- The paper introduces MiniRAG, enhancing efficiency with graph-based methods for retrieval-augmented generation in resource-constrained settings.
- Innovative techniques include heterogeneous graph indexing, improving semantic understanding without relying on complex language models.
- Performance evaluations show MiniRAG achieving competitive results against LLM systems, yet utilizing a quarter of the storage space.
MiniRAG: Towards Extremely Simple Retrieval-Augmented Generation
Introduction
The paper "MiniRAG: Towards Extremely Simple Retrieval-Augmented Generation" presents novel methodologies to improve the efficiency and deployability of Retrieval-Augmented Generation (RAG) systems, particularly in resource-constrained environments. Unlike existing systems that heavily rely on LLMs, MiniRAG aims to leverage Small LLMs (SLMs) by addressing their limitations through innovative graph-based techniques.
Technical Innovations
MiniRAG introduces two principal technological advancements: heterogeneous graph indexing and lightweight graph-based retrieval. These advancements provide a mechanism to offset the limitations commonly associated with SLMs, such as limited semantic understanding and reduced text processing capabilities:
- Heterogeneous Graph Indexing: This indexation strategy systematically combines text chunks and named entities into a unified graph structure, allowing more semantic awareness without depending on advanced LLM capabilities.
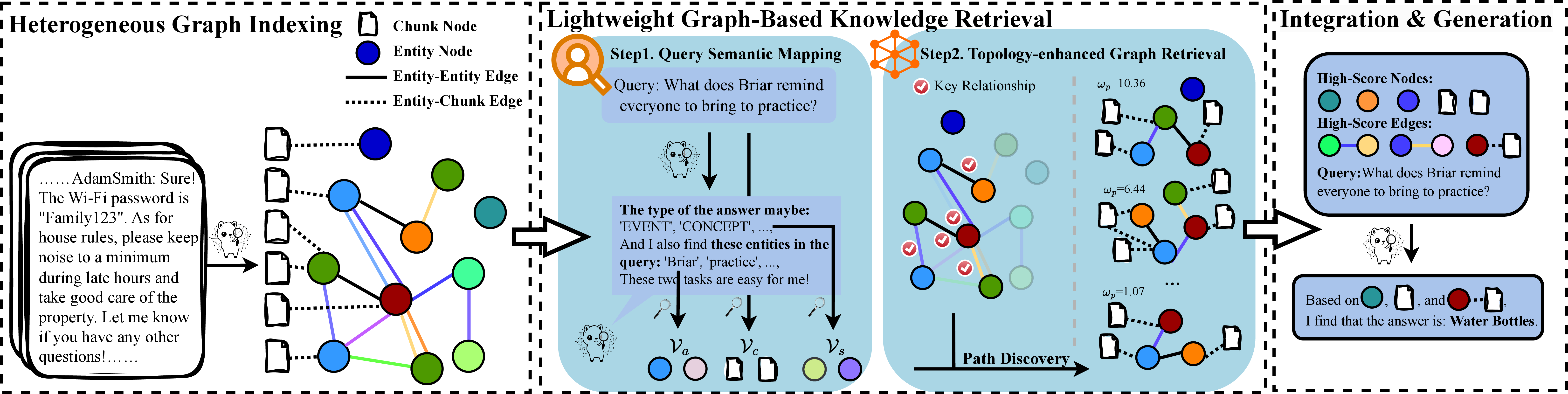
Figure 1: The MiniRAG\ employs a streamlined workflow built on the key components: heterogeneous graph indexing and lightweight graph-based knowledge retrieval. This architecture addresses the unique challenges faced by on-device RAG systems, optimizing for both efficiency and effectiveness.
- Lightweight Topology-Enhanced Retrieval: This approach leverages the graph structure to perform efficient knowledge discovery with minimal reliance on complex language capabilities. It utilizes heuristic patterns to navigate the knowledge graph, facilitating efficient information retrieval.
These innovations empower MiniRAG to maintain competitive RAG performance with significantly reduced resource requirements.
The efficacy of MiniRAG was demonstrated through comprehensive evaluations under various settings and benchmarks. Key findings from the experiments include:
- Performance Efficiency: MiniRAG showed performance parity with systems deploying LLMs while only utilizing about 25% of the storage space. Moreover, it maintained high retrieval accuracy with small models, exhibiting robustness even when transitioning from LLMs to SLMs.

Figure 2: Compared to LLMs, Small LLMs (SLMs) show significant limitations in both indexing and answering phases. Left: SLMs generate notably lower-quality descriptions than LLMs. Right: When processing identical inputs, SLMs struggle to locate relevant information in large contexts, while LLMs perform this task effectively.
- Comparative Analysis: Against existing RAG systems like LightRAG and GraphRAG, MiniRAG demonstrated superior effectiveness by maintaining higher accuracy rates and lower error rates across different datasets. This is especially notable considering MiniRAG's streamlined approach.
Practical Implications
MiniRAG's design is an excellent fit for deployment in environments where computational resources are limited. This includes applications on edge devices, real-time processing systems, and privacy-sensitive domains. The reduction in complexity and resource requirements expands the capability of deploying RAG systems in more varied and constrained contexts.
Conclusion
MiniRAG represents a significant step forward in making Retrieval-Augmented Generation systems more accessible and efficient in constrained environments. Through its novel graph-based innovations, it addresses the gap in current RAG architectures that heavily depend on LLMs. By demonstrating competitive performance with reduced model dependencies, MiniRAG opens avenues for future research into lightweight, on-device RAG systems that prioritize efficiency over complexity.

