- The paper introduces KVDirect, a framework that reduces LLM inference latency by 55% via optimized KV cache transfers.
- It utilizes a novel tensor-centric RDMA communication mechanism to bypass CPU overhead, enhancing GPU-NIC interaction efficiency.
- The framework implements dynamic GPU resource scheduling and a pull-based cache strategy, significantly improving scalability in distributed inference.
KVDirect: Distributed Disaggregated LLM Inference
Introduction
The paper "KVDirect: Distributed Disaggregated LLM Inference" addresses the inefficiencies in the current strategies for disaggregated inference in LLMs. Disaggregated inference separates the prefill and decode stages to enhance hardware utilization and improve service quality. However, existing solutions are restricted to single-node deployments due to constraints in inter-node communication, significantly impairing scalability and flexibility. This paper proposes KVDirect, a framework that optimizes KV cache transfer to facilitate distributed disaggregated LLM inference, achieving a notable reduction in per-request latency.
Disaggregated LLM Inference
Disaggregated inference divides the workload between two distinct workers: a prefill worker computing the KV cache for all tokens and a decode worker generating responses using this cache. Existing systems limit disaggregated inference to a single node, primarily relying on fast intra-node NV-Link for KV cache transfer, leading to resource allocation inflexibility and reduced overall service capacity. The research identifies the redundant synchronization and data movement as critical issues, which make only a small fraction of message-passing-based communication effective (Figure 1).
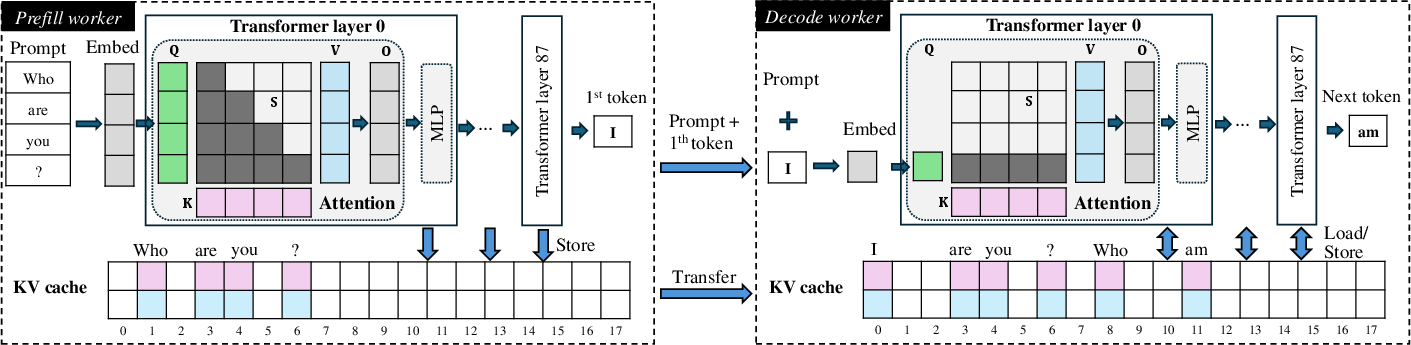
Figure 1: The workflow of disaggregated LLM inference with an emphasis on KV cache.
KVDirect's Innovations
The paper presents several key innovations:
- Tensor-centric Communication Mechanism: KVDirect introduces a communication mechanism that significantly reduces synchronization overhead by enabling direct RDMA-based transfers. This approach bypasses the CPU, allowing efficient GPU to NIC communication.
- Dynamic GPU Resource Scheduling: The system supports dynamic GPU resource scheduling that facilitates efficient KV cache transfers and optimizes resource utilization.
- Pull-based KV Cache Transfer Strategy: By adopting a pull-mode strategy, decode workers read data from prefill workers. This approach minimizes GPU resource idling and optimizes latency, enhancing performance under high query per second (QPS) scenarios (Figure 2).
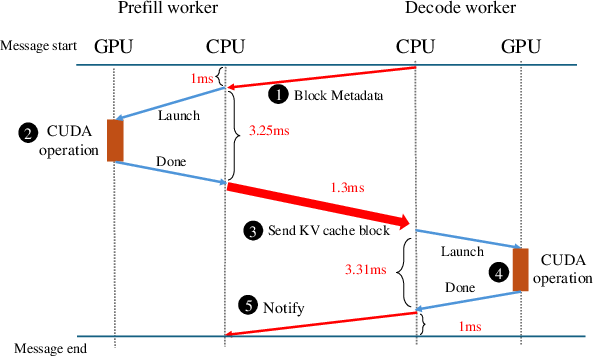
Figure 2: The message-based KV cache transfer with 4KB block size, where the blue and red arrows represent the communication over PCIe and network, respectively.
Experimental Results
The implementation of KVDirect demonstrated that it reduced per-request latency by 55% compared to a baseline across various workloads. This performance evaluation showcased improvements in the Time To First Token (TTFT) and Time Between Tokens (TBT), crucial metrics for LLM inference efficiency. KVDirect achieves high bandwidth use, demonstrating its effectiveness in handling long prompts and extensive response generation, without the constraints seen in previous systems (Figure 3).
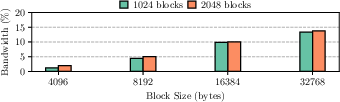
Figure 3: The achieved bandwidth of UCX message-sending.
Implications and Future Work
The implications of KVDirect are substantial, offering a path toward scalable, efficient distributed inference in LLMs. This work could lead to richer, more complex LLMs that are not limited by single-node deployments, unlocking potential use cases in real-time language processing applications and large-scale data interpretation tasks.
Future work suggested by the authors includes refining resource allocation strategies to adapt to changing workloads dynamically and further reducing latency through smarter GPU resource utilization strategies. The potential for broader adoption in diverse AI applications and industries is evident, as the demand for sophisticated LLMs continues to grow.
Conclusion
KVDirect represents a significant advancement in distributed disaggregated LLM inference. By optimizing inter-node communication and resource allocation, it provides a framework for more efficient and scalable inference operations. The reduction in latency and improved resource utilization positions KVDirect as a transformative solution in the evolving landscape of large-scale AI deployments.

