- The paper introduces AccurateRAG, a modular framework for high-performance retrieval-augmented QA that integrates advanced preprocessing, semantic retrieval, and fine-tuning strategies.
- It employs synthetic data generation, semantic context chunking with multi-hop reasoning, and a hybrid search approach to enhance answer accuracy.
- Experimental results on benchmarks like FinanceBench and HotpotQA demonstrate significant performance improvements over existing QA methods.
Overview and Motivation
AccurateRAG introduces a comprehensive, modular framework for constructing retrieval-augmented generation (RAG) systems tailored to high-accuracy question answering (QA) tasks. The framework addresses critical limitations in prior RAG approaches, which often lack end-to-end pipelines, robust preprocessing, and systematic fine-tuning capabilities. AccurateRAG is designed to facilitate the development of QA systems that can leverage proprietary, domain-specific, and up-to-date knowledge sources, overcoming the static knowledge boundaries of pre-trained LLMs.
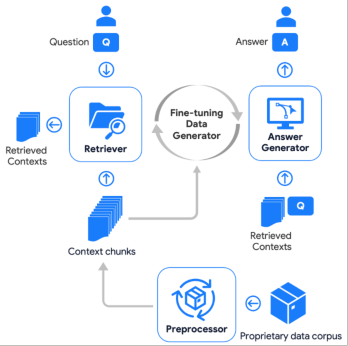
Figure 1: Architecture illustration of AccurateRAG, depicting the modular pipeline from preprocessing to answer generation and evaluation.
Preprocessing and Context Chunking
The Preprocessor component is engineered to handle heterogeneous document formats (PDF, DOCX), converting them into either plain text or Markdown while preserving structural fidelity. The conversion pipeline leverages Unstructured for initial HTML parsing and LlamaParse for high-quality text extraction, followed by a rule-based Markdown conversion. By aligning outputs from both tools, the framework mitigates OCR errors and ensures accurate table and heading representation.

Figure 2: PDF content input, exemplifying the raw document format handled by the Preprocessor.

Figure 3: Markdown-formatted text output, demonstrating preservation of document structure and layout.
Context chunking is performed with a focus on semantic units rather than fixed-length segments, ensuring each chunk encapsulates a coherent piece of information. Overlapping context slices are added to facilitate multi-hop reasoning, enhancing retrieval effectiveness for complex queries.
Synthetic Data Generation for Fine-Tuning
The Fine-tuning Data Generator automates the creation of synthetic QA pairs by prompting a pre-trained LLM to generate diverse questions (simple and complex) from each context chunk. A validation step ensures that only answerable questions are retained, improving the quality of training data for both the Retriever and Answer Generator modules. This synthetic data expansion is critical for domains with limited annotated resources, enabling robust model adaptation.
Retriever: Semantic and Conventional Search Integration
The Retriever module comprises semantic search (fine-tuned BERT-based embeddings), conventional search (BM25), and retrieval evaluation. Semantic search employs contrastive learning with hard and in-batch negatives, optimizing the embedding model to distinguish relevant contexts. BM25 provides a complementary term-frequency-based retrieval mechanism. Retrieval evaluation selects the optimal strategy (semantic, conventional, or hybrid via reciprocal rank fusion) based on validation performance, ensuring maximal context relevance.
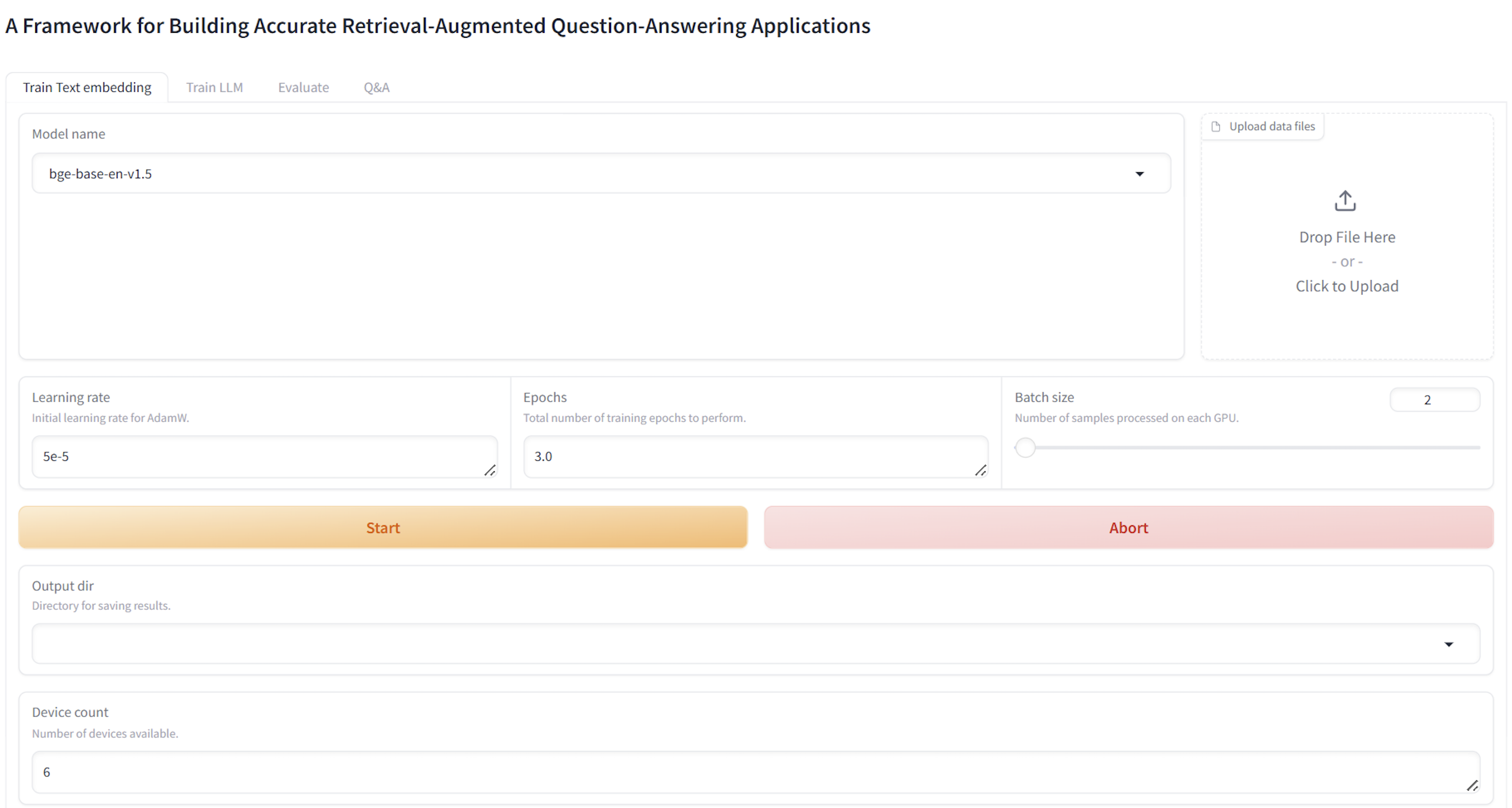
Figure 4: UI for the Preprocessor and text embedding model fine-tuning in the semantic search module, supporting developer workflow.
Answer Generation and Evaluation
The Answer Generator module fine-tunes a pre-trained LLM using ("expanded" context, question, answer) triplets, where expanded context aggregates the original and top-N retrieved chunks. LoRA-based efficient fine-tuning is employed for scalable adaptation. The answer synthesis process concatenates top-N relevant contexts for inference, grounding answers in retrieved evidence.
Answer evaluation leverages a pre-trained LLM (Llama-3.1-8B-Instruct) as a factuality judge, using a strict prompt to assess whether generated answers are factually consistent with ground truth, focusing solely on key fact inclusion and contradiction avoidance.
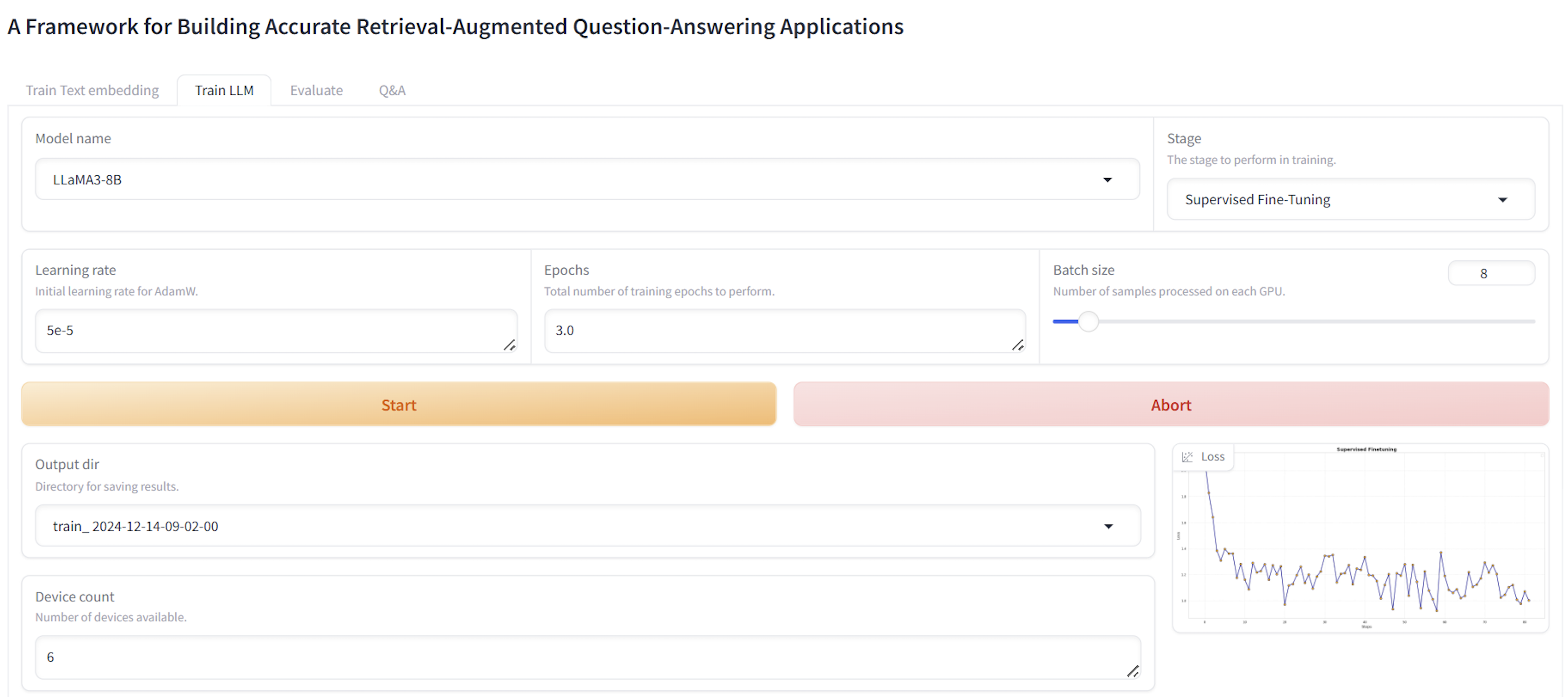
Figure 5: UI for LLM fine-tuning in the answer synthesis module, enabling streamlined model adaptation.
Experimental Results and Ablation Analysis
AccurateRAG demonstrates strong empirical performance across multiple QA benchmarks:
- On FinanceBench, AccurateRAG achieves 42% accuracy, surpassing the OpenAI ada embedding + GPT-4-turbo baseline (19%). Ablations show a 3% drop without embedding fine-tuning and a 4% drop when replacing the Preprocessor with Unstructured, substantiating the impact of both components.
- On HotpotQA, PubMedQA, and APIBench datasets, AccurateRAG consistently outperforms RankRAG and RAFT, achieving new state-of-the-art results. Notably, AccurateRAG with Llama-2-7B outperforms RAFT (with GPT-4 CoT) on 4 out of 5 datasets, and achieves up to 20% higher accuracy on HotpotQA when RAFT is not fine-tuned with CoT.
These results highlight the efficacy of modular fine-tuning, advanced preprocessing, and retrieval strategy selection in boosting QA accuracy.
Implementation and Deployment Considerations
AccurateRAG is designed for local deployment, supporting proprietary data and privacy-sensitive applications. The UI facilitates non-expert usage, with backend orchestration of preprocessing, data generation, model fine-tuning, and evaluation. Fine-tuning is performed on dual A100 40GB GPUs, with LoRA adapters (rank 32) and AdamW optimization. The framework supports integration with Hugging Face models and local checkpoints, enabling flexible experimentation.
Resource requirements are moderate for embedding model fine-tuning (batch size 16, 1e-5 LR) and more substantial for LLM fine-tuning (batch size 64, 5e-5 LR). The modular design allows for scaling to larger corpora and models, with retrieval and answer synthesis components decoupled for parallelization.
Implications and Future Directions
AccurateRAG sets a precedent for modular, extensible RAG system design, emphasizing the importance of high-fidelity preprocessing, synthetic data generation, and retrieval strategy optimization. The framework's empirical gains suggest that domain adaptation and context structuring are critical for QA accuracy, especially in specialized or proprietary domains.
Future work may explore:
- Integration of advanced retrieval models (e.g., ColBERT, dense retrievers with cross-encoder reranking).
- Automated chunking strategies leveraging discourse segmentation or topic modeling.
- Enhanced answer evaluation with multi-judge ensembles or adversarial validation.
- Privacy-preserving RAG pipelines for sensitive data domains.
Conclusion
AccurateRAG provides a robust, modular framework for building high-accuracy RAG-based QA systems, validated by strong empirical results and comprehensive ablation studies. Its design principles—structural preservation, synthetic data generation, and adaptive retrieval—offer a blueprint for future RAG system development in both research and industry contexts.