VisualSphinx: Large-Scale Synthetic Vision Logic Puzzles for RL
Abstract: Vision LLMs (VLMs) are expected to perform effective multimodal reasoning and make logically coherent decisions, which is critical to tasks such as diagram understanding and spatial problem solving. However, current VLM reasoning lacks large-scale and well-structured training datasets. To bridge this gap, we propose VisualSphinx, a first-of-its-kind large-scale synthetic visual logical reasoning training data. To tackle the challenge of image synthesis with grounding answers, we propose a rule-to-image synthesis pipeline, which extracts and expands puzzle rules from seed questions and generates the code of grounding synthesis image synthesis for puzzle sample assembly. Experiments demonstrate that VLM trained using GRPO on VisualSphinx benefit from logical coherence and readability of our dataset and exhibit improved performance on logical reasoning tasks. The enhanced reasoning capabilities developed from VisualSphinx also benefit other reasoning tasks such as algebraic reasoning, arithmetic reasoning and geometry reasoning.
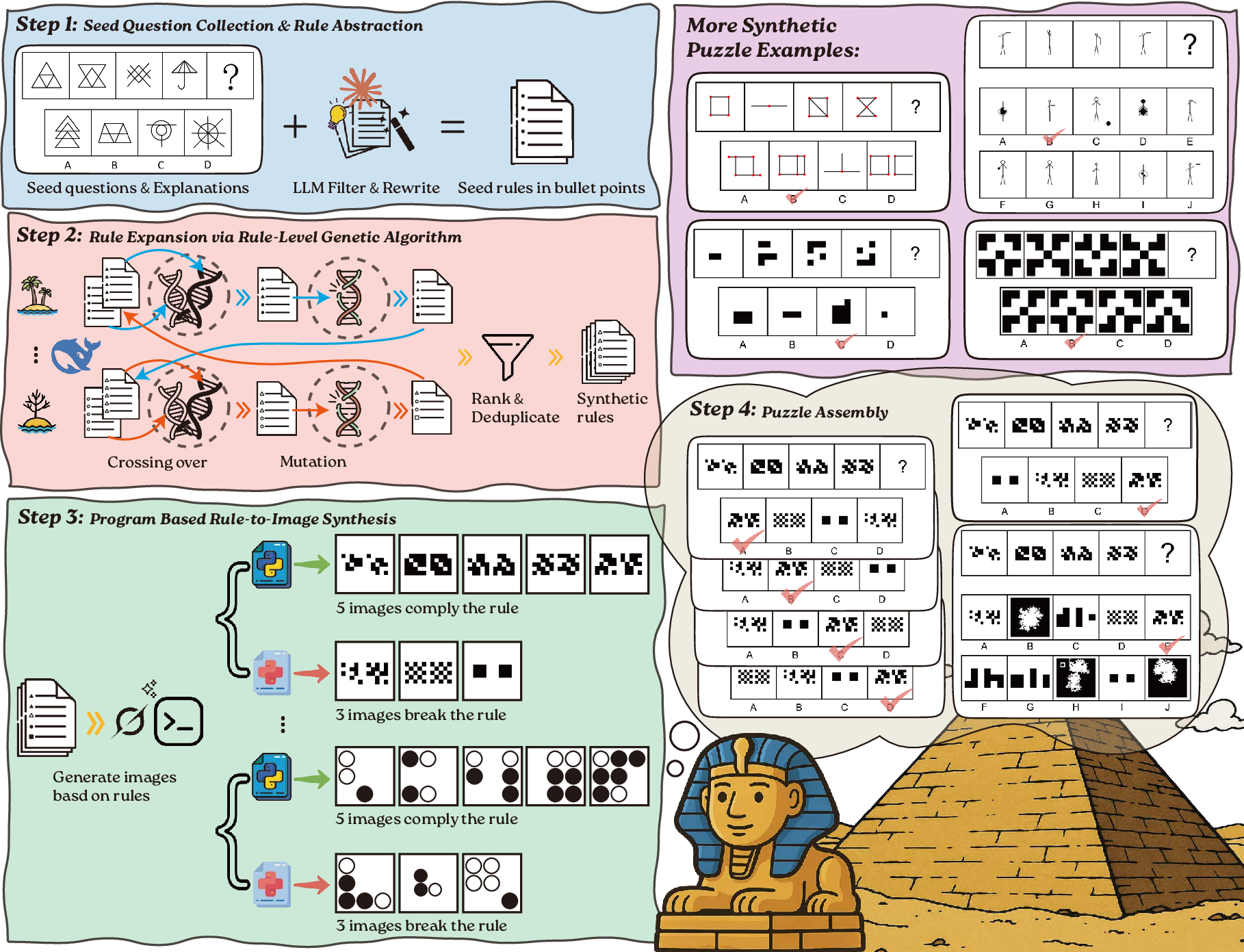
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a focused list of concrete gaps the paper leaves unresolved, framed to be actionable for follow-up research.
- Formal rule satisfaction checking is absent: there is no symbolic or programmatic verification that “correct” images strictly satisfy the rule and that distractors strictly violate it; develop constraint checkers to quantify rule adherence/violation and estimate mislabel rates.
- Ambiguity and unsolvability are not diagnosed: 14K puzzles with 0% pass rate may reflect ambiguity or construction errors; build an adjudication pipeline (LLM+human) to label ambiguous/ill-posed items and create a “known-ambiguous” subset.
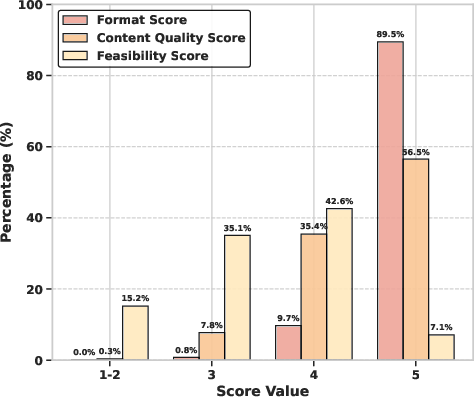
- LLM-based quality scoring reliability is unmeasured: readability and logical coherence are annotated by LLMs without human agreement or cross-model consistency checks; quantify inter-rater reliability (human vs multiple LLMs), calibration, and bias.
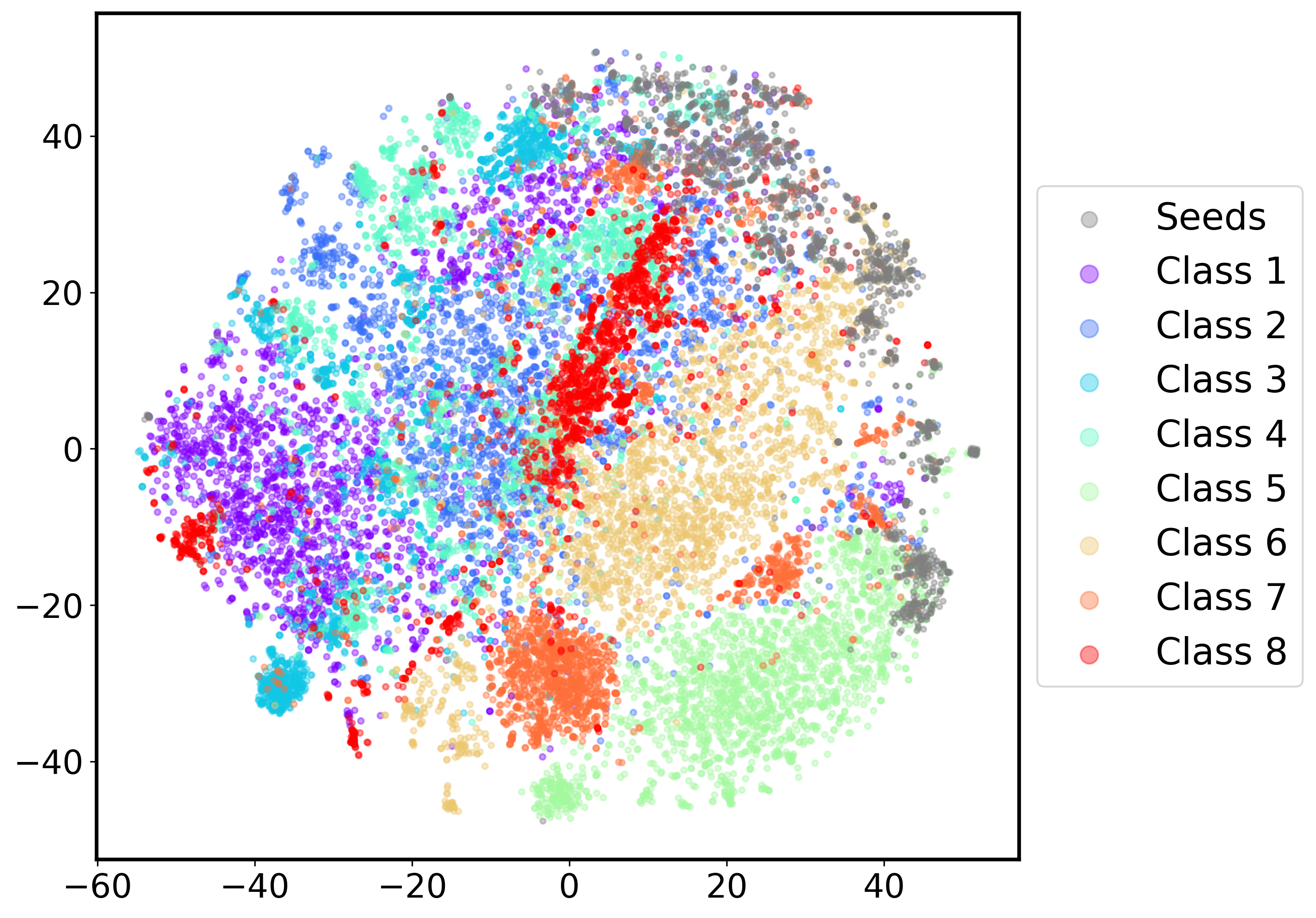
- Deduplication is intra-group only: no evidence of cross-group near-duplicate detection; implement global perceptual/embedding-based dedup across groups and report redundancy rates and their effect on training.
- Distractor quality is under-specified: “incorrect_script.py” may generate trivial or easily separable distractors; design adversarial/counterfactual distractor generation and measure distractor discriminability and confound rates.
- Difficulty calibration is circular: difficulty bins rely on pass rates from a model trained on seed data; introduce human difficulty ratings, item response theory (IRT), and cross-model difficulty curves to de-bias calibration.
- Rule taxonomy coverage is unclear: the 8 classes are LLM-derived with no formal mapping to reasoning primitives (e.g., symmetry, numerosity, topology); define a principled taxonomy, estimate coverage, and identify missing primitives.
- Generalization to real-world diagrams and natural scenes is untested: puzzles use synthetic grids/shapes; assess transfer to textbook diagrams, charts, UI mockups, and natural images with occlusion, noise, and clutter.
- Rendering robustness is limited: only three styles and minimal perturbations; systematically evaluate sensitivity to color palettes, fonts, line thickness, occlusions, compression artifacts, and colorblind-safe palettes.
- Explanations/rationales are missing: puzzles lack step-by-step solutions; create explanation-augmented data and test whether process-supervision or rationale rewards improve rule-level reasoning consistency.
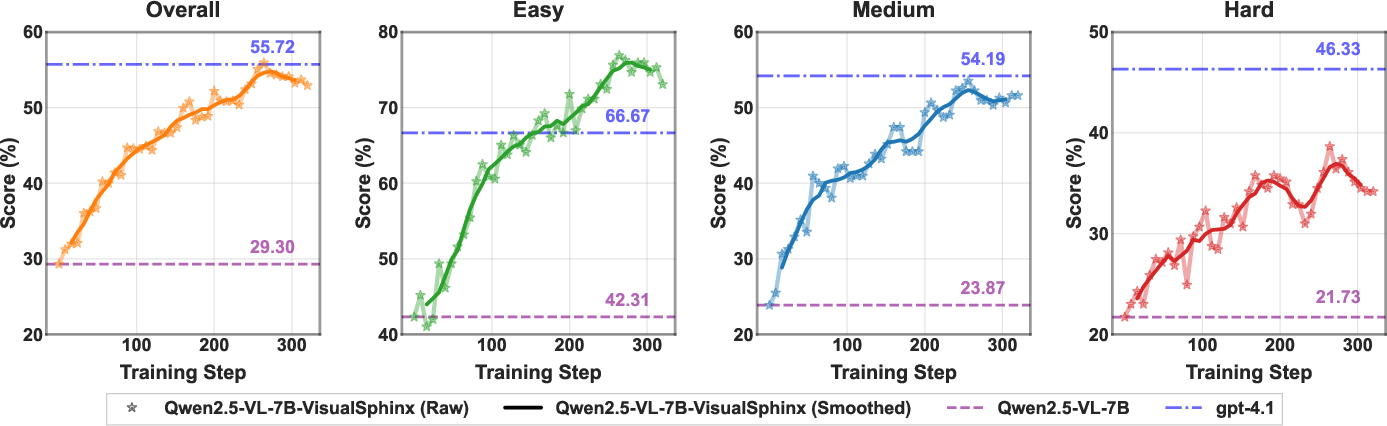
- RL vs SFT ablation is not provided: only GRPO is tested; compare against supervised fine-tuning, DPO/KTO/RLAIF, PPO variants, curriculum RL, and process-reward designs to establish best practices and sample efficiency.
- Reward shaping is coarse: binary rewards may incentivize guessing; explore partial-credit rewards via rule-satisfaction metrics, option-level similarity penalties, and format-aware rewards.
- Scaling laws are uncharacterized: no curves for dataset size, option count (4 vs 10), style multiplicity, or rule diversity vs performance; fit scaling laws and identify saturation/regime shifts.
- Alternative assembly strategy effects are unmeasured: answer-position shuffling and 10-option expansion lack ablations; quantify their impact on learning positional biases and robustness.
- Coverage balance across classes is unknown: the distribution of items per class and per primitive isn’t reported; enforce and evaluate class-balanced sampling and its effect on generalization.
- Error analysis of trained models is missing: there is no taxonomy of failure modes (e.g., symmetry errors, counting errors, distractor lure types); build error typologies to guide targeted data augmentation.
- Cross-benchmark evaluation is limited: beyond MathVista-testmini and a synthetic internal test, no evaluation on canonical visual reasoning sets (e.g., RAVEN/I-RAVEN, SVRT, Bongard-LOGO); benchmark broadly to validate external validity.
- Potential catastrophic forgetting is unmeasured: improvements in logic are reported, but effects on perception/captioning/VQA are unknown; evaluate post-training retention on common multimodal tasks.
- Mechanisms of improvement are underexplored: the paper notes this limitation; perform representational probing, attention/path analyses, causal interventions, and rationale consistency checks to explain why RL on VisualSphinx helps.
- Pipeline reproducibility depends on closed models: multiple steps use proprietary LLMs (Claude, Grok); provide open-source baselines/prompts and quantify quality deltas to ensure replicability.
- Script portability and determinism are not guaranteed: generated Python depends on library versions/seeds; containerize environments, enforce deterministic rendering, and report script failure rates.
- Security/sandboxing of code generation is not discussed: executing LLM-generated code poses risks; document sandboxing, resource caps, and validation to prevent execution exploits.
- Threshold sensitivity is untested: pHash (Hamming < 10), SSIM (< 0.1), and gradient-energy thresholds were heuristic; run sensitivity analyses to understand their effects on dataset quality and retention.
- Cultural/source bias of seed rules is unexamined: seeds from Chinese civil service exams may bias rule types; diversify seed sources and measure cross-cultural generalization and bias.
- Licensing and provenance of seeds are unclear: dataset license is CC-BY-NC, but the legal status of seed images/explanations isn’t discussed; clarify licensing/provenance and release a provenance audit.
- Data contamination safeguards are unverified: while VisualSphinx-Test is synthetic, overlap with public benchmarks/tools/rule templates isn’t rigorously audited; implement fingerprinting and leakage checks.
- Human evaluation scope is opaque: main text defers to appendix; report sample sizes, guidelines, inter-annotator agreement, and error categories to substantiate quality claims.
- Option-count effects on behavior aren’t characterized: 10-option puzzles may change strategies; measure calibration (confidence, entropy), guessing behavior, and learning dynamics across option cardinalities.
- Pass-rate interpretation conflates novelty and quality: 0% pass items may be flawed rather than “hard”; create a validation set that separates “novel-hard” from “ambiguous/defective” with adjudicated labels.
- Transfer beyond math/logic is lightly evidenced: improvements on MathVista are modestly summarized; assess transfer to chart reasoning (ChartQA), diagram QA (DocVQA/InfographicVQA), and instruction-following multimodal tasks.
- Multi-modal text integration is minimal: puzzles include a prompt, but rich language context is not leveraged; add tasks requiring joint text-image reasoning, OCR, and linguistic quantifiers.
- Curriculum learning is unused: rules vary in complexity but no structured curricula exist; design staged curricula (primitive → compositional → distractor-heavy) and compare training dynamics.
- Bias toward spurious visual heuristics is not measured: models may exploit superficial cues; create adversarial splits that control for superficial patterns and quantify reliance on spurious heuristics.
- Difficulty estimation across models is absent: only one annotator model is used to derive pass rates; compute multi-model difficulty and consensus-based hardness to reduce single-model bias.
- Downstream safety and robustness are unassessed: consider adversarial perturbations, distribution shifts, and safety-relevant failures (e.g., overconfident wrong answers) post-RL.
- Quantitative coverage of reasoning compositions is missing: measure frequency of multi-rule compositions, interactions (e.g., counting + symmetry), and their effect on training outcomes.
Collections
Sign up for free to add this paper to one or more collections.