Pangu Embedded: An Efficient Dual-system LLM Reasoner with Metacognition
Published 28 May 2025 in cs.CL | (2505.22375v2)
Abstract: This work presents Pangu Embedded, an efficient LLM reasoner developed on Ascend Neural Processing Units (NPUs), featuring flexible fast and slow thinking capabilities. Pangu Embedded addresses the significant computational costs and inference latency challenges prevalent in existing reasoning-optimized LLMs. We propose a two-stage training framework for its construction. In Stage 1, the model is finetuned via an iterative distillation process, incorporating inter-iteration model merging to effectively aggregate complementary knowledge. This is followed by reinforcement learning on Ascend clusters, optimized by a latency-tolerant scheduler that combines stale synchronous parallelism with prioritized data queues. The RL process is guided by a Multi-source Adaptive Reward System (MARS), which generates dynamic, task-specific reward signals using deterministic metrics and lightweight LLM evaluators for mathematics, coding, and general problem-solving tasks. Stage 2 introduces a dual-system framework, endowing Pangu Embedded with a "fast" mode for routine queries and a deeper "slow" mode for complex inference. This framework offers both manual mode switching for user control and an automatic, complexity-aware mode selection mechanism that dynamically allocates computational resources to balance latency and reasoning depth. Experimental results on benchmarks including AIME 2024, GPQA, and LiveCodeBench demonstrate that Pangu Embedded with 7B parameters, outperforms similar-size models like Qwen3-8B and GLM4-9B. It delivers rapid responses and state-of-the-art reasoning quality within a single, unified model architecture, highlighting a promising direction for developing powerful yet practically deployable LLM reasoners.
The paper introduces an efficient LLM reasoner that integrates a two-stage training framework using iterative distillation and reinforcement learning to tackle computational cost and latency.
It details a dual-system architecture combining fast intuitive (System 1) and slow deliberative (System 2) thinking modes, allowing both manual and adaptive switching.
The study demonstrates significant performance gains on multiple benchmarks and domain-specific tasks, achieved through model-aware training, latency-tolerant scheduling, and parameter merging strategies.
Pangu Embedded: An Efficient Dual-System LLM Reasoner with Metacognition
This paper introduces , an efficient LLM reasoner designed for deployment on Ascend NPUs, emphasizing a dual-system cognitive architecture for enhanced reasoning and computational efficiency. The paper addresses the challenges of computational cost and latency in current LLM reasoners by proposing a @@@@1@@@@ that incorporates iterative distillation, reinforcement learning, and a fast/slow thinking mechanism.
Basic Reasoner Construction via Iterative Distillation and RL
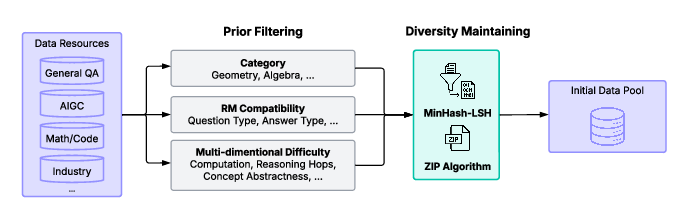
The first stage of training focuses on building a robust base reasoner. This involves three key steps: data preparation, model-aware iterative distillation, and scaled reinforcement learning. The post-training data construction involves prior filtering using an LLM to annotate data with subcategory, question type, answer verifiability, and difficulty metrics. This annotation is followed by diversity maintenance using n-gram-based MinHash-LSH and the ZIP algorithm to reduce redundancy. The ZIP algorithm measures instruction diversity via data compression ratio calculated using off-the-shelf compression tools. The curated dataset is then used for model-aware iterative distillation.
Figure 1: An illustration of the construction of the initial data pool.
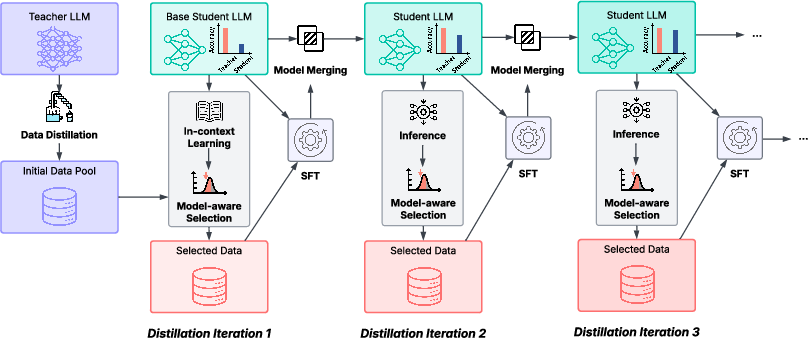
The model-aware iterative distillation pipeline refines the student model's capabilities by dynamically aligning training data complexity with the model's evolving proficiency. A model-aware data complexity metric guides this iterative process by dynamically aligning training data with the student model's evolving capabilities. The complexity score for each data sample is evaluated based on the student model's performance on that sample from the previous iteration, with the score defined as:
C(x,y;Gt−1)=1−k1i=1∑kI(Eq(yi,y))
where Eq(y1,y2) examines whether the final answers in y1 and y2 are equal, and I(⋅) is the indicator function.
Figure 2: The overall framework of the model-aware iterative distillation pipeline in . In each iteration, data samples are selectively filtered based on a model-aware complexity metric, which is evaluated using the student model from the previous iteration.
The iterative training process involves selecting training samples with a probability P(C) related to their complexity score:
P(C)=2πσ21exp(−2σ2(C−μ)2)
where C is the complexity score C(x,y;Gt−1), and μ and σ are predefined hyperparameters. Inter-iteration model merging is employed to mitigate catastrophic forgetting and consolidate knowledge across iterations. The parameters of the merged model for iteration t, Θmergedt, are computed as:
where λt is an inter-iteration merging weight and δˉt is the average parametric difference of the Nt checkpoints relative to the reference model. A Repetition Self-repair strategy consisting of local n-gram repetition detection and prompt-controlled repetition suppression is introduced to improve practical usability, especially in generating long and coherent texts.
Reinforcement Learning with MARS and Ascend NPU Optimization
Following supervised fine-tuning, the basic reasoner's capabilities are refined using large-scale RL. The RL process is formulated as an MDP, with the objective of finding the optimal policy πθ∗ that maximizes the expected reward:
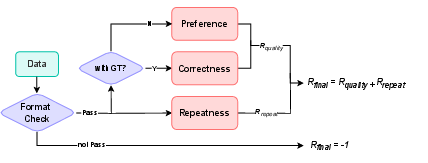
The Group Relative Policy Optimization (GRPO) algorithm is employed for policy optimization. A Multi-source Adaptive Reward System (MARS) dynamically routes prompts and responses to appropriate evaluators based on predefined task labels, generating comprehensive reward signals. MARS incorporates correctness reward, preference reward, format validator, and a repetition penalty.
Figure 3: An illustration of the Multi-source Adaptive Reward System (MARS).
A curriculum strategy is used to interleave queries of varying complexity levels, dynamically adapting to the policy's evolving capabilities. The complexity score C(x,y∗;πθ) is defined using the pass rate among k responses:
C(x,y∗;πθ)=1−k1i=1∑kI(Verify(yi,y∗))
where Verify(yi,y∗) checks if response yi is considered successful or high-quality with respect to the task defined by x and reference y∗. A Supervised Fine-Tuning (SFT) warm-up phase is implemented as a cold start procedure.
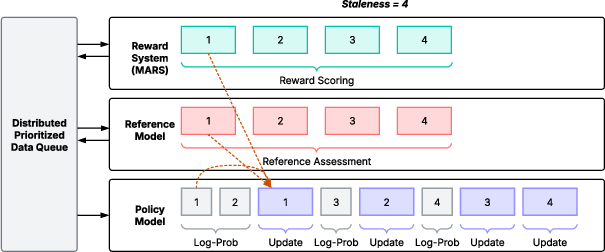
Efficient distributed training for large-scale RL is performed on Ascend NPUs. A latency-tolerant scheduling framework on Ascend NPUs integrates a Stale Synchronous Parallel (SSP) scheduler with distributed prioritized data queues. The SSP scheduler organizes the RL pipeline into reference assessment, reward scoring, log-probability extraction, and gradient update stages. Host-device adaptive weight reshuffling enables seamless sharing of model parameters between the training and inference pipelines. vLLM inference optimization for Ascend NPUs mitigates straggler delays caused by heterogeneous decoding lengths.
Figure 4: The latency-tolerant scheduling framework on Ascend NPUs. Log-Prob and Update denote log-probability extraction and parameter update, respectively.
Dual-System Fast and Slow Thinking Architecture
In Stage 2, a dual-system framework is introduced, endowing with both System 1 (fast, intuitive) and System 2 (slow, deliberative) cognitive processing capabilities. The framework supports both user-controlled manual switching and an adaptive mode selection. The manual switching capability allows users to explicitly dictate the desired cognitive mode. Cultivating this dual-mode proficiency is achieved through a dedicated fine-tuning process using a curated dataset comprising exemplars of both fast thinking (System 1) and slow thinking (System 2) responses, each paired with distinct mode-specifying prompts.
Figure 5: Comparison of three thinking settings: (a) Vanilla reasoner, (b) Manual switching, (c) Adaptive switching.
For adaptive mode selection, a specialized fine-tuning dataset, Dfusion, is constructed, comprising samples indicative of both fast thinking and slow thinking. The response format for the fast-thinking data subset is designed for conciseness, while the slow thinking subset follows a general reasoning-intensive content structure.
Figure 6: An illustrative example of fast and slow adaptive thinking switch under user command with natural language context.
Experimental Results and Ablation Studies
The model's performance is evaluated on benchmarks, including AIME 2024, GPQA, LiveCodeBench, MMLU-Pro, and Arena Hard. The decoding strategy applies top-nσ sampling, followed by top-p sampling. The unified model exhibits strong performance across multiple benchmarks when operating in its distinct thinking modes. When employing its "Thinking (system2)" mode, demonstrates leading capabilities on several reasoning-intensive benchmarks. Ablation studies validate the manual switching mechanism. A specialized fusion training strategy, incorporating replay of mastered slow thinking data while introducing fast thinking exemplars, is shown to be critical. Ablation studies on adaptive fast and slow thinking demonstrate that the (Adaptive) model demonstrates a significant reduction in average token usage. The tendency to engage slow thinking mode increases monotonically with the problem's difficulty level.
Domain-Specific Adaptation and Conclusion
The paper extends the model to the legal domain as a proof-of-concept for domain-specific adaptation. LawBench is used to assess the model's performance in the legal domain. After undergoing domain-specific training with the curated legal data, exhibited a significant gain in legal knowledge and reasoning capabilities. The authors conclude that the introduced , an efficient LLM reasoner developed on Ascend NPUs, achieves state-of-the-art reasoning accuracy among similarly-sized models through a two-stage training framework and a novel dual-system fast-slow thinking capability.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.