and focus.
Discussion
The study illustrates the robust applicability of RAGElo across various RAG configurations and reinforces the benefits of a sophisticated retrieval and evaluation process via RAGF. By embracing synthetic query generation and automated LLM evaluations, RAGElo offers a compelling solution for rapidly evaluating RAG systems in data-rich but standardized-deprived environments.
Future work may explore enhancements in retrieval strategies and more fine-tuned embeddings to push the boundaries of RAGF’s performance further. Additionally, applying RAGElo to other domains and enhancing its prompts could refine the balance between answer completeness and precision.
Conclusion
The presented framework effectively addresses significant challenges in RAG evaluation, providing an automated and scalable system conducive to continuous improvements and broader application. The synthesis of RAGF and RAGElo represents an important step toward understanding and deploying improved retrieval-augmented conversational agents, especially in technically demanding industries.
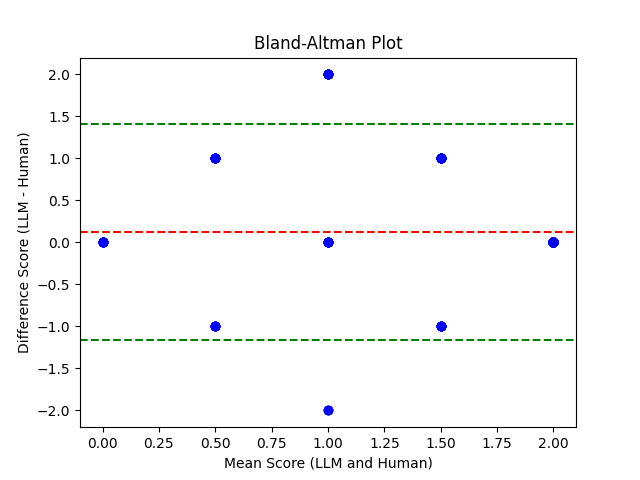
Figure 4: Bland-Altman plot illustrating the comparison between LLM-as-a-judge and expert evaluations, indicating moderate positive correlation.

