- The paper presents RLMR, a novel reinforcement learning framework that dynamically balances subjective writing quality with constraint adherence.
- RLMR employs Group Relative Policy Optimization (GRPO) to penalize constraint violations while preserving creative expression.
- Experiments across models from 8B to 72B parameters show improved instruction following and overall performance over fixed-weight baselines.
Reinforcement Learning with Mixed Rewards for Creative Writing
Introduction
The study titled "RLMR: Reinforcement Learning with Mixed Rewards for Creative Writing" (2508.18642) addresses the challenges encountered when deploying LLMs in creative writing. Creative writing demands balancing subjective qualities like emotional depth and originality with objective constraints like format adherence and word limits. Traditional single reward strategies are inadequate, as they cannot simultaneously optimize these dual dimensions. Fixed-weight mixed reward strategies also fall short due to their inability to adapt to diverse writing scenarios. The paper introduces Reinforcement Learning with Mixed Rewards (RLMR), featuring a dynamic system combining evaluations from both subjective writing quality and objective constraint adherence models.
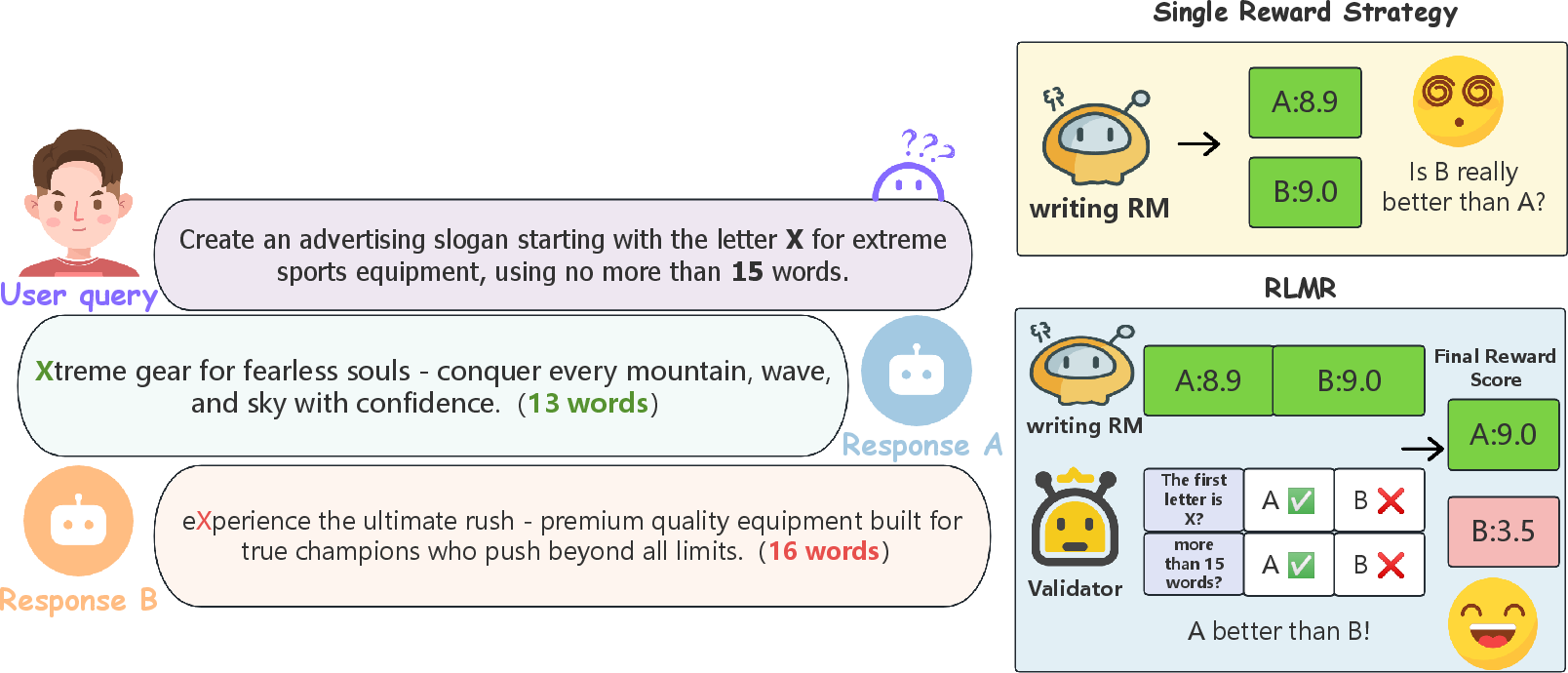
Figure 1: Comparison of single reward strategy versus our mixed RLMR approach. Given a task requiring an advertising slogan starting with "X" using no more than 15 words, Response A follows constraints but scores lower (8.9), while Response B violates constraints but scores higher (9.0). Single reward strategies incorrectly prefer Response B, while our RLMR combines writing quality and instruction following signals to correctly identify Response A as superior through dynamic penalty adjustments.
The innovative strategy dynamically adjusts reward weights based on the sampled group's writing quality, ensuring samples violating constraints receive penalties proportionate to their deviation. This comprehensive approach leverages Group Relative Policy Optimization (GRPO) for efficient online reinforcement learning, addressing creative writing optimization with a focus on multi-dimensional reward signals.
RLMR Framework
The RLMR framework integrates subjective and objective evaluations through two distinct models: a writing reward model and a constraint verification model. The writing reward model assesses subjective elements such as literary expression and coherence, trained using human preference pairs to refine its judgment capabilities. Simultaneously, the constraint verification model checks adherence to prescribed requirements, employing logical conjunctions to confirm compliance.
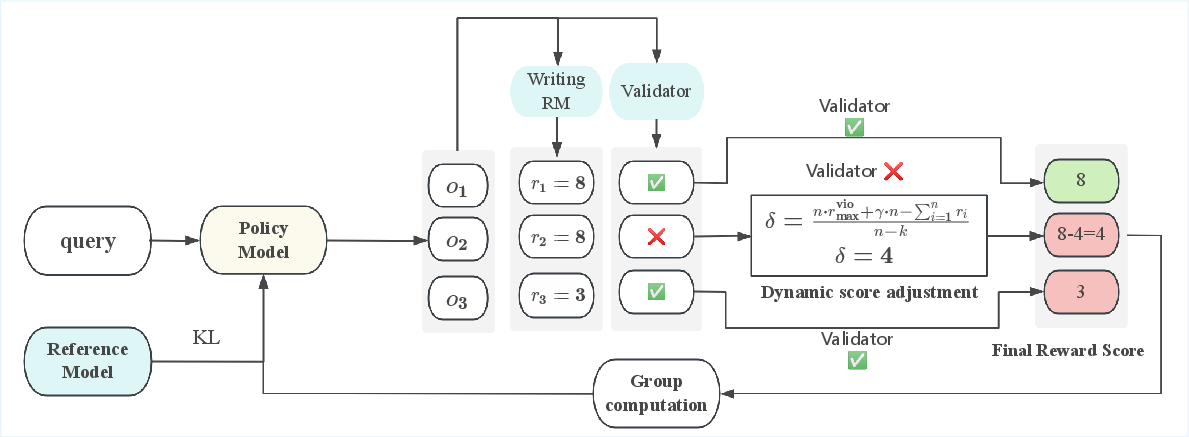
Figure 2: Overview of our Dynamic Mixed-Reward GRPO Framework. The policy model generates responses (o1,o2,o3) evaluated by both writing quality (Writing RM) and constraint compliance (Validator).
To overcome the limitations associated with fixed-weight strategies, the RLMR dynamically adjusts rewards by calculating penalties for constraint violations. This ensures that samples violating constraints receive negative advantages during training, thereby optimizing both writing quality and instruction following. The penalty term δ is dynamically computed to maintain constraint adherence without compromising creative output.
Experimental Evaluation
Extensive experiments validate the RLMR framework across multiple model families and scales, implementing both automated and manual evaluations.
Automated Evaluation:
The framework was tested on models ranging from 8B to 72B parameters, showcasing substantial improvements over baseline methods. On benchmarks like WriteEval and IFEval, the RLMR approach consistently outperformed single-reward and fixed-weight baseline methods, indicating a robust ability to balance writing quality with constraint adherence.
Manual Evaluation:
In human evaluation, RLMR showed superior scores in Instruction Following, Content Quality, and Overall Performance. The method achieved higher user satisfaction levels, confirming its practicality in real-world scenarios.
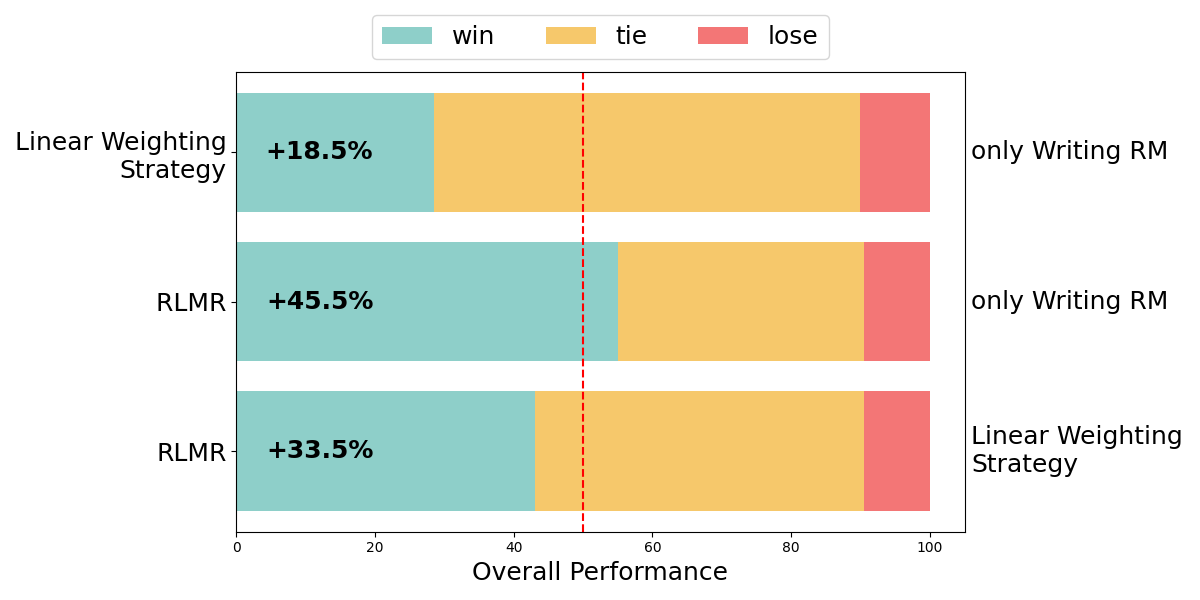
Figure 3: Pairwise comparison results for Overall Performance. "Win" indicates the left method outperforms the right method; "tie" indicates comparable performance; "lose" indicates the left method underperforms. The red dashed line represents equal performance (50\%). RLMR demonstrates significant advantages over both baseline methods.
Implications and Future Directions
The study provides a viable framework for optimizing LLMs in complex creative writing tasks through a dual focus on subjective quality and objective adherence. It implies potential applications beyond creative writing, including dialogue systems and code generation, where the integration of multiple dimensional reward signals can offer significant benefits.
Future research should explore expanding the dynamic reward system to other multi-signal environments and explore optimizing the balance between subjective preferences and objective constraints in diverse application domains.
Conclusion
The "RLMR: Reinforcement Learning with Mixed Rewards for Creative Writing" research introduces a novel dynamic mixed-reward framework that significantly enhances creative writing optimization. By effectively balancing subjective and objective evaluation criteria, RLMR offers a robust solution to the inherent challenges of creative writing tasks. The framework's contributions mark a step forward in reinforcement learning strategies, promising new horizons in AI-driven creativity and operational efficacy.

