- The paper demonstrates that both LLM-as-a-Judge and multi-agent refined rewards significantly boost creative writing in SLMs, with the judge method achieving state-of-the-art excellence rates.
- It details a dual methodology using a reward model via multi-agent debate and a principle-guided adversarial-reflective mechanism for generating discrete binary rewards through GRPO optimization.
- Empirical results, including human-model agreement rates up to 87%, underscore improved training efficiency and reduced dependency on human annotations for creative tasks.
Enhancing Creative Writing in Small LLMs: Comparative Analysis of LLM-as-a-Judge and Multi-Agent Refined Rewards
Introduction
The paper "Igniting Creative Writing in Small LLMs: LLM-as-a-Judge versus Multi-Agent Refined Rewards" (2508.21476) addresses the challenge of augmenting creative writing capabilities in Small LLMs (SLMs), specifically focusing on the generation of Chinese greetings. The work systematically compares two AI-driven reward strategies within a Reinforcement Learning from AI Feedback (RLAIF) framework: (1) a multi-agent system for preference data curation and reward model (RM) training, and (2) a principle-guided LLM-as-a-Judge paradigm, optimized via adversarial training and reflection. The study demonstrates that both approaches substantially improve creative output over baselines, with the LLM-as-a-Judge method yielding superior generation quality, training efficiency, and reduced reliance on human-annotated data.
Methodological Frameworks
Multi-Agent Rejection Sampling and Reward Model Training
The multi-agent framework operationalizes collaborative evaluation by decomposing the assessment process into specialized agents: Retrieval, Positive, Negative, Judge, and Reflect. The Retrieval Agent provides contextual grounding via high-quality prompt-response pairs. The Positive and Negative Agents conduct adversarial debate, surfacing strengths and weaknesses of candidate responses. The Judge Agent synthesizes these perspectives, while the Reflect Agent performs error analysis and ratification, ensuring logical consistency and completeness.
This multi-agent system generates high-fidelity preference data, which is used to train a scalar reward model via LoRA-based fine-tuning on a backbone LLM. The reward model is optimized using the Bradley–Terry loss, enabling it to predict nuanced preferences for creative writing tasks.
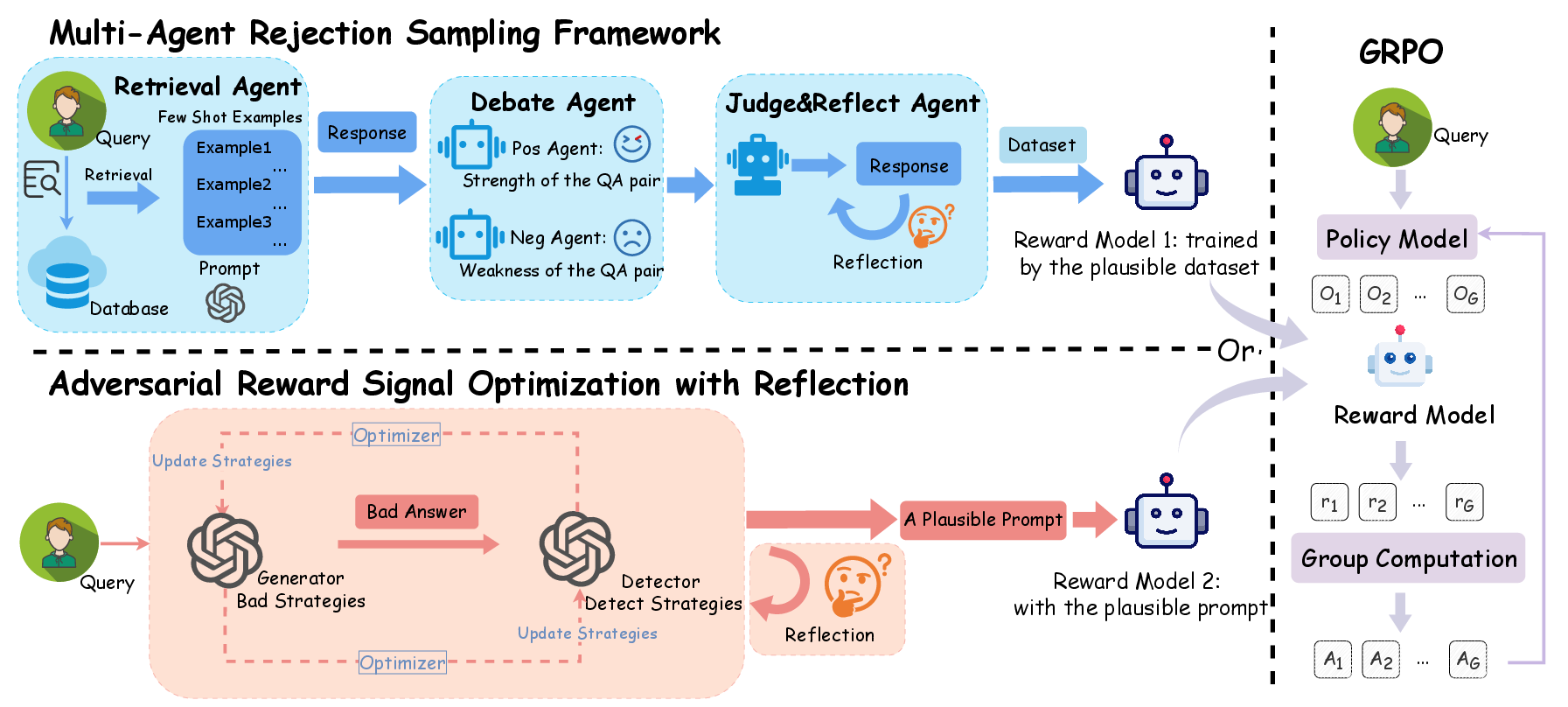
Figure 1: Two distinct reward signals: Signal 1 from a multi-agent system yielding a reward model, and Signal 2 from adversarial interaction and reflection, both used to train GRPO.
Principle-Guided LLM-as-a-Judge with Adversarial Optimization
The LLM-as-a-Judge paradigm leverages a powerful LLM as a direct reward provider, guided by explicit creative writing principles. The reward function is optimized through adversarial training involving a Generator (producing challenging "bad" responses) and a Detector (discriminating response quality). A Reflector module further enhances the Detector's reliability by providing supervised feedback on misclassifications, grounding the learning process with true-labeled data.
This approach produces a discrete binary reward signal, which is directly used for policy optimization via the GRPO algorithm. The adversarial-reflective loop iteratively refines the evaluation prompt and the Detector's discriminative capacity.
Experimental Design and Evaluation
Task and Dataset Construction
The study focuses on the culturally rich domain of Chinese greetings, leveraging datasets for retrieval augmentation, reward model training, policy optimization, and final evaluation. The evaluation rubric encompasses five weighted dimensions: Language Quality, Creativity, Emotional Resonance, Cultural Appropriateness, and Content Richness. Human experts, all native Chinese speakers with graduate-level education, provide rigorous multi-dimensional assessments.
Automated and Human Evaluation Alignment
Empirical results indicate strong alignment between automated evaluation frameworks and human judgments, with agreement rates consistently exceeding 70% and peaking at 87% for the multi-agent system.
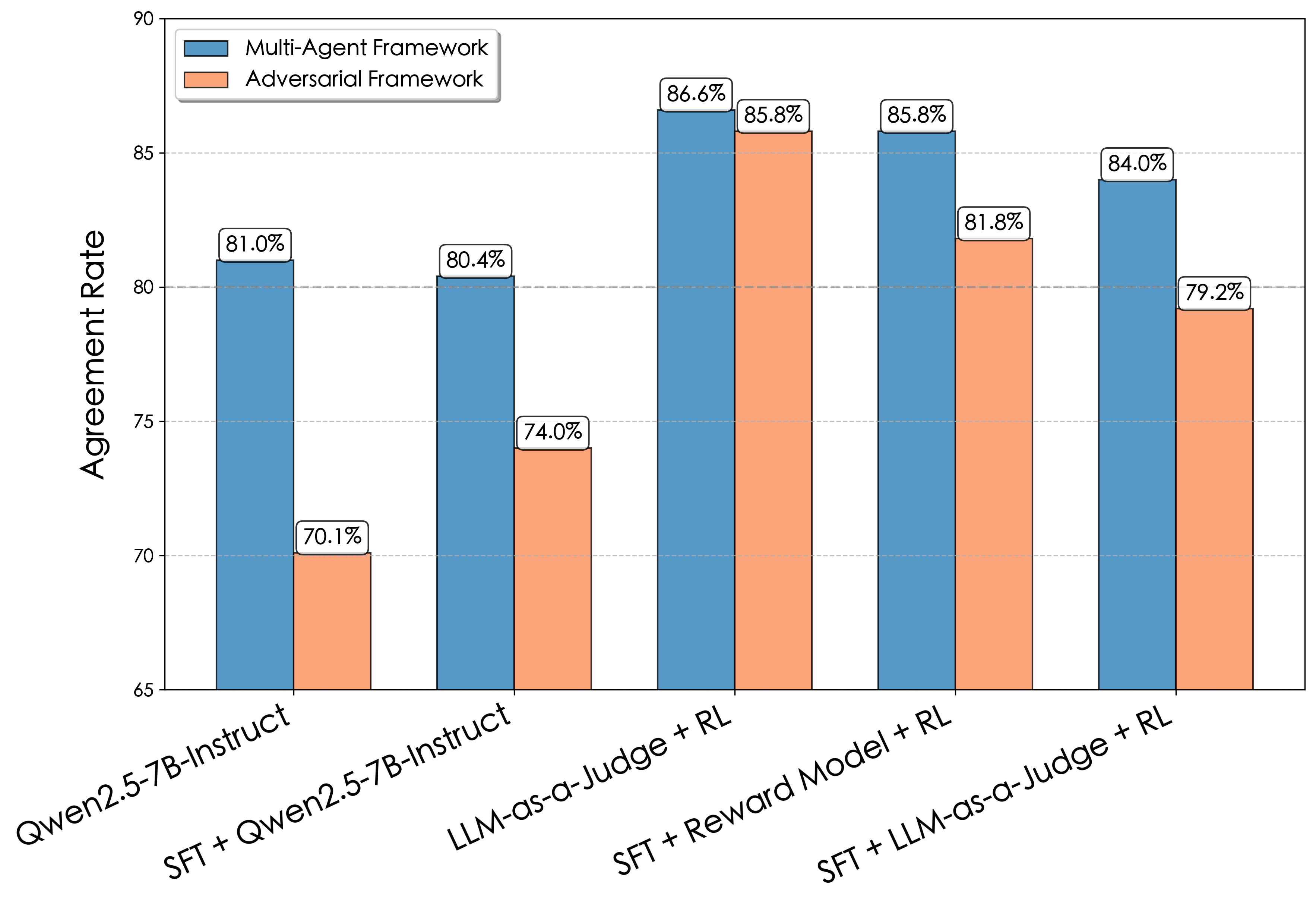
Figure 2: Agreement rate comparison between models and human evaluators under two evaluation frameworks.
Comparative Results and Ablation Analysis
Reward Model + RL vs. LLM-as-a-Judge + RL
Both reward strategies significantly outperform SFT-only baselines and mainstream LLMs in generating high-quality greetings. The SFT+RM+RL pipeline achieves notable gains in excellence rates across evaluation metrics. However, the LLM-as-a-Judge + RL approach achieves state-of-the-art performance, with excellence rates of 92.4%, 96.6%, and 95.0% across three metrics, surpassing GPT-4o, Ernie-4.5, and DeepSeek-V3.
Training efficiency is markedly higher for LLM-as-a-Judge, which circumvents the complexity and resource demands of multi-agent data curation. The adversarial-reflective optimization yields a robust, principle-guided evaluation prompt, streamlining reward signal generation.
Figure 3: Training metrics of LLM-as-a-Judge + RL, illustrating stable and effective policy optimization.
Ablation Study
Ablation experiments confirm the criticality of each agent in the multi-agent framework. Removal of debate agents leads to catastrophic drops in recall and precision, underscoring the necessity of adversarial debate for balanced assessment. The Reflect Agent is pivotal for error correction and reliability in both frameworks, with its absence causing significant declines in accuracy and F1-score.
Qualitative Analysis
Case studies illustrate the nuanced evaluation process, with Positive and Negative Agents articulating advantages and disadvantages of candidate responses. Prompts for each agent are meticulously designed to elicit comprehensive assessments.

Figure 4: Example of positive and negative agent outputs for a given query and response.
Implementation Considerations
The reward model is implemented using Llama Factory and LoRA, trained on preference pairs with the Bradley–Terry loss. GRPO-based policy optimization is conducted on Qwen2.5-7B-Instruct, with hyperparameters tuned for stability and efficiency. Experiments utilize four NVIDIA A100 GPUs (80GB each), ensuring scalability for real-world deployment.
Implications and Future Directions
The demonstrated efficacy of principle-guided LLM-as-a-Judge for creative writing in SLMs has several practical and theoretical implications:
- Scalability: The reduced dependency on human annotation and streamlined reward signal generation facilitate broader deployment of SLMs in resource-constrained environments.
- Generalizability: While the study focuses on Chinese greetings, the frameworks are extensible to other creative domains and languages, pending further validation.
- Bias and Subjectivity: The explicit definition of creative principles and multi-agent debate mitigate, but do not eliminate, the risk of embedding cultural or societal biases. Future work should explore adaptive principle sets and deeper reflection mechanisms.
- Model Size and Efficiency: The approaches are validated on 7B-parameter SLMs; exploration of their efficacy on smaller or larger models is warranted.
Conclusion
This paper provides a rigorous comparative analysis of two AI-driven reward strategies for enhancing creative writing in SLMs. Both the multi-agent refined RM and the principle-guided LLM-as-a-Judge approaches yield substantial improvements over baselines, with the latter offering superior generation quality, training efficiency, and scalability. The strong alignment between automated and human evaluations substantiates the viability of these methods for subjective generative tasks. The findings pave the way for efficient, high-quality creative text generation in compact LLMs, with broad applicability across domains and languages.