DramaBench: A Six-Dimensional Evaluation Framework for Drama Script Continuation
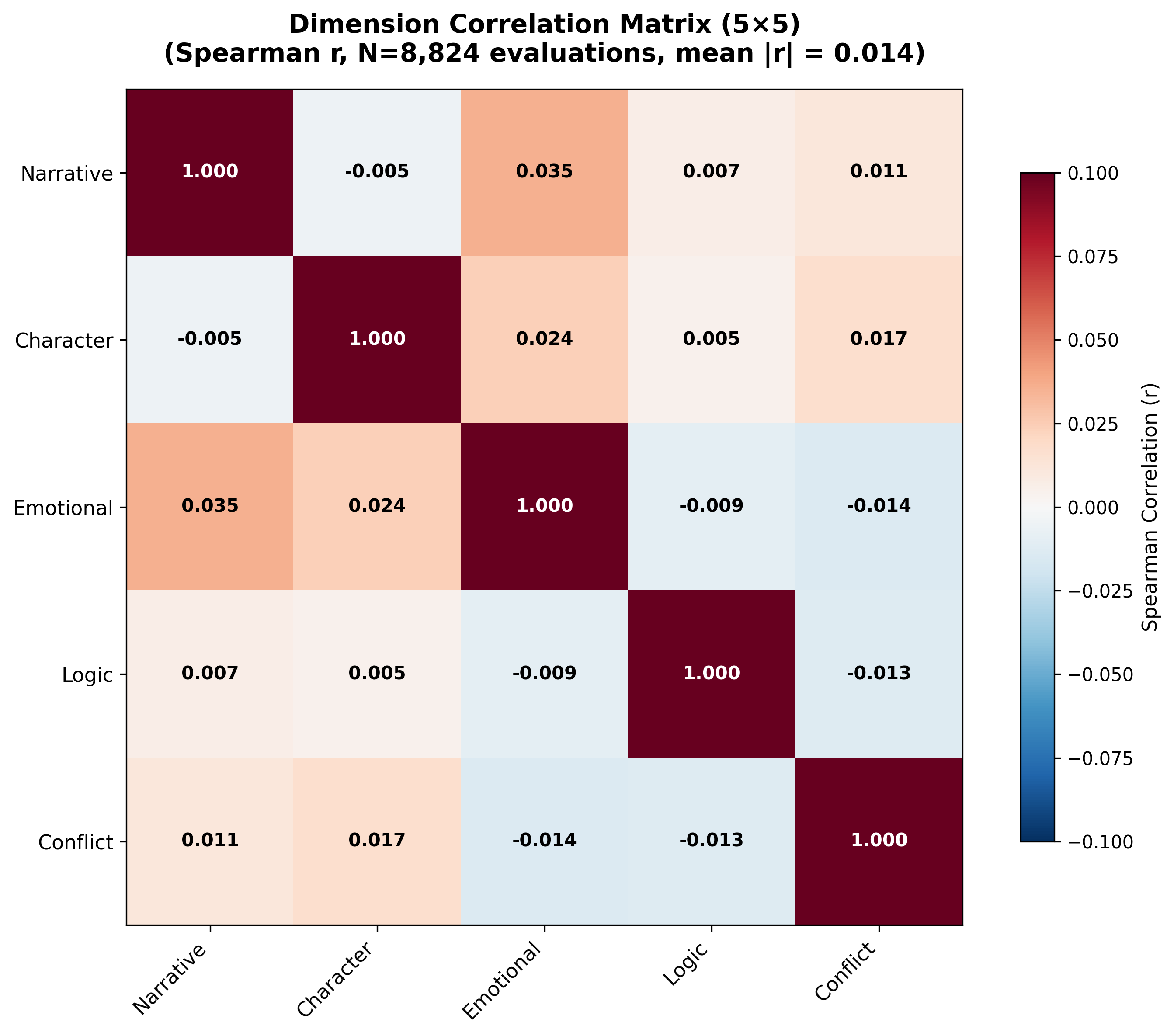
Abstract: Drama script continuation requires models to maintain character consistency, advance plot coherently, and preserve dramatic structurecapabilities that existing benchmarks fail to evaluate comprehensively. We present DramaBench, the first large-scale benchmark for evaluating drama script continuation across six independent dimensions: Format Standards, Narrative Efficiency, Character Consistency, Emotional Depth, Logic Consistency, and Conflict Handling. Our framework combines rulebased analysis with LLM-based labeling and statistical metrics, ensuring objective and reproducible evaluation. We conduct comprehensive evaluation of 8 state-of-the-art LLMs on 1,103 scripts (8,824 evaluations total), with rigorous statistical significance testing (252 pairwise comparisons, 65.9% significant) and human validation (188 scripts, substantial agreement on 3/5 dimensions). Our ablation studies confirm all six dimensions capture independent quality aspects (mean | r | = 0.020). DramaBench provides actionable, dimensionspecific feedback for model improvement and establishes a rigorous standard for creative writing evaluation.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “DramaBench: A Six-Dimensional Evaluation Framework for Drama Script Continuation”
1) What is this paper about?
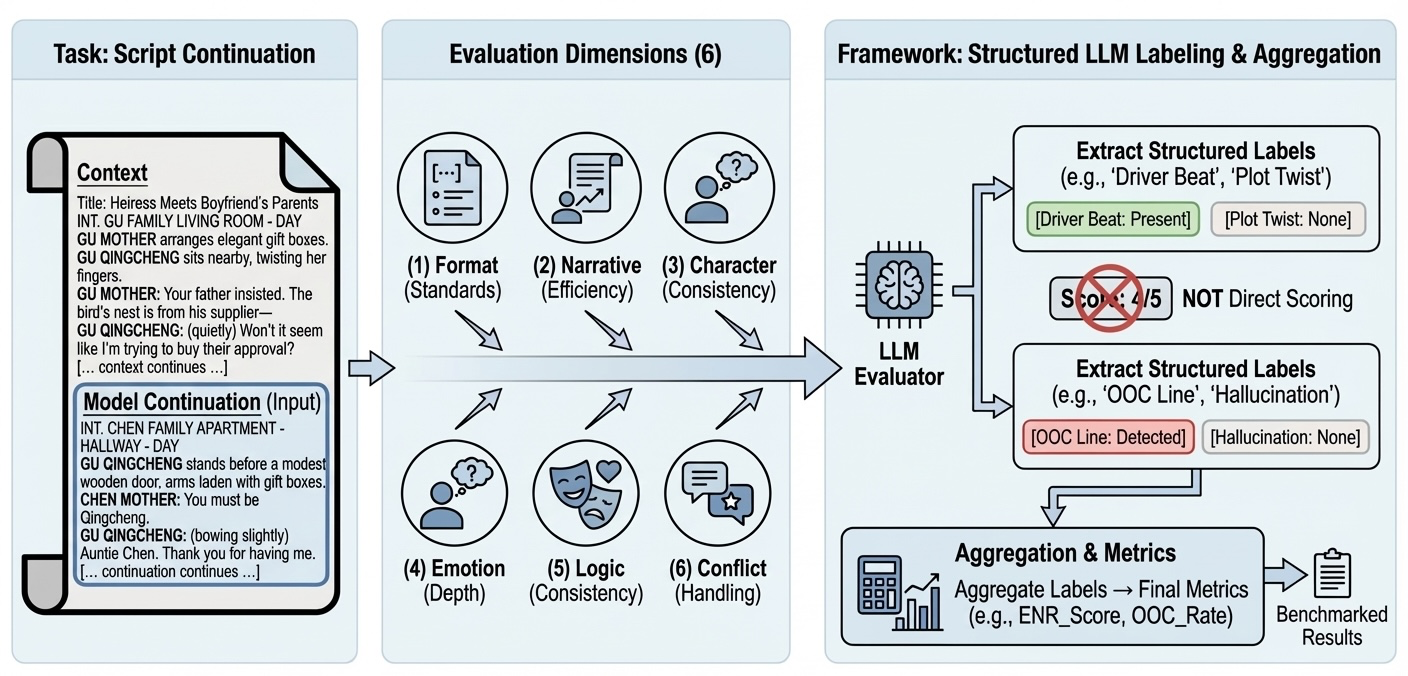
This paper introduces DramaBench, a way to test how well AI models can continue a drama script. When an AI writes the next part of a script, it needs to keep characters acting like themselves, move the story forward, make emotions feel real, avoid logic mistakes, build conflict, and follow screenplay format rules. DramaBench checks all of these things using six separate “dimensions,” so we can see exactly where an AI is strong or weak.
2) What questions did the researchers want to answer?
In simple terms, they asked:
- How can we fairly and clearly measure the quality of AI-written script continuations?
- Can we break “quality” into several parts (like character consistency or emotional depth) instead of using one overall score?
- Can we make this evaluation reproducible (so others get the same results) and useful (so it tells model creators what to fix)?
- How do top AI models compare across these different parts of script quality?
3) How did they study it?
They built a large test set and a careful evaluation system.
- The data: They used 1,103 professionally formatted short drama scripts. Each script was split into two parts: the “context” (first half) and the “continuation” (second half). The split was made around scene boundaries (like where “INT.” or “EXT.” appears), so the continuation starts at a natural point in the story.
- The models: Eight advanced AI models were asked to continue the scripts based on the context.
- The evaluation method: Instead of asking an AI to “score” the writing directly (which can be biased), they used an AI to tag specific items, like whether a line is “in-character” or whether an action advances the plot. Then they turned those tags into numbers using simple counting. Think of it like a referee marking checkboxes rather than giving one vague score.
The six dimensions (what they measured)
- Format Standards: Does the writing follow screenplay formatting rules (like a proper script layout)? This is checked by rules, not by an AI.
- Narrative Efficiency: Does the story actually move forward, or is it mostly filler? They look at “beats” (key events) and classify each as:
- Driver (moves the plot forward)
- Static (describes but doesn’t progress the plot)
- Redundant (repeats known info)
- Character Consistency: Do characters speak and act like themselves, based on the earlier context? Each line is tagged:
- In-character
- Neutral (can’t tell)
- Out-of-character (OOC)
- Emotional Depth: Do emotions change meaningfully in the scene, and are there complex moments (like mixed feelings)?
- Logic Consistency: Does the continuation respect facts set in the context (no contradictions like “broken leg” suddenly becoming “runs fast”)?
- Conflict Handling: Does the main conflict get stronger (escalation), introduce a twist, pause, resolve too early, or get dropped?
4) What did they find, and why does it matter?
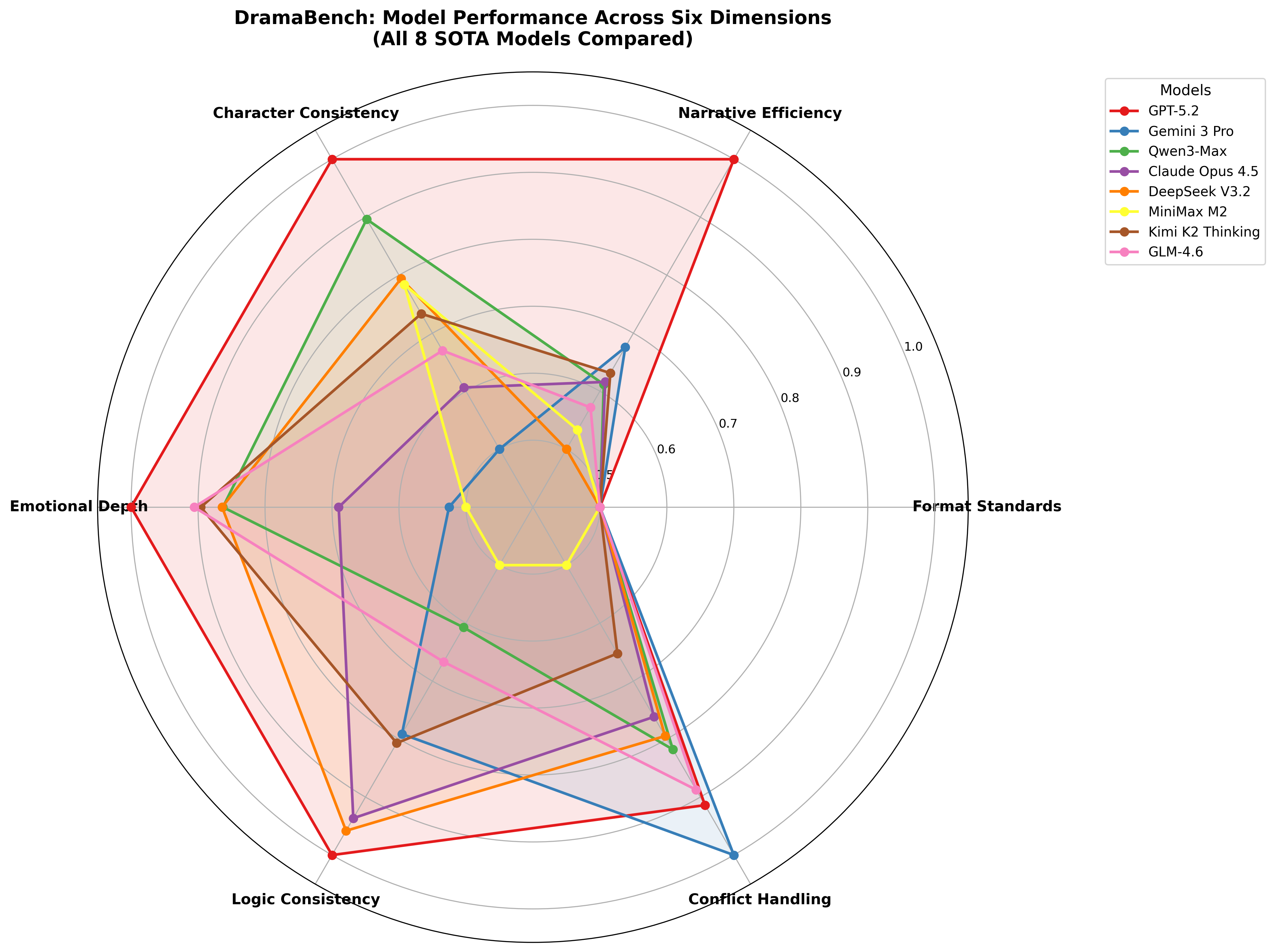
- No single “best” model: Different models were good at different things. For example:
- GPT-5.2 was most robust overall (great at moving the story forward, keeping characters consistent, and maintaining logic).
- Qwen3-Max did best at emotional depth.
- Gemini-3-Pro did best at handling conflict.
- Formatting was easy: All models followed screenplay format well. That means simple formatting rules can be learned reliably.
- Logic was hardest: Models differed the most in avoiding contradictions. This suggests “remembering and respecting facts” is a key challenge.
- The measurements were statistically solid: Many model-to-model comparisons were significantly different, meaning results weren’t just random.
- Human checks: When humans compared the AI evaluator’s labels to their own, they agreed fairly well on logic, emotions, and conflict—but not as much on narrative efficiency and character consistency. This warns us to be careful interpreting those two dimensions.
This matters because it proves that judging creative writing needs multiple, separate checks. A model can be great at conflict but poor at character consistency. If you only use one score, you miss these details.
5) What does this mean for the future?
- Better feedback for AI creators: Because DramaBench breaks quality into six parts, it tells developers exactly what to improve (like “fix logic consistency” or “strengthen emotional arcs”).
- Training data for improvement: The labels (e.g., “OOC” lines or “logic violations”) can be used to teach models what not to do.
- More reliable evaluation: Using labeled categories and simple counts makes results easier to reproduce and trust than vague scores.
- Caveats and next steps: The evaluator AI showed bias on two dimensions (narrative efficiency and character consistency), so using multiple evaluators together could help. Also, future work could expand beyond English, test longer scripts or other genres, and include more human reviews.
In short, DramaBench gives a clear, practical way to judge AI-written drama continuations. It helps us see strengths and weaknesses across six important areas, guiding targeted improvements and setting a higher standard for creative writing evaluation.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to enable actionable follow-up research.
- Evaluator reliability and bias: The primary LLM evaluator (Qwen3-Max) shows weak/no agreement with humans on Narrative Efficiency and Character Consistency. Quantify and mitigate evaluator-specific biases via multi-evaluator ensembles, calibration, and adjudication; report how rankings change under different judges.
- Prompt sensitivity and reproducibility: The paper claims deterministic labeling but does not report evaluator decoding parameters (e.g., temperature, nucleus sampling) or prompt sensitivity analyses. Test label stability across prompt variants, seeds, and decoding settings, and publish variance estimates.
- Effect size reporting: Statistical significance is reported without specifying the effect size metric or confidence intervals. Standardize effect sizes (e.g., Cliff’s delta, rank-biserial), include CIs, and use hierarchical/multilevel models to account for script-level clustering.
- Gold-standard data: No expert-annotated ground truth exists for beats, OOC lines, emotional arcs, conflict handling, or logic facts. Build a screened, professional-annotated subset to benchmark labeler accuracy, inter-annotator agreement, and to calibrate metric thresholds.
- Beat extraction validity: Highly differentiating “Beats per Page” and ENR rely entirely on LLM beat extraction. Validate recall/precision of beat identification against human annotations and test whether verbosity or token-length inflates beat counts.
- Logic fact coverage: Fact extraction for Logic Consistency may miss constraints, biasing violation rates. Measure recall/precision of fact extraction, quantify missed facts, and assess how coverage affects Logic Break Rate.
- Conflict Score design: The conflict weighting (+2/+1/0/−5) is heuristic and yields low variance. Empirically calibrate weights against human preferences, test alternative schemes, and add subcategories (e.g., multi-conflict threading, partial resolutions) to increase discriminative power.
- Emotional complexity modeling: The Valence–Arousal scheme is coarse for screenplay subtext and irony. Compare richer emotion taxonomies (e.g., appraisal theories, Plutchik), incorporate multimodal cues (stage directions), and evaluate cross-cultural emotion expression differences.
- Character Consistency granularity: OOC classification at the line level may conflate neutrality with genericness and ignores multi-turn buildup. Introduce span-level OOC judgments, per-character confidence scores, and thresholds tuned to human judgments.
- Context splitting effects: The scene-boundary-aware split is used in 69.5% of cases; the rest rely on midpoints. Quantify how split type impacts all metrics and model rankings; include controlled experiments that re-split scripts to test sensitivity.
- Domain and genre coverage: The dataset is short-form English drama only. Evaluate generalization to full-length feature scripts, comedy, thriller, experimental theatre, and multi-episode arcs; add genre labels and stratified analyses.
- Long-range structure: The benchmark evaluates single continuation segments (~381-token context). Add metrics for act-level structures (setups/payoffs, motifs, three/five-act arcs), cross-scene callbacks, and deferred resolutions.
- Format generalization: Format analysis assumes Fountain. Test Final Draft/Celtx and international screenplay conventions; publish parsers and validate format compliance beyond Fountain.
- Dataset representativeness and licensing: The provenance and licensing terms of the english_short_drama_scripts_dataset are not detailed. Document genre distribution, author demographics, licensing, and any filtering-induced selection biases.
- Adversarial and ambiguous contexts: The benchmark lacks stress tests (contradictory facts, ambiguous personas, unreliable narrators). Create adversarial subsets to probe robustness of logic, characterization, and conflict metrics.
- Model parameter comparability: Generation settings (temperature, top-p, max tokens) per model are not disclosed. Report standardized decoding parameters, and analyze metric sensitivity to sampling strategies to ensure fair comparisons.
- Blinded judging: It is unclear whether evaluator prompts hide model identities. Ensure judge blindness, test for brand or style biases, and quantify any judge preference drift.
- Cross-dimensional construct validity: Near-zero correlations could reflect measurement noise rather than true independence. Perform factor analysis/CFA and multitrait–multimethod studies with human gold standards to validate constructs.
- Dialogue–action ratio target validity: The target range (1.0–2.0) is asserted but not validated. Correlate with human quality ratings and genre norms; test whether optimizing this ratio inadvertently harms other dimensions.
- Novelization Index definition: The algorithmic detection of “prose-like narrative” is underspecified. Publish detection rules, validate against human judgments, and measure false-positive/negative rates across genres.
- Label-to-training loop: The paper proposes using labels for DPO/reward modeling but presents no closed-loop results. Demonstrate end-to-end training using extracted labels and quantify improvements per dimension without regressions elsewhere.
- Temporal stability: Evaluator and generator models update over time. Establish benchmark versioning, re-evaluation protocols, and change-point analyses to monitor metric drift and maintain longitudinal comparability.
- Costs and scalability: API usage is noted but not quantified. Report token costs per script/dimension, time-to-evaluate, and propose budget-aware evaluation strategies (e.g., sampling, early-exit heuristics, caching).
- Multilingual extension: Non-English scripts are out of scope. Specify requirements for multilingual format parsing, cross-language emotion/character mapping, and judge calibration; pilot with at least 2 additional languages.
- Metric sensitivity to script length and character count: Analyze how metrics vary with continuation length, number of speaking characters, and dialogue density; adjust metrics to avoid length/character-count confounds.
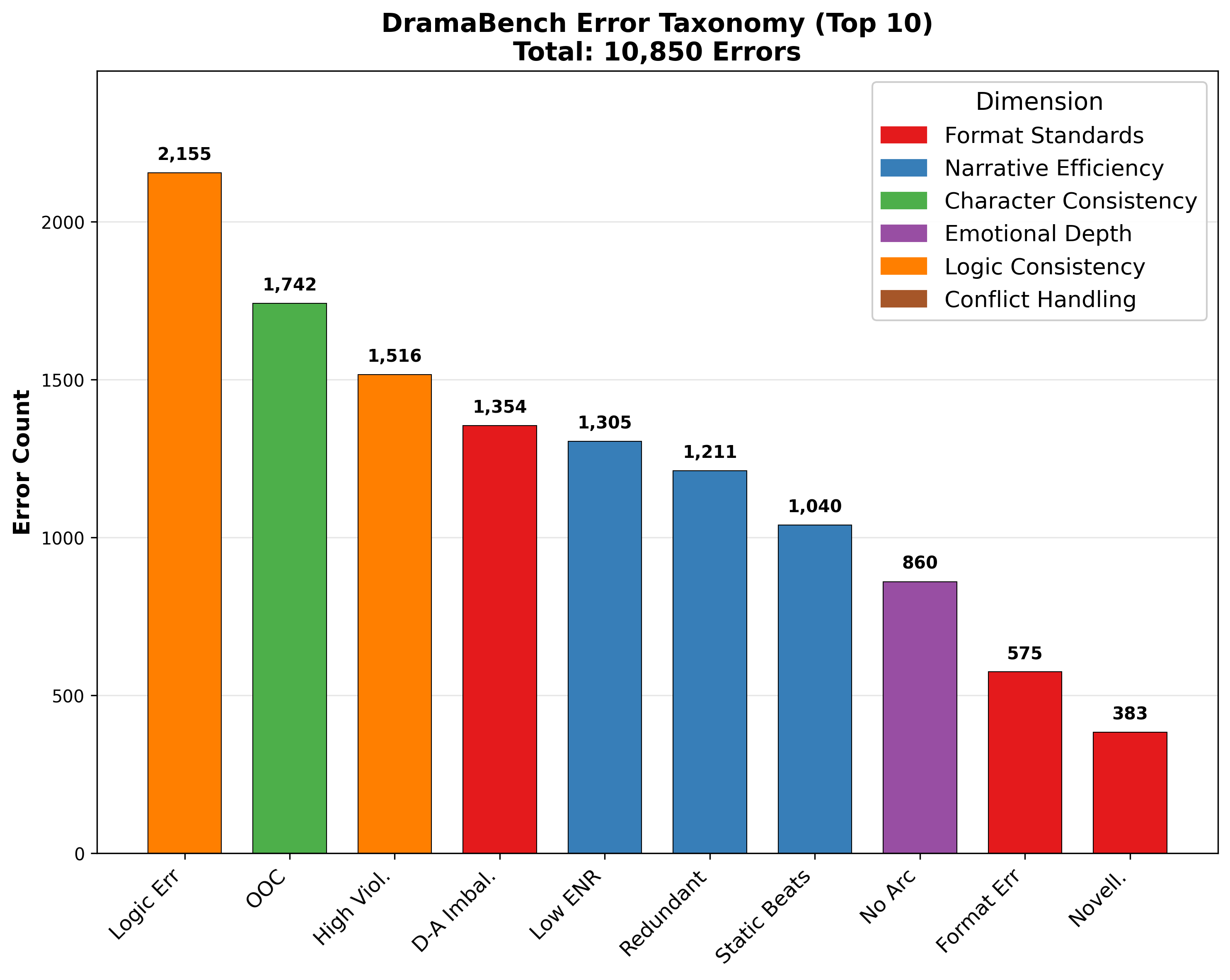
- Error taxonomy validation: The 10,850-error taxonomy is not described or validated. Publish category definitions, labeling procedure, inter-rater reliability, and cross-model confusion matrices to support actionable error-driven training.
- Composite scoring: While single-score systems are discouraged, many applications require holistic ranking. Explore transparent, human-calibrated composite indices and task-specific weightings, with sensitivity analyses.
- Ethical content auditing: Beyond format and logic, assess harmful stereotypes, biases, and unsafe content in continuations; add ethics-focused dimensions and red-teaming subsets to the benchmark.
- Release artifacts: “Will be released” is stated but lacks specifics. Provide timelines, licenses, code, evaluator prompts, seeds/parameters, and frozen model versions to enable exact replication.
- Equation precision and implementation detail: Several metric formulas are ambiguously typeset in the paper. Publish precise mathematical definitions and reference implementations to eliminate interpretation ambiguity.
Practical Applications
Immediate Applications
The following applications can be deployed now using the released benchmark, code, and methodology.
- Multi-dimensional model selection and procurement for studios
- Sector: Media & entertainment; AI vendors
- Use case: Compare in-house or vendor LLMs for script continuation using the six-dimension scorecard to pick the right model per project.
- Tools/workflows: “Script QA dashboard” that ranks models by Narrative Efficiency, Character Consistency, Logic, etc.; procurement scorecards for RFPs.
- Assumptions/dependencies: Access to evaluator LLM (e.g., Qwen3-Max) and API budget; English/Fountain scripts; awareness that two dimensions (Narrative, Character) have weaker human–LLM agreement and require human oversight.
- Writer’s room QA plug‑in for screenwriting apps
- Sector: Software (screenwriting: Highland, Final Draft, Celtx); Media & entertainment
- Use case: Inline flags for OOC dialogue, logic breaks, conflict drops, and redundant/static beats during drafting.
- Tools/workflows: An add‑in that runs DramaBench evaluators on scene save; side‑panel listing labeled beats, OOC lines, and fact violations with jump-to-line navigation.
- Assumptions/dependencies: Fountain parser ready; other formats need adapters; evaluator costs; English-only for now.
- Automated script “pre‑flight” checks before coverage or table reads
- Sector: Studios, production companies
- Use case: Gate scripts with thresholds (e.g., ENR ≥ 0.9, Logic Break Rate ≤ 3%) to reduce editorial load.
- Tools/workflows: CI-like job that runs on each script revision and exports a scorecard PDF.
- Assumptions/dependencies: Thresholds calibrated by genre; human override path for creative exceptions.
- A/B testing harness for prompting and workflow variants
- Sector: AI R&D; Tooling teams in studios
- Use case: Test prompts, context length, or chain-of-thought strategies and quantify effect on each dimension.
- Tools/workflows: Batch runner that scores variants and reports statistically significant lifts using built-in Mann–Whitney U testing.
- Assumptions/dependencies: API tokens/cost; evaluator bias caveats on Narrative/Character dimensions.
- Format and style compliance checker (Fountain rules)
- Sector: Screenwriting software; Content ops
- Use case: Enforce format correctness, diagnose “novelization” drift (Novelization Index), and dialogue–action balance.
- Tools/workflows: Fast, rule-based linter with zero API cost; pre-commit hooks for script repositories.
- Assumptions/dependencies: Fountain format; adapters needed for Final Draft/Celtx.
- Data-driven coverage support and contest screening
- Sector: Competitions, agencies, platforms (e.g., Wattpad/INK community portals)
- Use case: Triage large volumes by filtering low ENR and high logic-break scripts; provide reviewers with dimension-tagged excerpts.
- Tools/workflows: Batch evaluator + reviewer UI with heatmaps per dimension and labeled examples.
- Assumptions/dependencies: Reviewer training to interpret labels; transparency to entrants about automated triage.
- Classroom grading rubric and practice feedback for screenwriting courses
- Sector: Education (EdTech, universities)
- Use case: Give students structured feedback on emotional arcs, conflict handling, and character voice distinctiveness.
- Tools/workflows: LMS plug‑in that attaches a DramaBench-based rubric to assignments; before/after metrics for revisions.
- Assumptions/dependencies: Faculty calibration; use as formative feedback given evaluator disagreement on some dimensions.
- Error taxonomy–guided prompt engineering and fine-tuning
- Sector: AI R&D; Vendors; Studios building internal models
- Use case: Use labeled errors (e.g., redundant beats, prose drift) to refine prompts or curate fine-tuning corpora.
- Tools/workflows: Export error distributions per model; targeted prompt templates to fix frequent failure modes.
- Assumptions/dependencies: Access to evaluation labels; iterative loop to validate gains with significance tests.
- Task routing to specialized models by dimension
- Sector: Media & entertainment; AI tooling
- Use case: Route “emotion pass” to a model strong in Emotional Depth (e.g., Qwen3-Max) and “logic pass” to a model strong in Logic (e.g., GPT‑5.2); keep a human in the loop to reconcile.
- Tools/workflows: Orchestration scripts applying dimension-specific passes; merge tooling with diff views.
- Assumptions/dependencies: Editorial reconciliation effort; consistent style control; API costs.
- Scene-boundary-aware data prep for continuation tasks
- Sector: AI data engineering; Tooling
- Use case: Build realistic continuation datasets by splitting on scene headings rather than token counts.
- Tools/workflows: Use the provided boundary optimization algorithm for dataset construction and evaluation.
- Assumptions/dependencies: Reliable scene markers; domain adaptation for non-screenplay genres.
Long-Term Applications
These applications require further research, scaling, or development before broad deployment.
- Reward modeling and DPO for creative writing using extracted labels
- Sector: AI R&D; Vendors
- Use case: Train reward models on DramaBench’s structured labels (beats, OOC, logic) to optimize models for narrative quality.
- Tools/workflows: RLHF/DPO pipelines with per-dimension rewards; continual evaluation loops.
- Assumptions/dependencies: High-quality, diverse labeled data; mitigation of evaluator bias via ensembles.
- Multi-evaluator ensemble judging to reduce bias and increase reliability
- Sector: AI evaluation
- Use case: Aggregate labels from multiple LLM judges (e.g., GPT, Claude, Gemini) via consensus to address weak agreement areas.
- Tools/workflows: Adjudication protocols; confidence-weighted voting; calibration against larger human panels.
- Assumptions/dependencies: Extra API cost; ensemble design and calibration effort.
- Real-time co-writing copilot with proactive, dimension‑aware suggestions
- Sector: Screenwriting software; Productivity tools
- Use case: As authors type, the copilot flags logic contradictions, suggests beat-level escalations, and proposes on-voice rewrites.
- Tools/workflows: Streaming evaluators; local caching; UX for non-intrusive guidance and one-click fixes.
- Assumptions/dependencies: Low-latency evaluators; more robust Narrative/Character reliability; privacy controls.
- Cross-genre and multilingual extension (feature films, comedy, games, non-English)
- Sector: Media & entertainment; Gaming; Global markets
- Use case: Adapt label sets and metrics to genres (e.g., comedic beats) and locales; support non-English scripts/formats.
- Tools/workflows: Genre-specific annotation schemas; parsers for Final Draft/Celtx; multilingual evaluators.
- Assumptions/dependencies: New training/validation data; cultural/genre expertise; robust format converters.
- Standards and certification for creative AI quality and transparency
- Sector: Policy & standards; Industry consortia
- Use case: Define a public benchmark suite and reporting format (per-dimension scores, significance tests) for creative AI tools.
- Tools/workflows: Open test sets; third-party audit services; “Quality badge” programs for creative apps.
- Assumptions/dependencies: Stakeholder alignment; governance for dataset/versioning; incentives for vendor participation.
- Narrative QA for game writing and live-service content
- Sector: Gaming
- Use case: Continuous QA of quests/NPC dialogue for character consistency and logic across patches.
- Tools/workflows: Integration with narrative CMS; nightly checks flagging OOC lines and contradictions.
- Assumptions/dependencies: Adaptation of annotation units to branching structures; game-specific persona/profile extraction.
- Automated orchestration of director–actor agent systems with metric feedback
- Sector: AI agents for content creation
- Use case: Close the loop in multi-agent writers’ rooms (planner, character agents) using DramaBench metrics as rewards.
- Tools/workflows: Agent frameworks with per-pass scoring and rewrites until targets are met.
- Assumptions/dependencies: Stable reward signals; prevention of reward hacking; compute budget.
- Marketplace and platform ranking for user-generated scripts
- Sector: Creator platforms; Publishing
- Use case: Assist discovery by surfacing works with strong conflict handling and emotional arcs; provide creators with feedback.
- Tools/workflows: Batch scoring pipelines; creator dashboards; opt‑in evaluation policies.
- Assumptions/dependencies: Fairness/transparency; genre-aware thresholds; community acceptance.
- Regulatory or procurement checklists for public-sector creative AI pilots
- Sector: Public policy; Procurement
- Use case: Adopt multi-dimensional evaluation as a requirement for acquiring creative AI tools (e.g., educational content generators).
- Tools/workflows: Standardized test runs; significance reporting; risk assessments for evaluator bias.
- Assumptions/dependencies: Policy guidance; budget for independent evaluations; adaptation to non-drama content.
- Cross-domain adaptation to other long-form generation (novels, comics, ad storyboards)
- Sector: Publishing; Advertising; EdTech
- Use case: Re-map annotation units (e.g., paragraph-level beats) to evaluate plot advancement, character voice, and logic in prose or visual narratives.
- Tools/workflows: Domain-specific label sets; fact extraction tuned to modality; human validation studies.
- Assumptions/dependencies: New gold data; modality alignment (e.g., panel/beat mapping in comics); evaluator retraining.
- Continuous integration for narrative assets in production pipelines
- Sector: Studio tech ops; Tooling
- Use case: Treat scripts as code—run CI checks on each commit and block merges when Logic Break Rate or Drop Rate regress.
- Tools/workflows: Git hooks; dashboards with trend lines; alerting on regressions.
- Assumptions/dependencies: Team adoption of version control; tuned thresholds per show/genre.
These applications leverage the paper’s core innovations—six-dimension, annotation-unit–aware evaluation; structured LLM labeling aggregated into objective metrics; and reproducible, statistically validated comparisons—to create practical tools and workflows for creative AI development, deployment, and governance.
Glossary
- Ablation studies: Controlled removals/variations used to test whether components capture independent effects. "Our ablation studies confirm all six dimensions capture independent quality aspects (mean )."
- Annotation unit: The chosen granularity at which labels are applied during evaluation. "Annotation unit: The granularity of analysis (line-level, event-level, dialogue-level, scene-level, fact-level, or global-level)"
- Arc Score: A binary metric indicating whether a character’s emotion shifts within a scene. "Arc Score: 1 if Shift, 0 if Static"
- Beats per Page: Density measure of plot-advancing beats normalized by script length. "Beats per Page is the most differentiating metric (26/28 significant, 20 large effects)"
- Benjamini-Hochberg FDR correction: Multiple-testing procedure that controls the false discovery rate. "Benjamini-Hochberg FDR correction ()"
- Cloze tests: Fill-in-the-blank evaluation used to assess story understanding rather than generation. "ROCStories \cite{mostafazadeh2016corpus} evaluate story coherence through cloze tests"
- Cohen's kappa: Statistic measuring inter-rater agreement for categorical labels beyond chance. "Cohen's \cite{cohen1960coefficient}"
- Complex Emotion (Complex_Emotion): Label for moments expressing simultaneous opposing emotions. "Detect Complex_Emotion (simultaneous opposing emotions, e.g., bitter smile)"
- Conflict Handling: Evaluation dimension assessing whether the continuation escalates, twists, pauses, resolves, or drops the core conflict. "Conflict Handling"
- Direct Preference Optimization (DPO): Preference-based fine-tuning method that uses labeled comparisons to optimize model outputs. "labels serve as training data for DPO or reward modeling"
- Driver beat: A story beat that advances the plot through meaningful events. "
driver beat'' vsstatic beat''" - Effective Narrative Rate (ENR): Ratio of plot-advancing beats to total beats, indicating narrative efficiency. "Mean ENR across all models is 93.3\%, indicating high plot progression density."
- Error taxonomy: Systematic categorization of error types to analyze model failures. "In-depth error taxonomy classifying 10,850 errors"
- Fountain (screenplay format): Plain-text markup standard for screenplays used for rule-based format checks. "using Fountain format specification \cite{fountain2012}"
- Human-LLM agreement analysis: Assessment of consistency between human annotations and LLM-generated labels. "Human-LLM agreement analysis reveals that Qwen3-Max exhibits systematic biases on narrative efficiency and character consistency."
- Inter-annotator agreement: Measure of consistency among human evaluators assessing the same items. "low inter-annotator agreement"
- LLM-as-a-Judge: Approach where LLMs directly score output quality, often with reliability concerns. "LLM-as-a-Judge approaches that ask models to directly score quality"
- Logic Break Rate: Metric quantifying the rate at which continuation contradicts context facts. "Logic Break Rate: $\frac{N_{\text{violated}{N_{\text{violated} + N_{\text{maintained}$"
- Mann-Whitney U test: Nonparametric test for differences between two distributions based on ranked data. "We conducted 252 Mann-Whitney U tests \cite{mann1947test}"
- Novelization Index: Ratio indicating the degree of prose-like narration versus screenplay-appropriate action. "Novelization Index: Ratio of prose-like narrative to screenplay-appropriate action (target: )"
- Out-Of-Character (OOC): Dialogue or behavior violating an established persona without justification. "Objective: Detect Out-Of-Character (OOC) behavior."
- Persona profiles: LLM-derived summaries of characters’ speech patterns and traits used to judge consistency. "LLM generates persona profiles from context \cite{li2016persona}, capturing speech patterns and personality traits."
- Position bias: Systematic preference based on the order or placement of items in evaluation. "noting issues with position bias, verbosity bias, and inconsistent criteria application."
- Redundant beat: A story beat that repeats known information without adding new value. "Redundant: Repeats known information"
- Reward modeling: Training a model using a learned reward signal derived from labels or preferences. "labels serve as training data for DPO or reward modeling"
- Scene-boundary-aware algorithm: Splitting method that aligns context/continuation at natural scene boundaries. "using a scene-boundary-aware algorithm:"
- Spearman correlations: Rank-based correlation measure used to assess dimension independence. "We computed Spearman correlations between dimension pairs across 8,824 evaluations."
- Static beat: A descriptive action that does not advance the plot. "Static: Descriptive actions (e.g., looking out window, lighting cigarette)"
- Story beats: Atomic narrative events extracted from action descriptions to analyze plot progression. "story beats \cite{mckee1997story,snyder2005savethecat} extracted from action descriptions"
- Valence-Arousal model: Two-dimensional affect framework categorizing emotions by positivity and activation. "using the Valence-Arousal model \cite{russell1980circumplex} (Valence: Positive/Negative, Arousal: High/Low)"
- Voice Distinctiveness: Metric assessing how distinguishable and persona-consistent character dialogue is. "Voice Distinctiveness: $\frac{N_{\text{in-character}{\text{Total Dialogue}$"
Collections
Sign up for free to add this paper to one or more collections.