- The paper presents MuproCL, a multi-prototype supervision framework that significantly mitigates semantic ambiguity and catastrophic forgetting in visual continual learning.
- It employs an LLM to generate diverse, context-rich semantic prototypes and uses LogSumExp aggregation for adaptive feature alignment between visual and semantic spaces.
- Experiments on CIFAR100 demonstrate a 5.6% improvement in average accuracy and reduced forgetting rates compared to traditional continual learning approaches.
Towards Robust Visual Continual Learning with Multi-Prototype Supervision
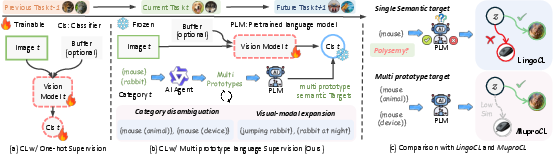
The paper "Towards Robust Visual Continual Learning with Multi-Prototype Supervision" (2509.16011) offers a novel framework to address notable challenges in visual continual learning (CL). This framework, named MuproCL, introduces a multi-prototype supervision mechanism to overcome the limitations associated with single-target language-guided methods, particularly issues arising from semantic ambiguity and intra-class visual diversity.
Introduction
Visual continual learning addresses the challenge of enabling machine learning models to sequentially learn new tasks without forgetting previously acquired knowledge. Tackling catastrophic forgetting is crucial for adapting models to dynamic environments, pertinent to applications in robotics, healthcare, and autonomous systems. State-of-the-art approaches employ varied methodologies, including regularization, replay, distillation, and architectural adaptation, often relying on randomly initialized one-hot supervision. Recently, the field has witnessed a paradigm shift towards using PLMs to derive semantic targets, as exemplified in LingoCL. However, single static targets can lead to misrepresentations when dealing with polysemous categories or visually diverse classes, creating room for suboptimal learning performance.
Proposed Method: MuproCL
MuproCL is proposed as a solution to these constraints, replacing single static targets with multi-prototype targets. This enhancement effectively uses a lightweight LLM agent to generate a set of contextually rich semantic prototypes, leveraging the diversity and precision of language-guided supervision.
Key mechanisms of MuproCL:
Methodology
The methodological structure of MuproCL integrates within the CL training paradigm by initializing task-specific classifiers with context-aware semantic targets drawn from PLM-processed LLM prompts. This enables the retention of meaningful knowledge previously constrained by single-target systems, fostering greater robustness across tasks.
- Disambiguation and Expansion: For each class, multiple textual prompts are curated to encapsulate semantic diversity. A finely-tuned filter—and—sample method is deployed to generate diverse prototypes, conserving semantic richness yet avoiding redundancy.
- Optimization via LogSumExp: Ensures the alignment of vision encoder outputs with nuanced semantic vectors, maintaining fidelity across visual inputs with varying attributes.
Experiments
The paper demonstrates MuproCL's efficacy through comprehensive experiments against several CL baselines on the CIFAR100 dataset under various class-incremental settings. The introduced method is consistently superior to conventional baselines, including single-target LingoCL, underscoring its robustness and adaptability.
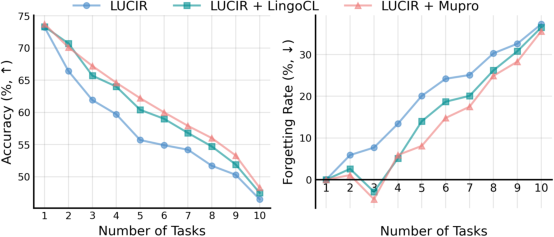
Figure 2: Shows accuracy and forgetting rate trajectories across tasks, indicating MuproCL's persistent advantage in sustaining model performance over sequential learning.
The observed performance gains signal a notable 5.6% improvement in average accuracy over traditional baselines, alongside a marked reduction in catastrophic forgetting, evidenced by diminishing forgetting rates particularly resonant in extended task sequences.
Conclusion
The introduction of MuproCL is a substantial advancement towards addressing inherent drawbacks in language-guided CL, proving that enriched, adaptive, and poly-semantic supervision significantly enhances learning consistency and accuracy across extensive and diverse visual tasks. Looking towards future research, exploring intricate balance mechanisms among multiple prototypes presents intriguing avenues for further improvement in open-world scenarios, potentially leveraging even more nuanced language and vision synergies.