- The paper presents a novel framework that leverages RL-derived reward functions as effective process reward models to guide search algorithms.
- It integrates AIRL and GRPO to train policies with dense rewards, eliminating the need for costly labeled data.
- Experiments across eight benchmarks show a 9% average boost in LLM reasoning performance over baseline PRMs during search.
Unifying Reinforcement Learning (RL) and Search-Based Test-Time Scaling (TTS) for LLMs
The paper "Your Reward Function for RL is Your Best PRM for Search: Unifying RL and Search-Based TTS" presents a pioneering methodology that integrates RL-based and search-based TTS for improving the reasoning performance of LLMs. This work introduces a new framework that utilizes the reward function obtained from RL as an effective process reward model (PRM) for guiding search algorithms at test time.
Method Overview
The core idea is to leverage the reward function, which is inherently learned during RL training, as an ideal PRM for guiding search procedures. This unification approach is implemented using Adversarial Inverse Reinforcement Learning (AIRL) combined with Group Relative Policy Optimization (GRPO). The paper demonstrates that the PRM can serve dual purposes: providing dense rewards during training and guiding search strategies during inference, thus reducing the dependence on static PRMs that require extensive labeled data.
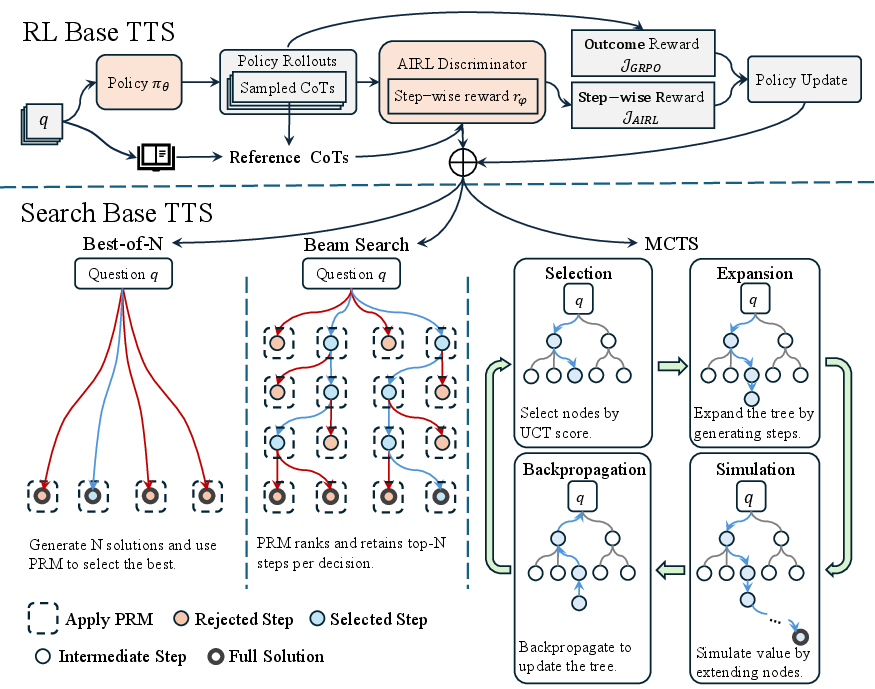
Figure 1: Overview of the unification framework. During training, the AIRL discriminator is used to learn a PRM, optimizing the policy with both dense rewards from AIRL and outcome rewards from GRPO. At test time, the trained policy and PRM jointly guide downstream search algorithms.
Experimental Results
The experiments conducted on eight benchmarks across mathematics, scientific reasoning, and code generation show that this unified approach significantly enhances model performance by 9% on average compared to the base model. Furthermore, when integrated into various search algorithms, the PRM consistently outperforms all baseline PRMs trained with labeled data.
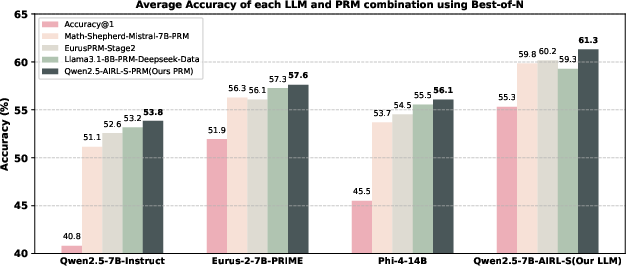
Figure 2: Average performance of four PRMs applied to four generative LLMs using Best-of-N with 64 rollouts on AIME2024, AMC, and MATH500. The AIRL-S-PRM consistently delivers the highest test-time search performance.
Implementation Details
Training Process
The RL training process involves using AIRL to learn a step-wise PRM directly from correct reasoning traces. This eliminates the need for labeled intermediate process data, thereby mitigating costs and avoiding reward hacking risks associated with static PRMs. The policy model is updated using a combination of objectives derived from AIRL and GRPO.
Test-Time Search
At inference, the PRM extends the logic chaining ability of the policy model by guiding search processes such as Monte Carlo Tree Search (MCTS), beam search, and Best-of-N sampling. This is achieved through a framework that applies the learned PRM for real-time decision-making in extending reasoning chains.
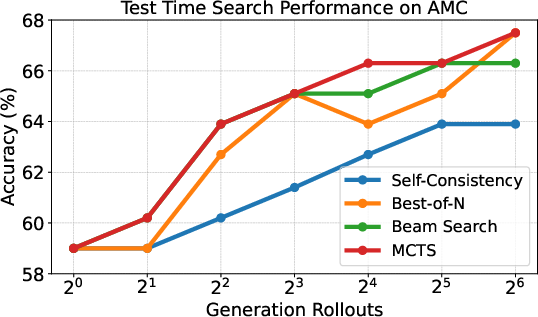
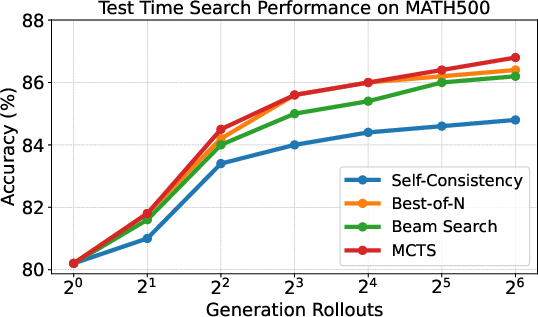
Figure 3: Comparison of test-time search performance with the PRM applied to MCTS, Beam Search, and Best-of-N across varying rollout counts. The PRM consistently improves performance for all search techniques.
Implications and Future Work
The implications of this work extend to several areas:
- Scientific and Educational Tools: The integrated framework can serve as a foundation for developing advanced educational AI tools and scientific computing platforms, lowering barriers to access in under-resourced regions.
- Software Development: In software engineering, incorporating such models could lead to more efficient and reliable code generation systems.
- Future Research Directions: Expanding this unification framework to other architectures and broader datasets could address scalability and generalization, potentially paving the way for more robust AI systems.
Conclusion
This paper establishes a novel unification of RL-based and search-based TTS methodologies, demonstrating practical improvements in LLM performance across diverse reasoning tasks. By repurposing the RL-derived reward function as a versatile PRM, the approach not only enhances inference capabilities but also reduces the reliance on costly labeled datasets, thus offering a cost-efficient and scalable solution for TTS in LLMs. Future work could explore scalability aspects and test the approach on more diverse architectures and applications.

