- The paper reveals that cross-modal alignment emerges predominantly in the mid-to-late layers of vision and language models.
- It demonstrates that semantic content, rather than superficial attributes, drives robust alignment between modalities.
- The study finds that aggregation of embeddings enhances semantic coherence, reflecting human-like judgment in image-caption tasks.
Seeing Through Words, Speaking Through Pixels: Deep Representational Alignment Between Vision and LLMs
Overview
The paper "Seeing Through Words, Speaking Through Pixels: Deep Representational Alignment Between Vision and LLMs" investigates the degree of alignment between separately trained vision and LLMs and explores where in these models such convergence occurs. The study provides insights into the shared semantic space between unimodal networks and how they capture human-like judgments.
Cross-Modal Alignment Emergence
The research identifies that alignment emerges prominently in the mid-to-late layers of both vision and LLMs. This observation underscores a transition from modality-specific processing to a shared, abstract conceptual space. Notably, while early layers exhibit weak cross-modal predictivity, predictivity strengthens and aligns toward the latter layers.
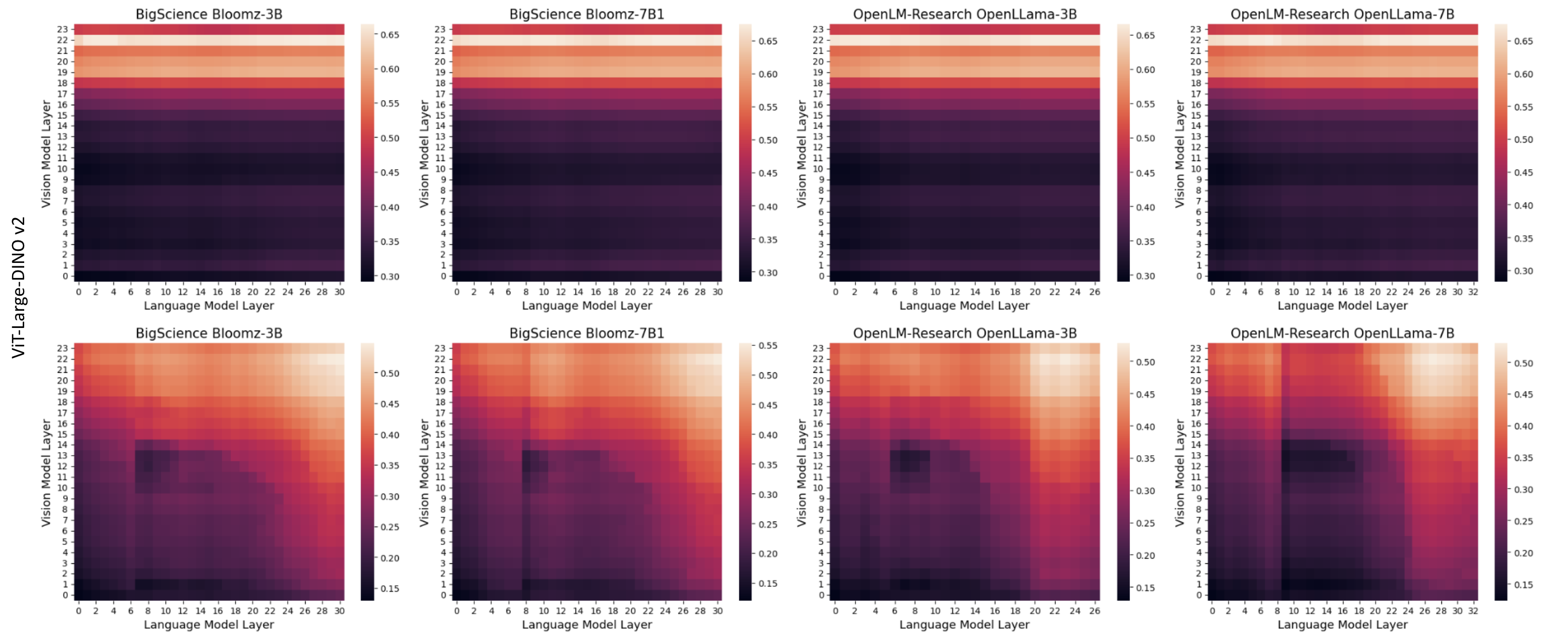
Figure 1: Layer-wise alignment, measured using linear predictivity score, between an example vision model (ViT-Large-Dinov2) and all LLMs.
Dependency on Semantic Content
The study probes the factors that drive alignment by manipulating input data at both visual and linguistic levels. Findings demonstrate that semantic content—not surface attributes—primarily drives alignment. For images, superficial manipulations (e.g., grayscale conversion) caused negligible alignment changes, whereas semantic disruptions (e.g., object removal) significantly degraded alignment. Similarly, for text, disruptions in semantic structure (e.g., noun-only captions) resulted in diminished alignment.
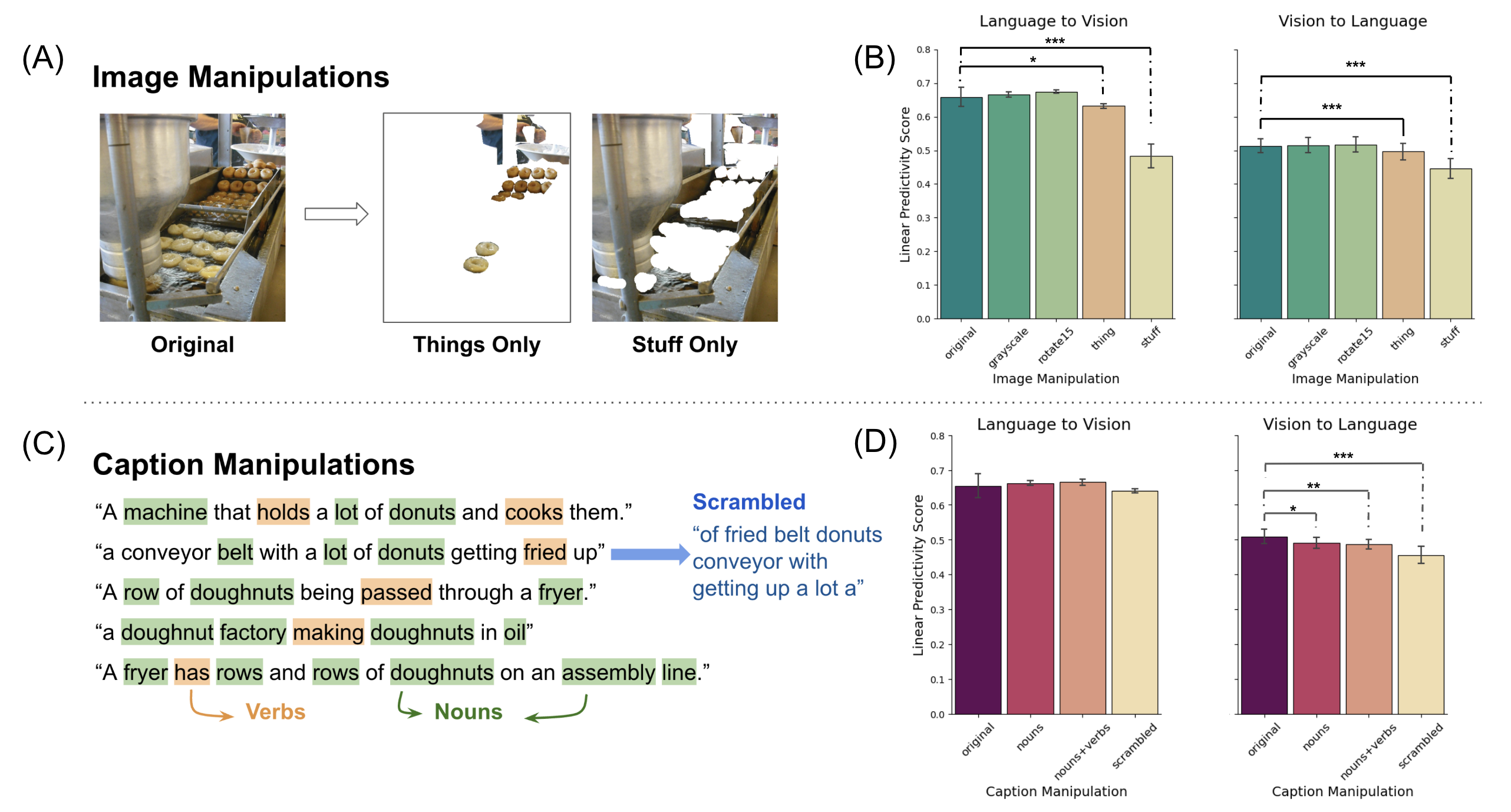
Figure 2: (A) Example 'thing-only' and 'stuff-only' images created by manipulating the original image using masks. (B) Alignment by image manipulations.
Mirroring Human Judgments
In their analyses, the researchers find that the representational alignment mirrors fine-grained human preferences. Evaluation using the 'Pick-a-Pic' task and CLIP Score-based assessments revealed that preferred image-caption pairs exhibit stronger semantic alignment. This suggests that the shared representation aligns well with human semantic judgments, capturing subtle distinctions.
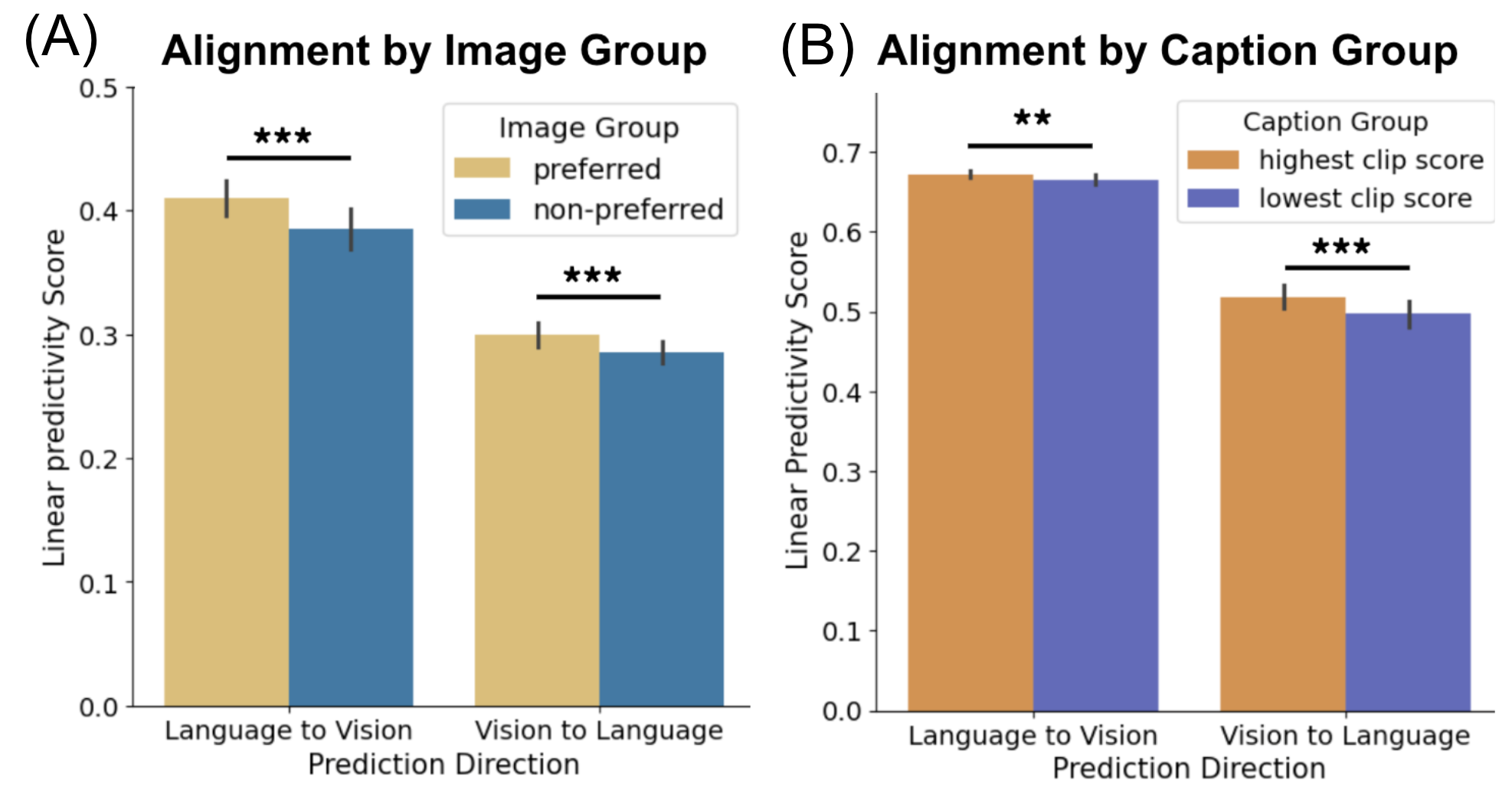
Figure 3: (A) Pick-a-Pic dataset Linear predictivity scores grouped by image variation based on human judgments. (B) MS-COCO dataset Linear predictivity scores grouped by caption variation.
Enhancing Alignment Through Aggregation
Interestingly, the approach of averaging embeddings across multiple examples (captions or images) pertaining to the same concept amplifies alignment. This counters intuitive expectations of blurring and demonstrates that aggregation distills a stable semantic core. Such findings challenge existing beliefs in representation specificity and propose aggregation as a robust technique for reinforcing alignment.
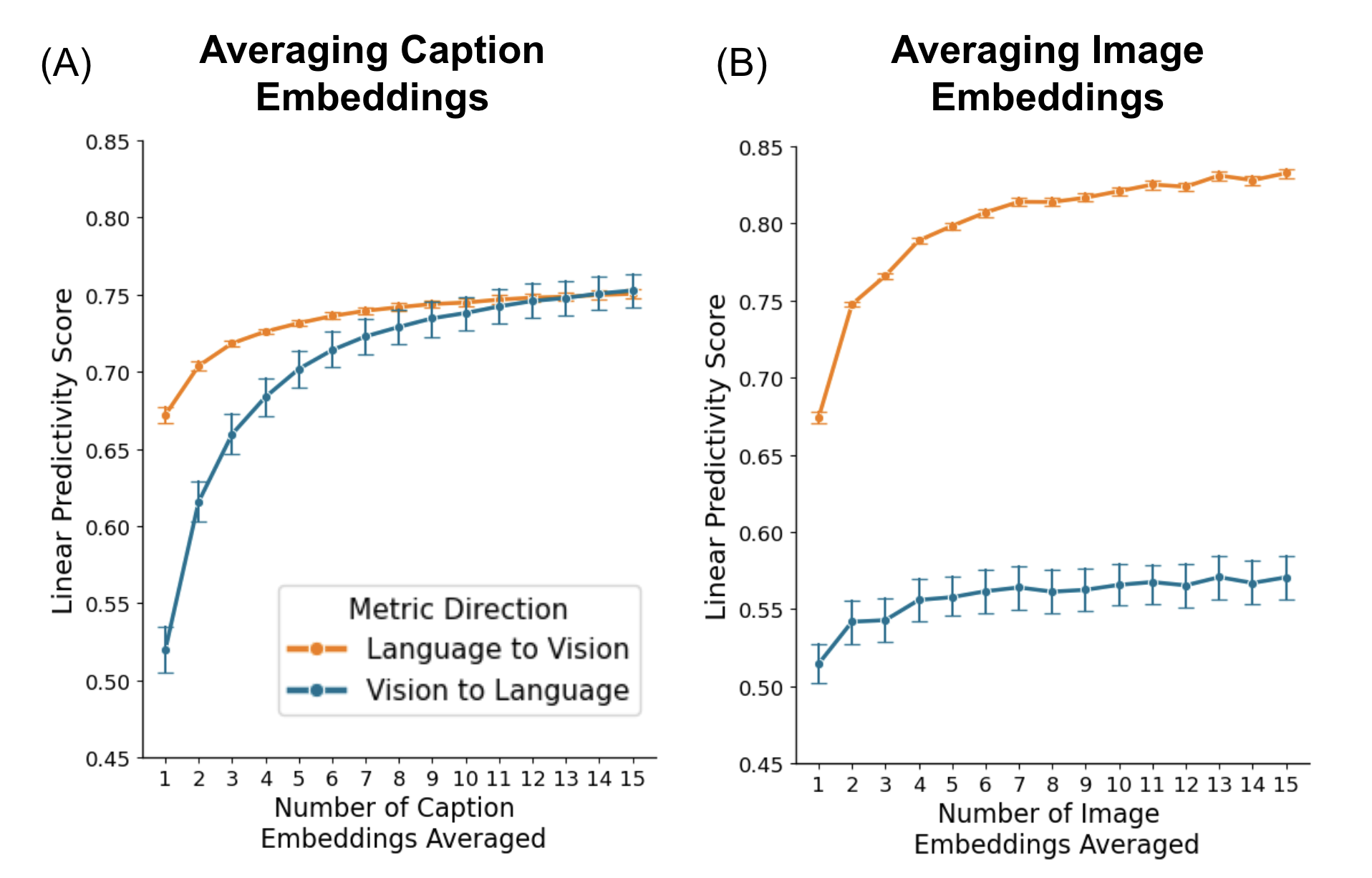
Figure 4: Effect of aggregation on alignment. Cross-modal aggregation enhances language–vision and vision–language predictivity.
Broader Implications and Future Directions
The paper enriches cognitive and computational models by bridging insights between how artificial and biological systems may converge on amodal representations of semantics. The findings open inquiries into how abstract versus concrete concepts influence alignment or how different visual mediums (e.g., illustrations vs. photographs) alter semantic convergence. The study also prompts an exploration into the geometric properties of averaged embeddings as possible denoising mechanisms. Observing alignment progress across training stages may shed light on developmental trajectories in semantic learning.
Conclusion
This detailed study affirms that a universally shared semantic space is emergent between sophisticated, unimodal vision and language networks. Importantly, this shared space aligns closely with human cognitive judgments and highlights novel areas such as exemplar aggregation to enhance multi-modal semantic coherence. The findings propose multiple future research avenues into the intrinsic properties of cross-modal shared representations, their evolution, and their implications in deriving human-like semantic inference.
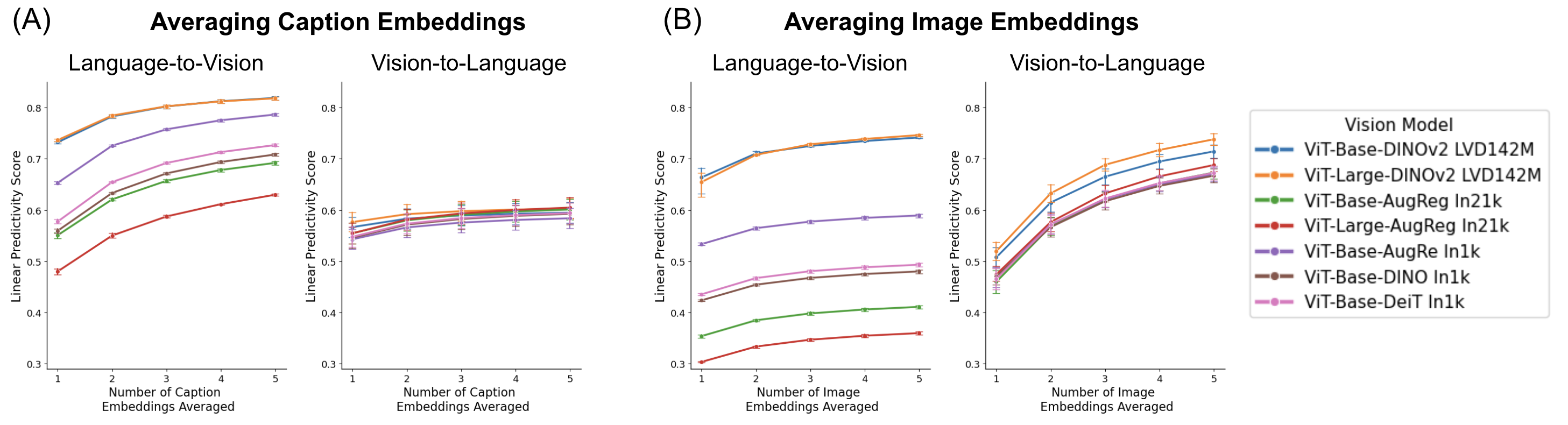
Figure 5: Comparing the alignment of different vision models with LLMs after averaging caption embeddings and image embeddings.