- The paper introduces ProtoMM, a training-free framework that dynamically combines visual features and textual prototypes to enhance VLM test-time adaptation.
- It employs an optimal transport approach to align multimodal distributions, effectively resolving semantic ambiguities and improving class differentiation.
- Experimental results show a 1.03% average accuracy gain on ImageNet benchmarks, demonstrating the framework's robustness and wide applicability.
Dynamic Multimodal Prototype Learning in Vision-LLMs
Introduction
The research article "Dynamic Multimodal Prototype Learning in Vision-LLMs" (2507.03657) presents a novel approach to enhancing the performance of pre-trained vision-LLMs (VLMs) during test-time adaptation (TTA). The primary motivation behind this work is to address the limitations of existing methods that predominantly rely on textual prototypes, thus neglecting the comprehensive visual semantics inherent in visual data. ProtoMM, a training-free framework introduced in this paper, leverages multimodal prototypes constructed from both textual descriptions and visual features. This allows VLMs to dynamically learn and adapt during testing by utilizing multimodal signals, thereby improving performance in unseen scenarios.
Method Overview
ProtoMM represents a paradigm shift from the traditional dependence on static textual prototypes. By utilizing a dynamic approach, the framework incorporates evolving visual particles and textual descriptions to form comprehensive multimodal prototypes, which are updated in real-time as more data is processed during testing. Each class prototype in ProtoMM is modeled as a discrete distribution over textual descriptions and dynamically updated visual particles. This multimodal integration is achieved by solving an optimal transport problem to align the semantic distributions of test images and prototypes.
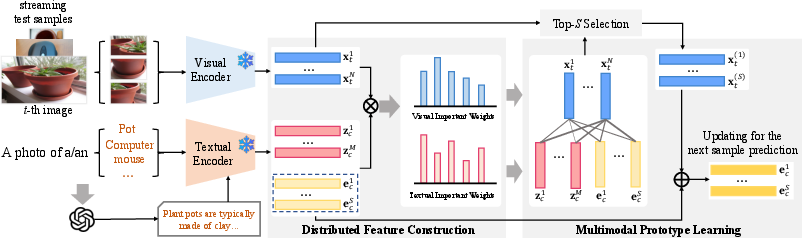
Figure 1: An framework of the proposed method (ProtoMM), which consists of two modules, i.e., (a) Distributed Feature Construction: Expand the textual prototypes with visual features from testing samples. (b) Multimodal Prototype Learning: Updating the multimodal prototypes through the transport plan for the next prediction.
The framework addresses the semantic ambiguities associated with class names in traditional VLMs, as these ambiguities often result from shared linguistic components or similar semantic contexts, leading to challenges in accurate image classification. By dynamically updating with visual features, ProtoMM ensures that the prototypes better capture the inherent characteristics of visual data, thereby enabling more accurate differentiation between classes, as demonstrated in Figure 2.
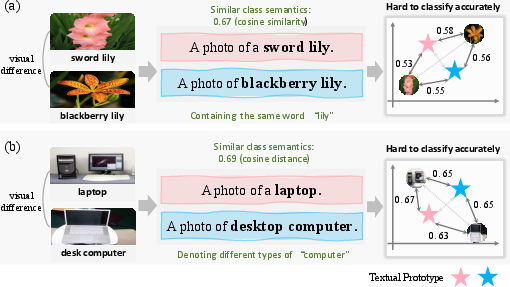
Figure 2: Observations of ambiguities in class names from the Oxford Flowers and ImageNet datasets.
Experimental Evaluation
The efficacy of ProtoMM was thoroughly evaluated across 15 zero-shot classification benchmarks, including challenging datasets like ImageNet and its variants. The experimental results showed a substantial improvement in classification accuracy, averaging a 1.03% increase over state-of-the-art methods on ImageNet benchmarks. This performance gain evidences the robustness and adaptability conferred by the multimodal prototype strategy. Moreover, the approach successfully blends visual and textual cues, outperforming current methods reliant solely on textual adaptation.
Table comparisons reveal that ProtoMM's integration of multimodal signals consistently outperforms purely textual or unimodal approaches. The framework's alignment with test-time adaptation objectives and ability to improve upon previous state-of-the-art methods underscore its potential for broad applications in zero-shot learning contexts.
Theoretical and Practical Implications
This study contributes valuable insights into the benefits of integrating multimodal information within prototype learning frameworks. The proposed methodology enhances VLMs' ability to generalize across diverse datasets by providing a more detailed embedding space that reduces ambiguity in class differentiation. Theoretically, the adoption of optimal transport for prototype adaptation introduces an effective means of managing semantic discrepancies across data modalities.
Practically, ProtoMM represents a training-free adaptation method, potentially reducing the computational overhead associated with model fine-tuning during test time. This characteristic is particularly advantageous in real-world applications where rapid adaptation without retraining is essential.
Future Directions
The promising results achieved by ProtoMM open avenues for further research into multimodal integration techniques in prototype learning frameworks. Future work could explore the scalability of ProtoMM in high-resolution vision tasks or its adaptability across broader multimodal applications such as text-to-image synthesis. Iterative improvements to the visual particle selection algorithm and further optimization of optimal transport calculations could enhance the framework's efficiency and applicability.
Conclusion
The introduction of ProtoMM marks a significant advancement in vision-LLM adaptation, showcasing the power of dynamic multimodal prototype learning. By addressing semantic ambiguities and leveraging multimodal distributions, this approach significantly enhances model effectiveness and generalization capabilities. The contributions of this research underscore the importance of harnessing both visual and textual information for robust test-time adaptation in VLMs, paving the way for improved zero-shot learning techniques across diverse applications.