- The paper presents a reinforcement learning with verifiable rewards (RLVR) framework that refines geometric caption synthesis to boost MLLM performance.
- It employs a symbolic, rule-based engine to generate diverse geometric images and fully aligned captions with explicit visual augmentations.
- Experimental results demonstrate up to 3.2% accuracy gains on geometry benchmarks and notable improvements in out-of-domain reasoning.
Generalizable Geometric Image Caption Synthesis: A Technical Analysis
Motivation and Problem Statement
The paper addresses a critical bottleneck in the development of multimodal LLMs (MLLMs): the lack of high-quality, semantically aligned geometric image-caption datasets for cross-modal mathematical reasoning. Existing datasets often suffer from poor alignment between visual and textual modalities, limiting the ability of MLLMs to perform robust geometric reasoning and generalize to out-of-domain tasks. The authors propose a reinforcement learning-based data generation and refinement pipeline, culminating in the GeoReasoning-10K dataset, to bridge this gap.
Geo-Image-Textualization Pipeline
The core contribution is a scalable, rule-based symbolic engine for synthesizing geometric images and captions, augmented by a reinforcement learning with verifiable rewards (RLVR) framework for data refinement.
Symbolic Synthesis and Relation Sampling
The pipeline leverages a library of over 50 geometric relations (e.g., angle bisectors, circumcenters, reflections) to construct geometric diagrams via symbolic composition. Each relation is encoded as a clause with dependency metadata, enabling the generation of a graph-based representation of geometric problems. This approach allows for the systematic creation of images with diverse types and difficulty levels.
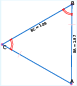
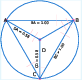
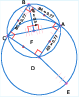
Figure 1: Symbolically synthesized geometric images at varying difficulty, generated from the relation library.
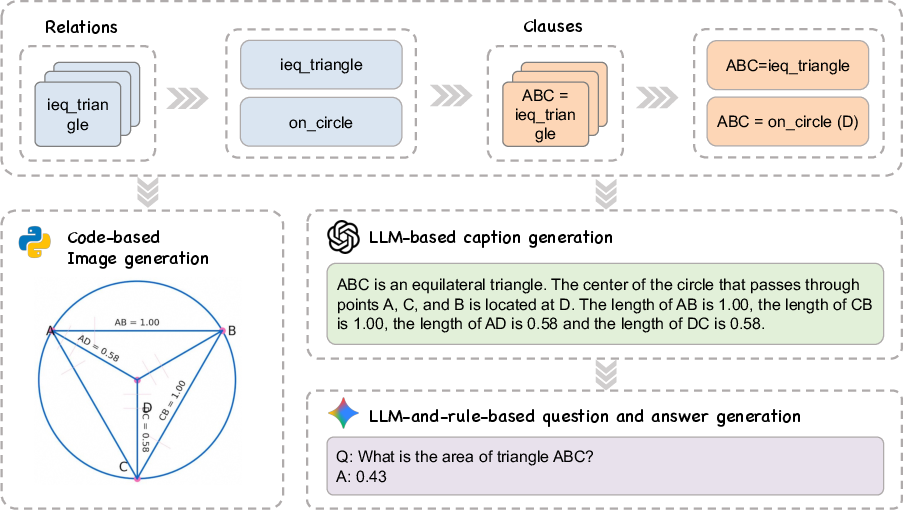
Figure 2: The data synthesis pipeline, illustrating the graph-based construction and rendering of geometric images.
Visual Augmentation and Caption Generation
To ensure full cross-modal alignment, the authors introduce explicit visual augmentations—such as ticks for segment equality, angle annotations, and parallel/perpendicular indicators—mirrored in the natural language captions. The captioning process is rule-based, ensuring that every semantic element in the image is reflected in the text, thus eliminating the common issue of asymmetrical modality alignment.
Question-Answer Pair Generation
A hybrid rule-based and LLM-driven pipeline generates question-answer pairs from captions. The process employs rubric-based prompting with Gemini 2.5 Flash, iteratively refining questions to ensure logical consistency and non-triviality, while avoiding redundancy with caption content.
RLVR: Reinforcement Learning with Verifiable Rewards
The RLVR framework iteratively refines both the dataset and the model. It consists of two phases:
- Cold-Start Supervised Fine-Tuning (SFT): The base model is fine-tuned on the initial dataset to establish basic captioning capabilities.
- RLVR Phase: Alternating between generating candidate captions (rollouts) and model retraining. Captions are scored using a composite reward function that balances reasoning utility (via downstream QA performance) and semantic similarity (ROUGE/BLEU) to ground-truth captions.
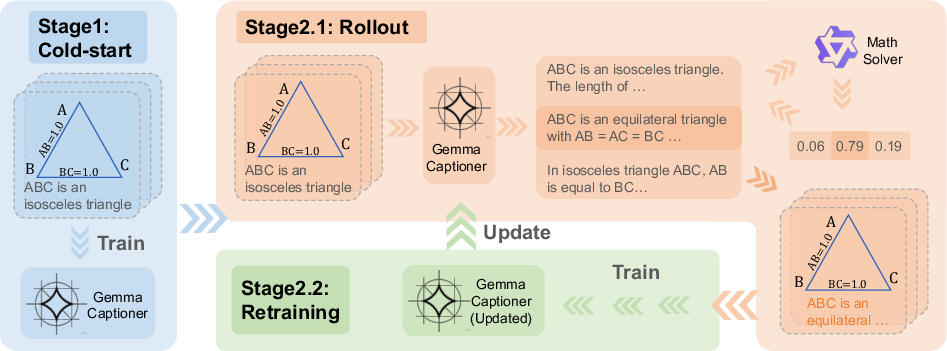
Figure 3: The RLVR training framework, showing the two-stage alternating optimization process.

Figure 4: The composite reward function, integrating reasoning and caption alignment signals.
The reward function is defined as:
R(c,I)=λr⋅Rreasoning(c,q)+(1−λr)⋅Rcaption(c,c⋆)
where Rreasoning is based on answer correctness and format, and Rcaption is a weighted sum of ROUGE and BLEU-4 scores.
Experimental Results
In-Domain Performance
Models fine-tuned on GeoReasoning-10K outperform those trained on other geometric caption datasets (AutoGeo, GeoPeP, GeoGPT4V, Geo170K, MathVision, GeoQA) on MathVista and MathVerse benchmarks. Notably, the improvements are most pronounced in geometry, algebra, and statistics subtasks, with accuracy gains of up to 3.2% over the best baselines at the 10K data scale.
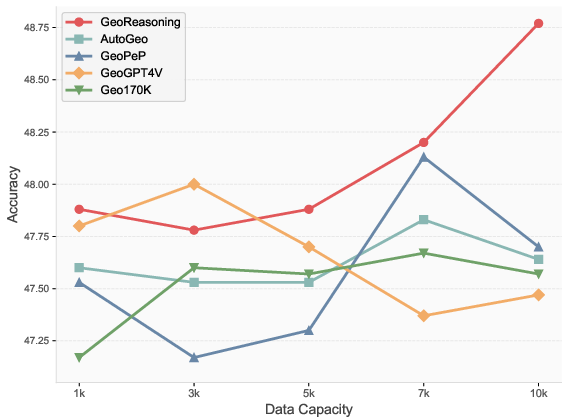
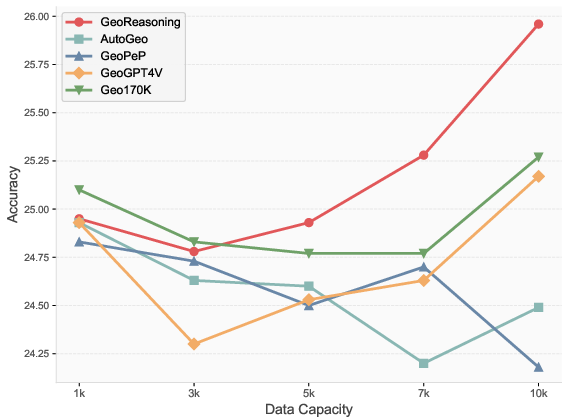
Figure 5: MathVista benchmark results, demonstrating superior scaling and accuracy of GeoReasoning-trained models.
Out-of-Domain Generalization
GeoReasoning-10K also yields non-trivial improvements (2.8–4.8%) on non-geometric tasks in MathVista, MathVerse, and MMMU, including art, engineering, and science domains. This suggests that the RLVR-driven focus on key visual reasoning elements transfers to broader multimodal reasoning tasks.
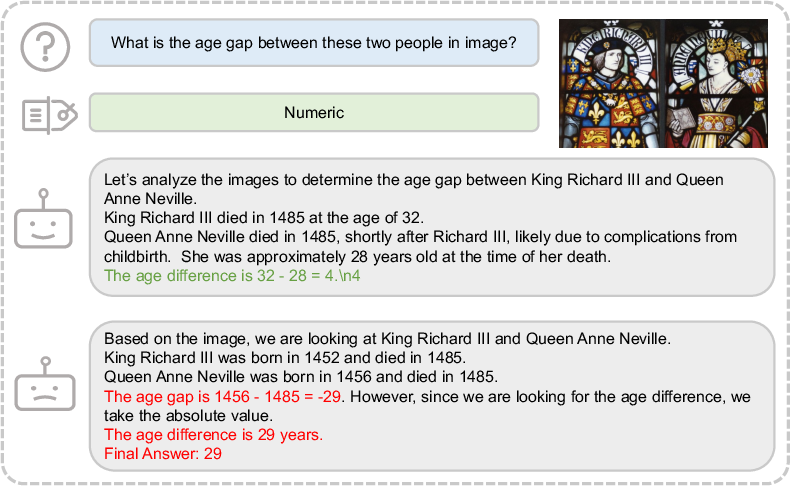
Figure 6: Examples of generalization, where models trained on synthetic geometric data generalize to algebraic and non-geometric cases.
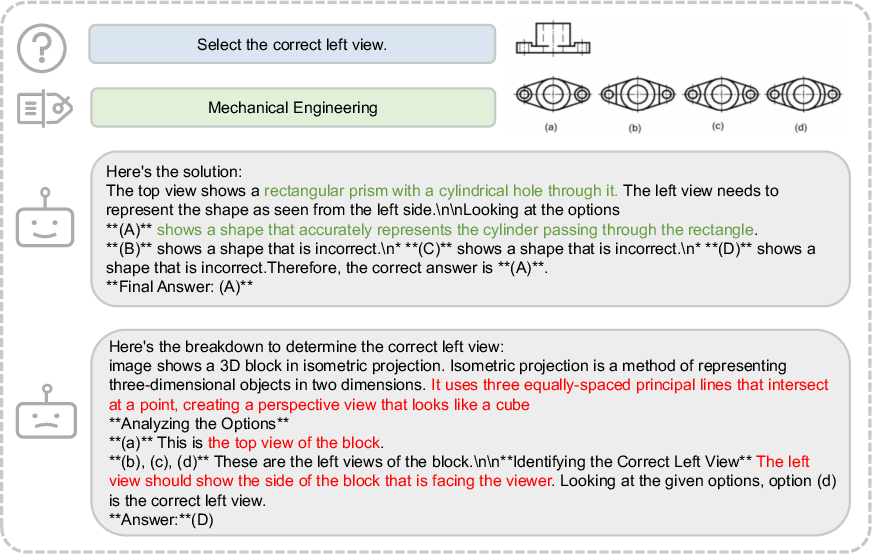
Figure 7: An engineering case, illustrating improved spatial reasoning and detailed analysis after GeoReasoning training.
Qualitative Case Studies
The paper provides qualitative evidence of improved reasoning in geometric, arithmetic, numeric, physics, and economics domains.

Figure 8: A geometric case.

Figure 9: An arithmetic case.

Figure 10: A numeric case.

Figure 11: A physics case.

Figure 12: An economics case.
Ablation Studies
Ablation experiments confirm that both the cold-start SFT and RLVR phases contribute to performance gains, with the combination yielding the highest accuracy. The reward function's reasoning component is particularly critical for visual reasoning tasks, while the method is robust to the choice of reward weights.
Implementation and Resource Considerations
- Data Generation: The symbolic engine and rule-based captioning are computationally efficient and scalable, enabling the synthesis of large, diverse datasets.
- RLVR Training: The alternating optimization requires multiple epochs of rollout and retraining, with each iteration involving candidate generation and reward computation. The process is parallelizable and compatible with distributed training frameworks (e.g., DeepSpeed ZeRO-3).
- Model Architecture: The pipeline is demonstrated on Gemma3-4B, but is agnostic to the underlying MLLM, making it broadly applicable.
- Evaluation: Official codebases and GPT-4o-mini API are used for benchmark evaluation, ensuring reproducibility.
Implications and Future Directions
The results demonstrate that high-quality, semantically aligned geometric image-caption data, refined via RLVR, can substantially enhance both in-domain and out-of-domain reasoning in MLLMs. The symbolic synthesis approach enables infinite data diversity and fine-grained control over problem difficulty, while the RLVR framework ensures that captions are optimized for downstream reasoning utility.
Key implications:
- Symbolic, rule-based data generation combined with RL-based refinement is a viable strategy for constructing high-impact multimodal datasets.
- Improvements in geometric reasoning transfer to broader domains, suggesting that geometric abstraction is a strong prior for general reasoning.
- The approach is extensible to other structured domains (e.g., chemistry, physics diagrams) where visual-textual alignment is critical.
Future work may explore:
- Scaling the dataset to larger sizes and more complex geometric constructs.
- Adapting the RLVR framework to other modalities and domains.
- Investigating the impact of different reward function designs and LLMs for reward modeling.
- Integrating human-in-the-loop feedback for further refinement.
Conclusion
The paper presents a principled, scalable framework for generating and refining geometric image-caption datasets, addressing a key limitation in current MLLM training. The combination of symbolic synthesis and RLVR yields datasets that are both semantically aligned and optimized for reasoning, resulting in measurable improvements across a range of mathematical and non-mathematical benchmarks. This work establishes a strong foundation for future research in cross-modal reasoning and dataset construction for multimodal AI systems.