- The paper proposes a novel pipeline that leverages metadata enrichment and hybrid retrieval to significantly improve zero-shot precision for specialized domain QA.
- It integrates dense and sparse vector methods with cost-effective metadata extraction to enhance retrieval accuracy by up to 82.1% on PubMedQA.
- The approach achieves a leading RAG accuracy of 77.9%, providing scalable and cost-effective domain adaptation without extensive model fine-tuning.
MetaGen Blended RAG: Unlocking Zero-Shot Precision for Specialized Domain Question-Answering
Introduction
"MetaGen Blended RAG" presents an innovative approach addressing the challenges inherent in specialized domain QA systems, particularly those relying on retrieval-augmented generation. Traditional RAG systems, although effective in knowledge-intensive tasks, falter with domain-specific datasets due to semantic variability and metadata deficiency. This paper proposes a novel pipeline that leverages metadata generation and enriched semantically-informed indexing to fortify RAG systems, especially in zero-shot scenarios. By employing dense and sparse vector representations in tandem, the proposed method enhances retrieval precision significantly within specialized datasets like the biomedical-focused PubMedQA, SQuAD, and NQ datasets.
Methodology
The core of this methodology lies in the hybrid retrieval approach supported by metadata infusion. The pipeline consists of five stages:
- Ingestion of documents
- Metadata Enrichment (conditional extraction of domain-specific semantics)
- Indexing (dual strategy exploiting BM25 and dense vector representations)
- Hybrid Retrieval (fusion of lexical and semantic search strategies)
- Answer Generation through LLMs
The metadata enrichment phase is particularly critical, incorporating selective processes like KeyBERT and entity recognition within a cost-efficient conditional framework to ensure the retrieval component fetches contextually richer passages.
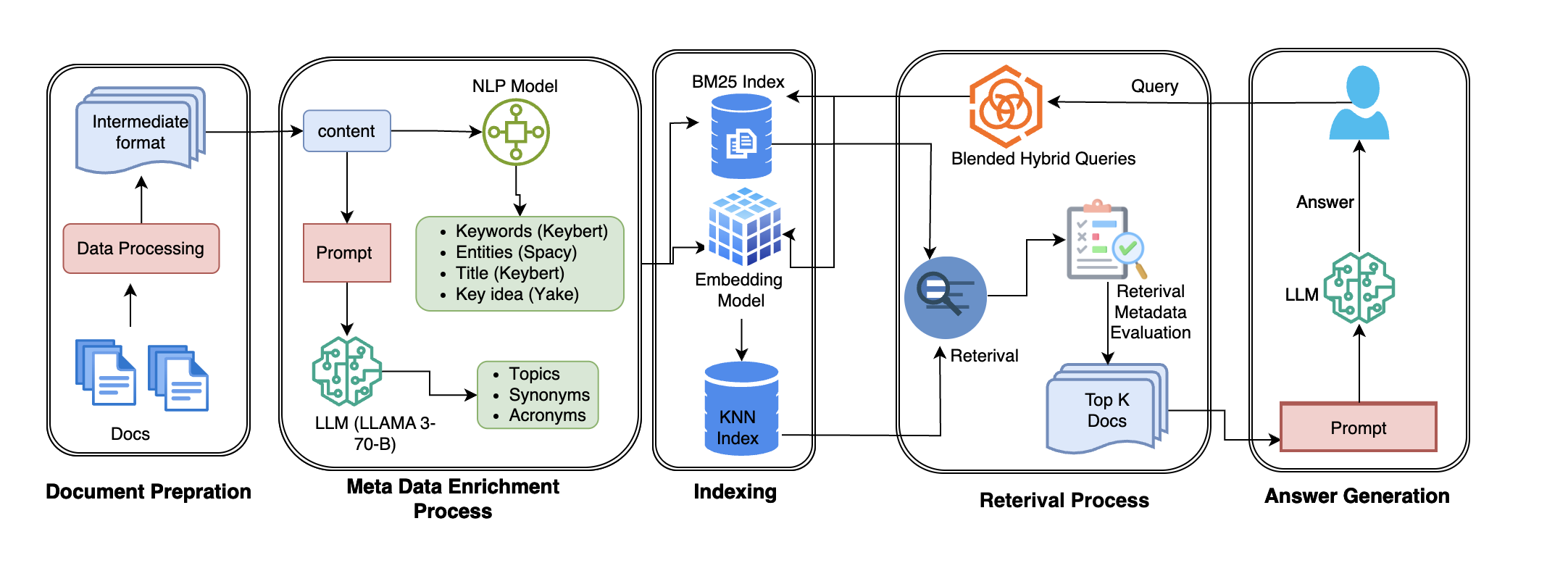
Figure 1: MetaGen Blended Retrieval-Augmented Generation Pipeline
The paper details a robust metadata enrichment strategy through NLP techniques and selective application of LLM-driven semantic extraction, all tuned for domain efficiency and retrieval accuracy.
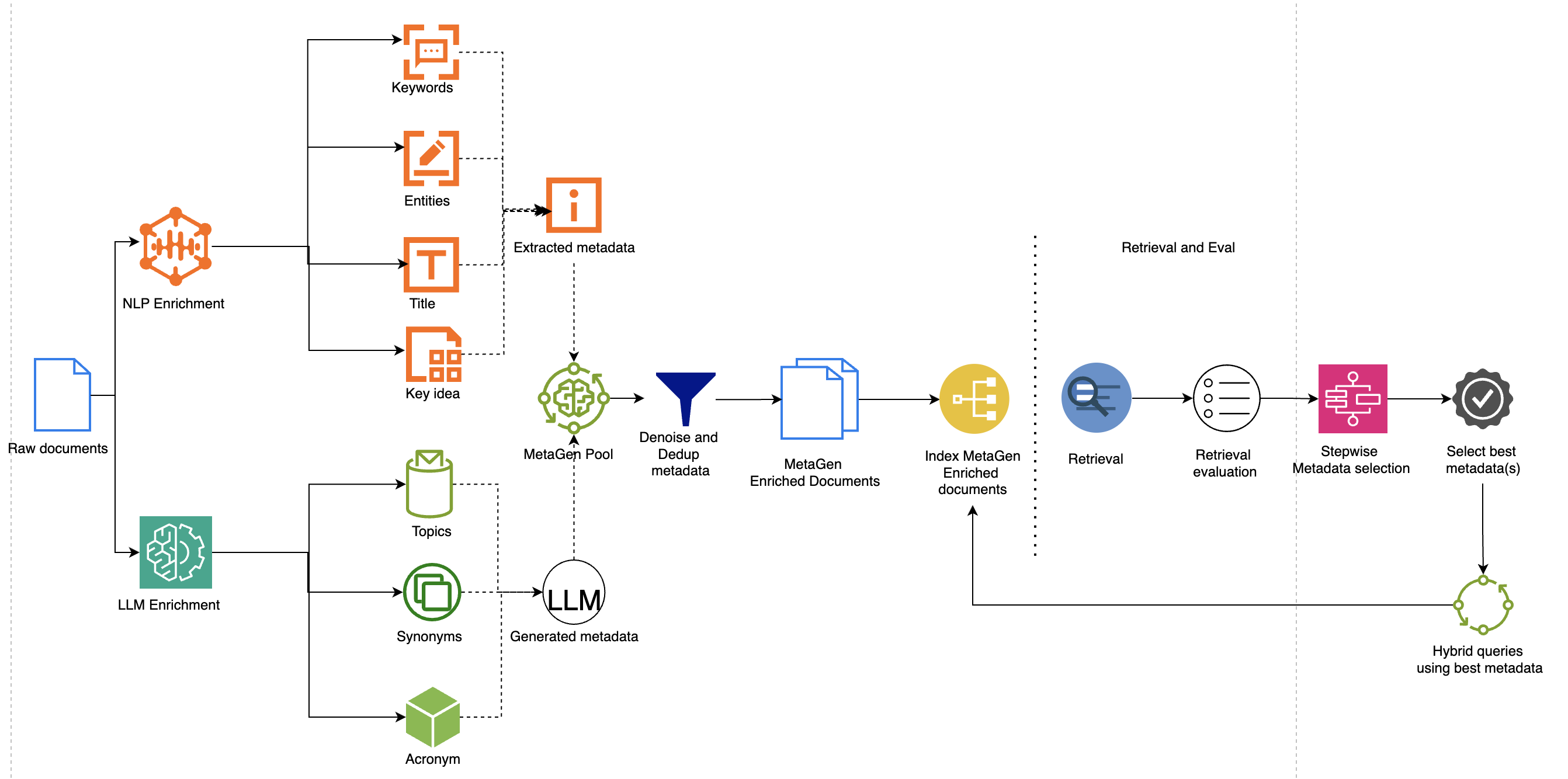
Figure 2: MetaGen Enrichment Workflow
The experiments demonstrate that this enhanced metadata directly amplifies retrieval effectiveness. On PubMedQA, the methodology achieved a striking improvement to 82.1% retrieval accuracy over a baseline of 74.9%. Similar enhancements were seen across datasets with varied domain complexity.
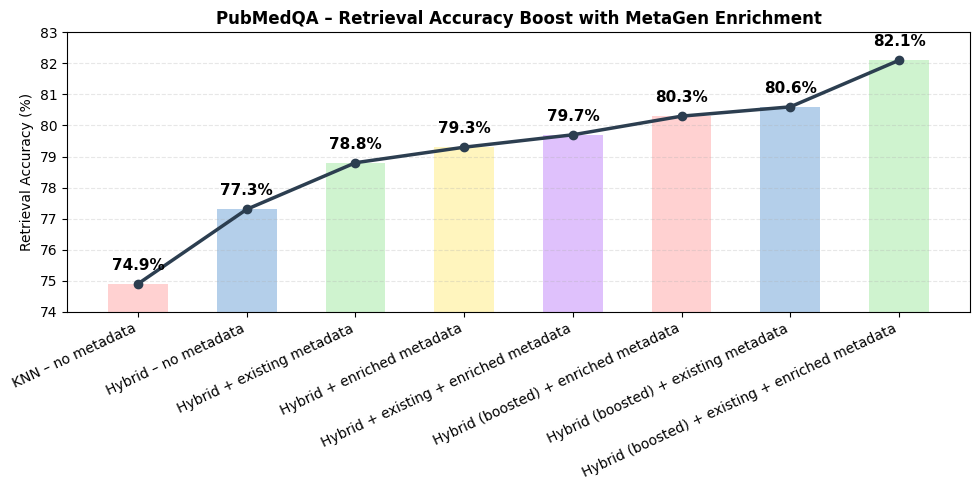
Figure 3: Impact of Metadata Enrichment on Retrieval Accuracy (PubMedQA dataset)
Notably, hybrid indexing and the enriched corpus were instrumental in elevating retrieval performance significantly, providing a scalable solution for enterprise applications.
RAG Evaluation and Comparative Analysis
The downstream impact on RAG accuracy is profound. Without any extensive model fine-tuning, the improved retrieval-stage precision, thanks to metadata augmentation, led to a leading RAG accuracy of 77.9% on PubMedQA.
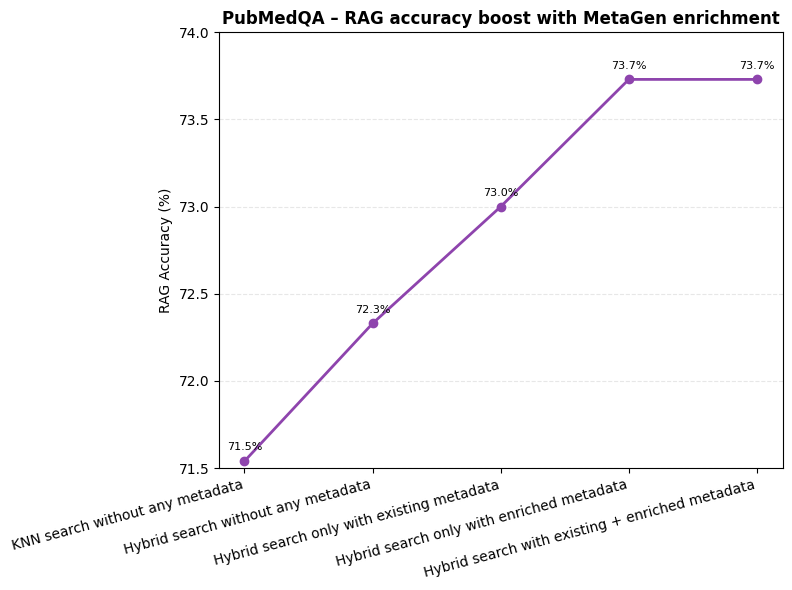
Figure 4: Impact of MetaGen Metadata Enrichment on RAG Accuracy (PubMedQA Dataset)
Evaluations across datasets further emphasize generalizability, with similar patterns replicated in SQuAD and NQ datasets.
Conclusion and Future Prospects
The MetaGen Blended RAG approach substantiates the critical role of strategically enriched metadata and hybrid retrieval frameworks in advancing zero-shot precision in domain-specific RAG tasks. While introducing sophisticated metadata-driven retrieval, the method retains scalability and generalization capabilities across diverse datasets, proposing a cost-effective alternative to fine-tuning-intensive models.
Future work might explore the integration of automated metadata detection systems to augment this approach, alongside potential enhancements combining metadata enrichment with model fine-tuning for even greater domain adaptation. Overall, this research sets a precedent for leveraging metadata in RAG systems, ensuring superior context alignment without the significant overhead associated with domain-specific fine-tuning.