- The paper proposes the ICRL framework where LLMs leverage scalar rewards in multi-round prompting to exhibit reinforcement learning behaviors.
- It achieves notable improvements, with a 90% success rate in Game of 24 and up to 93.81% coherence in creative writing.
- Ablation studies confirm that integrating rewards is vital, marking a transformative shift in dynamically enhancing LLM responses.
Reward Is Enough: LLMs Are In-Context Reinforcement Learners
Introduction
The paper "Reward Is Enough: LLMs Are In-Context Reinforcement Learners" investigates the unexpected emergence of reinforcement learning (RL) behaviors within LLMs during inference, termed in-context reinforcement learning (ICRL). By proposing a multi-round prompting framework known as ICRL prompting, the authors explore how LLMs can be prompted to improve task performance through RL-like processes during inference. This framework systematically prompts LLMs with a task, receives a scalar reward as feedback, and iteratively refines the model's responses. The paper evaluates ICRL prompting using benchmarks such as Game of 24, creative writing, and ScienceWorld, revealing significant improvements compared to baseline methods like Self-Refine and Reflexion.
ICRL Prompting Framework
The ICRL prompting framework includes the components of LLMs, reward functions, memory for experiences, and specific instructions for facilitating exploration and exploitation. An LLM, denoted as πθ, acts as a policy network to generate responses. Scalar rewards provide numerical feedback, guiding the model to improve its responses in subsequent trials. Experiential memory stores trajectories of previous responses and rewards, allowing the model to learn from its history. Instructions during initial prompting are crucial: exploration prompts the generation of novel responses, while exploitation encourages selecting responses that maximize historical rewards.
Experimental Evaluation
The experiments conducted across three diverse benchmarks highlight the effectiveness of ICRL prompting.
Game of 24: A math-based challenge where four numbers are manipulated using arithmetic operations to achieve 24. Comparison with baselines showed ICRL achieving a 90% success rate, outperforming best-of-N sampling and Self-Refine that achieved only 49% and 47% success rates, respectively.
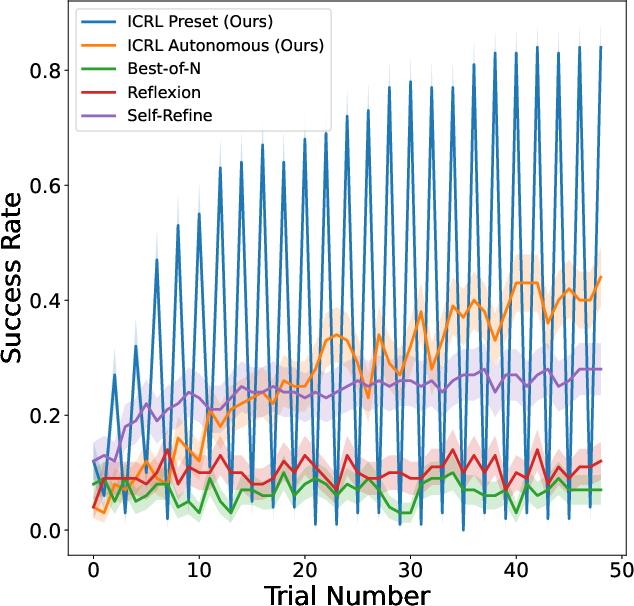
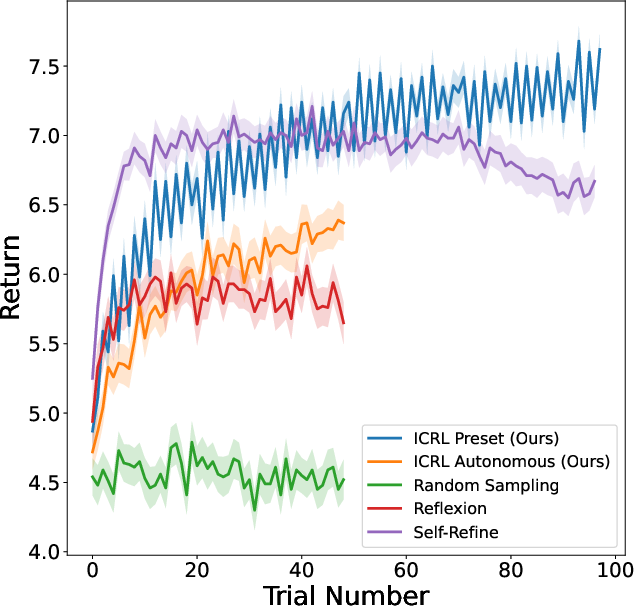
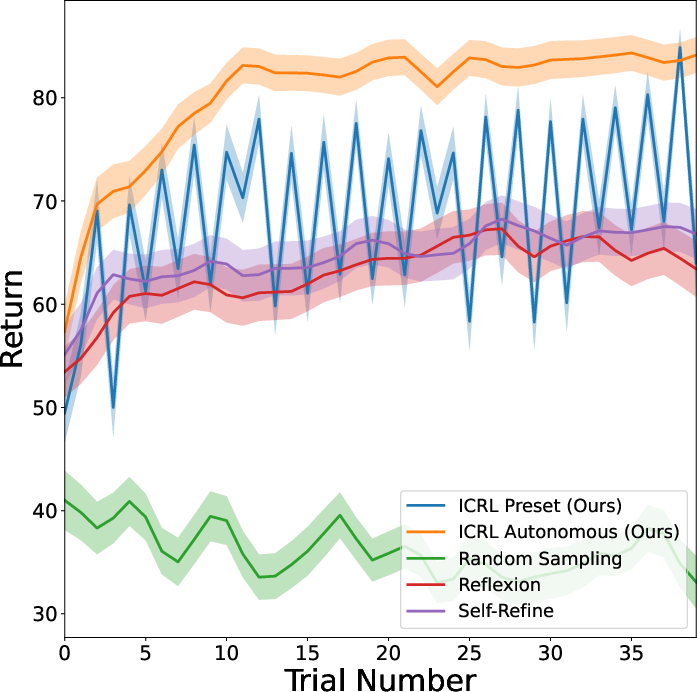
Figure 1: Baseline Method Comparison. (Left) Mean Success Rate on Game of 24. (Middle) Mean Coherence Reward on Creative Writing. (Right) Mean Return on Science World.
Creative Writing: Models were tasked with writing coherent paragraphs, integrating supplied sentences. ICRL prompting outperformed baselines in coherence, achieving up to 93.81% in length-controlled win rate against other techniques, highlighting superior narrative development.
ScienceWorld: Tasks involving interactive scientific experiments evaluated in arbitrary environments. ICRL demonstrated superior performance with a mean return benchmark of 88, illustrating its adaptability in complex multi-step tasks.
Ablation Studies
The ablation studies examined the individual contributions of different framework components. Results indicated that rewards were pivotal; performance dropped significantly when rewards were set to zero or when context length was restricted. Exploration alone did not suffice; the integration of rewards proved crucial for achieving notable improvements in generating novel and higher-quality responses.
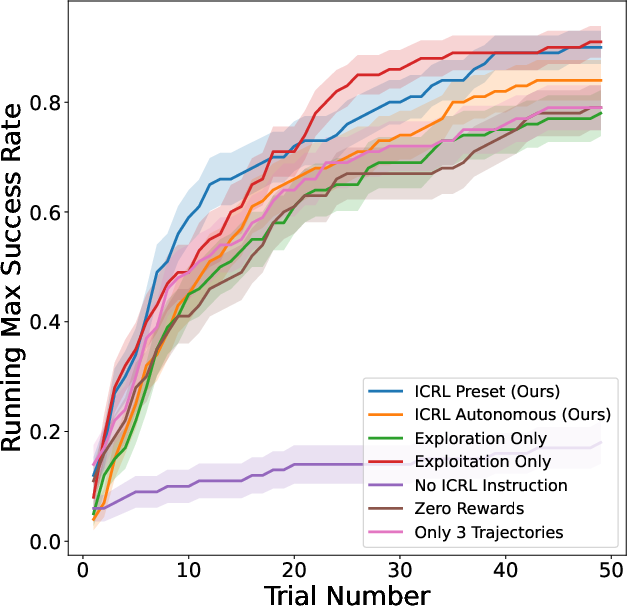
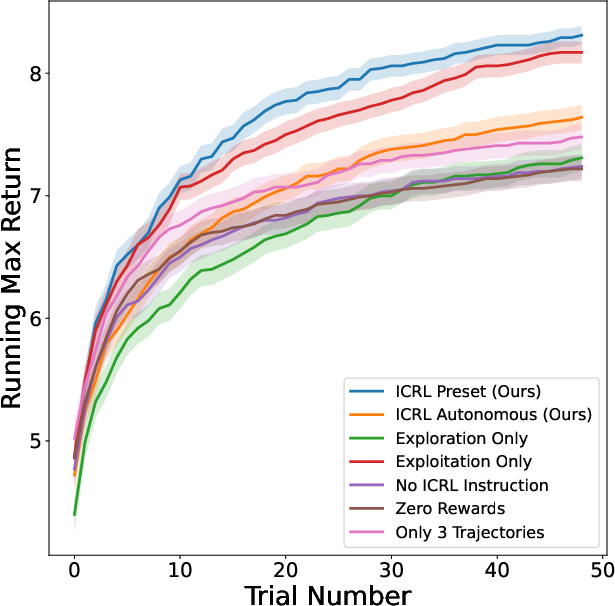
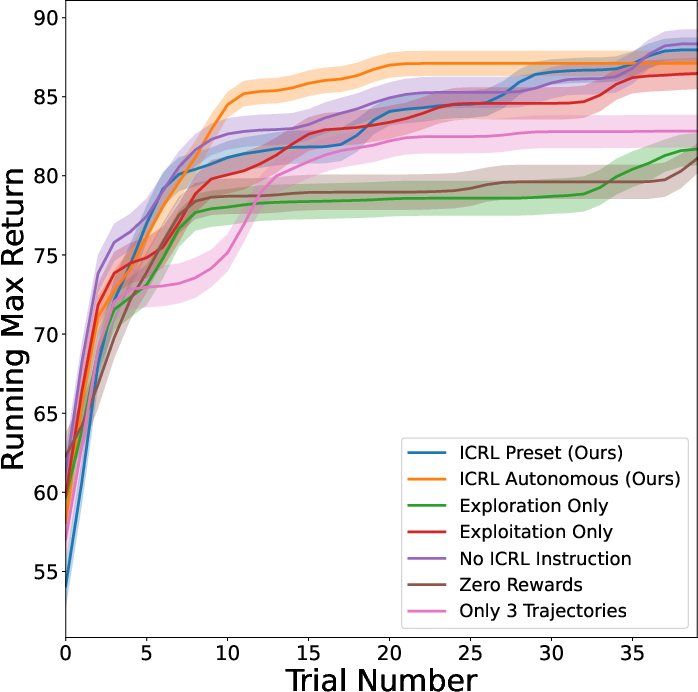
Figure 2: Ablation Studies (Running Max). (Left) The mean of running max success rate on Game of 24. (Middle) The mean of running max coherence reward on creative writing. (Right) The mean of running max return on ScienceWorld.
Implications and Future Directions
This research demonstrates that LLMs are capable of behaviors analogous to RL during inference without parameter updates. The ability to implement such strategies in real-time opens numerous avenues for enhancing LLM-based applications where continual improvement through interaction history can greatly benefit performance, such as in conversational agents and interactive systems.
Future research directions may include refining reward signal design to improve robustness and scalability. Additionally, exploring alternative ways to construct experiential memory and contextual information could enhance learning effectiveness. Further development will involve optimizing compute efficiency to allow broader applicability in real-world scenarios.
Conclusion
The paper proposes that reward is indeed sufficient for prompting in-context reinforcement learning behaviors in LLMs. This unexpected capability extends the utility of LLMs beyond static NLP tasks into more dynamic and interactive domains. By leveraging an RL-like framework, significant improvements can be achieved, underscoring the transformative potential of integrating rewards into LLM prompting strategies.