- The paper introduces a two-stage VQ module that employs hard and soft discretization to align continuous audio inputs with LLM tokens.
- The methodology leverages the LLM's embedding table to initialize a codebook, capturing nuanced phonetic details through a weighted combination of tokens.
- Experimental results on Librispeech and CommonVoice datasets demonstrate improved ASR accuracy and generalization, validating the approach.
Bridging the Modality Gap: Softly Discretizing Audio Representation for LLM-based Automatic Speech Recognition
Introduction
The paper "Bridging the Modality Gap: Softly Discretizing Audio Representation for LLM-based Automatic Speech Recognition" introduces a novel approach to integrating continuous audio representations into LLMs for Automatic Speech Recognition (ASR). Traditional LLM-based ASR architectures face challenges due to the intrinsic differences between the continuous nature of audio data and the discrete token-based structure of LLMs. This research proposes incorporating Vector Quantization (VQ) to address these challenges, facilitating better alignment between audio signals and LLM inputs.
System Architecture and Methodology
The proposed system inserts a VQ module between the audio encoder and the LLM decoder (Figure 1). The VQ module serves to discretize continuous audio embeddings in two stages. Initially, the codebook is initialized using the LLM's embedding table, effectively aligning the audio outputs with discrete LLM tokens. The first stage focuses on hard discretization, where each audio frame is mapped to the closest token in the embedding space based on cosine similarity. This alignment is facilitated by the use of a fixed VQ codebook drawn directly from the LLM's existing vocabulary.
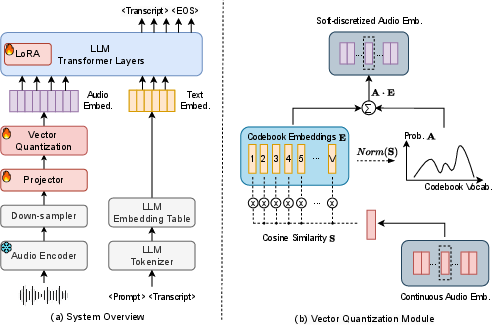
Figure 1: Overall system architecture of the LLM-based ASR with a VQ module, and the design of the VQ module illustrating the soft discretization of audio representations.
The second stage introduces "soft discretization," where a weighted sum of multiple codebook entries refines the audio representation to incorporate more nuanced acoustic information. The softening of discretization allows the audio embeddings to better capture the phonetic nuances critical for ASR tasks while maintaining alignment with linguistic structures.
Experimental Results
The proposed VQ-based approach was evaluated using the Librispeech and CommonVoice datasets. Results highlight that the method outperforms traditional SLAM-ASR baselines, particularly under cross-domain conditions, indicating improved generalization. Importantly, the system maintains strong performance in in-domain scenarios, affirmatively demonstrating that the integration of VQ modules does not impair the ASR's effectiveness in familiar environments.
Embedding visualizations, as seen in Figure 2, further underline the enhanced alignment between audio and text embeddings, showcasing closer clustering with text embeddings from the LLM.
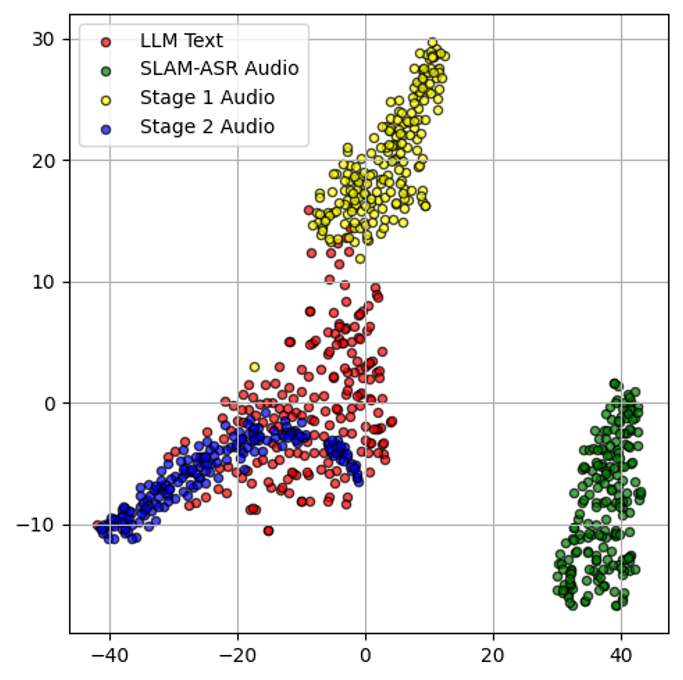
Figure 2: Embedding visualization showing the alignment between audio and text embeddings using t-SNE.
Analysis and Discussion
A critical component of the research is understanding how the discretized audio embeddings correlate with linguistic tokens. The careful construction of the VQ methodology ensures that audio signals are not only mapped accurately to discrete tokens but are also contextually relevant. Figure 3 illustrates tokens with the highest cosine similarity to audio embeddings, shedding light on the effectiveness of stage 1 and stage 2 training strategies
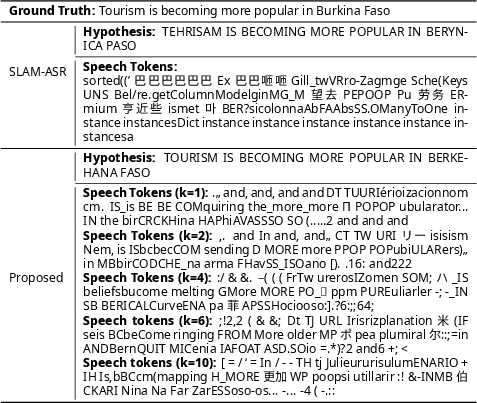
Figure 3: Ground truth, hypothesis, and the text tokens that have the highest cosine similarities with the audio embeddings.
The research also explores the impact of various discretization strategies, comparing hard and soft approaches. It is evident that soft discretization not only preserves more acoustic information but also provides substantial improvements in ASR performance over purely hard discretization methods. The trained VQ module successfully bridges the modality gap, with tokens that reflect both semantic and phonetic similarities to the audio input.
Conclusion
This work demonstrates a significant advancement in bridging the modality gap inherent in LLM-based ASR systems. By employing a two-stage VQ module, the authors effectively align continuous audio representations with the discrete token framework of LLMs. The approach enhances ASR generalization across diverse domains, holding promise for future exploration in integrating audiovisual data with language processing models. The insights gained from this research could inform future endeavors in creating even more adaptable and robust ASR systems that can seamlessly incorporate multi-modal data.