- The paper introduces a reinforcement learning framework that significantly improves complex reasoning evaluations over standard SFT methods.
- It employs group relative policy optimization and tailored reward design to boost key metrics like precision, recall, and F1 scores.
- Results show that JudgeLRM reduces bias and achieves consistent performance across diverse, reasoning-intensive tasks compared to baselines.
JudgeLRM: Large Reasoning Models as a Judge
This essay explores the implementation and evaluation of "JudgeLRM: Large Reasoning Models as a Judge," which investigates the use of LLMs as autonomous evaluators in scenarios requiring intricate reasoning. JudgeLRM aims to enhance judgment tasks by leveraging reinforcement learning (RL) to address the limitations of supervised fine-tuning (SFT) in high-reasoning demand domains.
Introduction
The traditional approach of using LLMs such as JudgeLM and PandaLM for evaluation is hindered by their inability to handle complex reasoning efficiently. This work questions whether LLM judges genuinely benefit from improved reasoning abilities. The researchers discover an inverse trend between SFT performance enhancements and tasks requiring reasoning.
JudgeLRM introduces RL with judge-wise, outcome-driven rewards to address these challenges. This model employs structured reasoning approaches and reveals a significant improvement over existing models such as GPT-4 and DeepSeek-R1, especially in tasks demanding deeper reasoning capabilities.
Methodology
Reward Design and RL Training
JudgeLRM's innovation lies in using a sophisticated reward model tailored for judge tasks. This model integrates both structural and content-based rewards, focusing on proper formatting, accurate alignment with ground truth, and levels of reasoning confidence. The inclusion of these elements promotes structured thinking and accurate scoring, distinguishing it from simpler SFT-based models.
The RL training employs Group Relative Policy Optimization (GRPO), which normalizes advantages within judgment groups to ensure stable training even when tasks are of varying difficulty or subject matter.
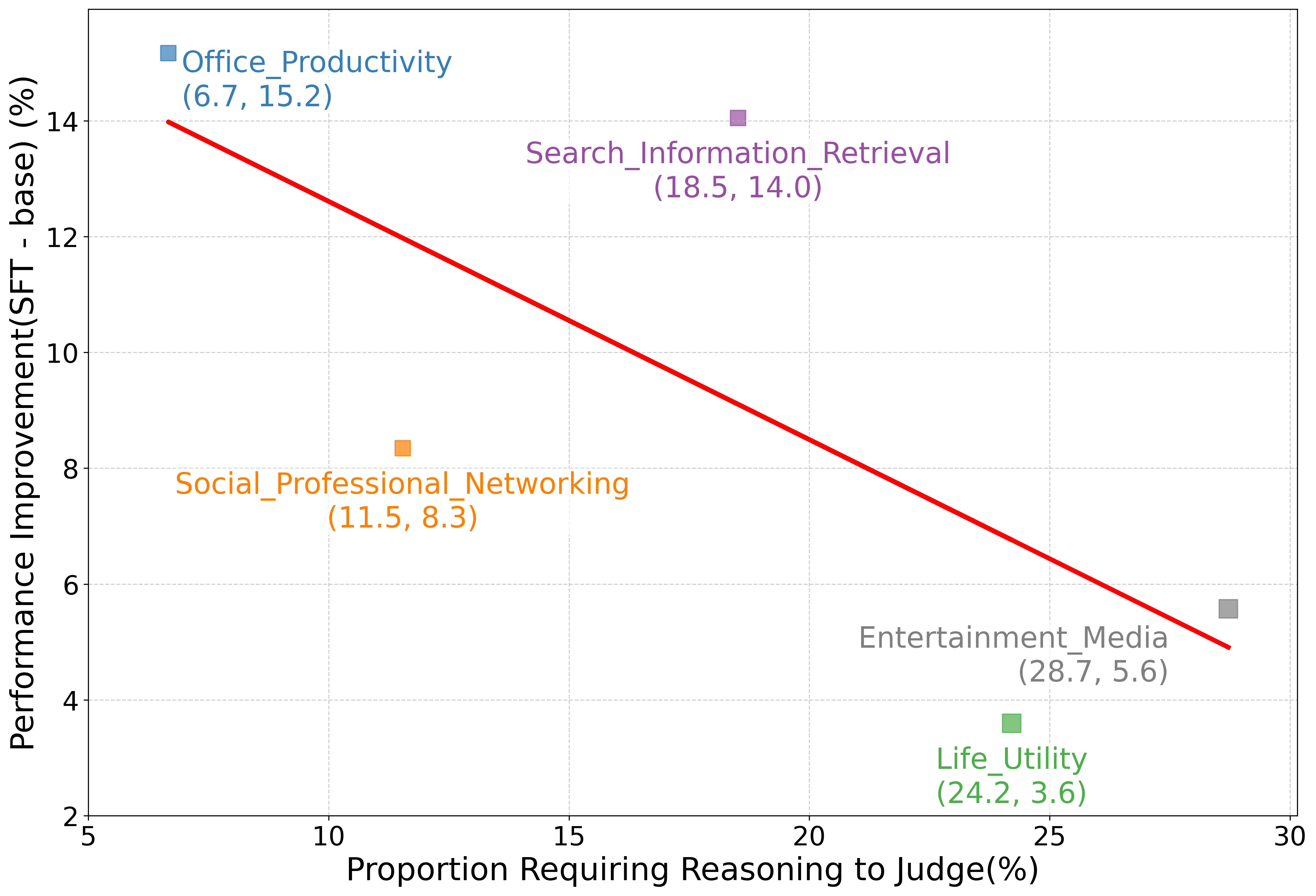
Figure 1: Judgment performance improvement vs. reasoning requirement across domain; a negative trend highlights the limitations of SFT alone.
Experimental Setup
Benchmarking against datasets like JudgeLM (GPT-4 annotations) and PandaLM (human annotations), JudgeLRM is rigorously tested. The datasets cover a wide range of topics to validate versatility across various reasoning demands. Moreover, the models are evaluated on metrics like agreement, precision, recall, and F1 score, establishing a comprehensive view of performance.
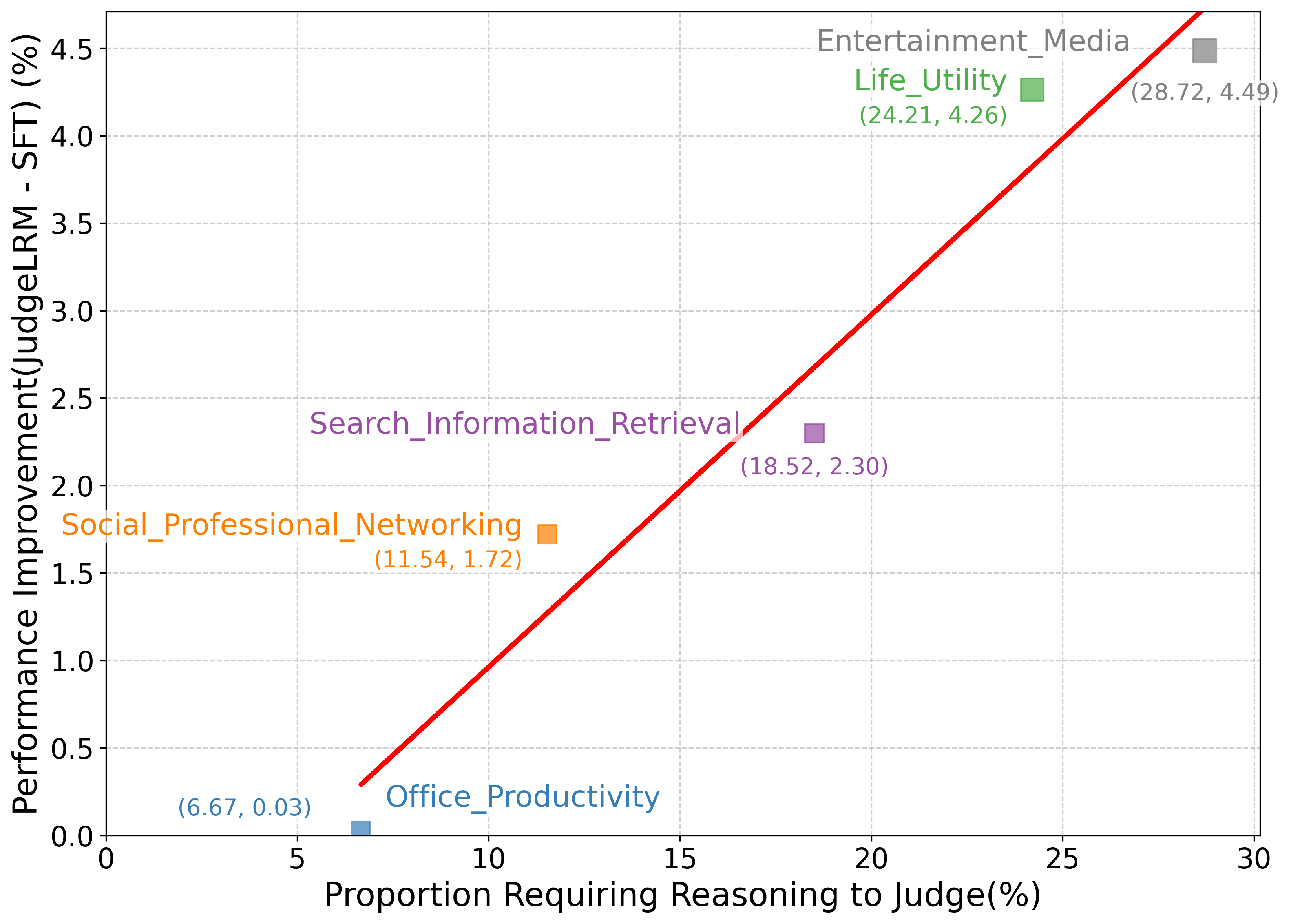
Figure 2: Performance improvements of JudgeLRM-7B over Qwen2.5-7B-Instruct-Judge-SFT in reasoning-intensive tasks.
Results and Discussion
JudgeLRM-7B demonstrates significant F1 score improvements, surpassing its competitors, especially on tasks with higher reasoning requirements. The model's success is attributed to its enhanced capacity to manage reasoning-heavy evaluations effectively.
Ablation and Reliability Studies
Ablation studies reveal the positive impact of comprehensive reward components, confirming the model's robustness and its dependency on incentives for accurate judgment. The length of responses during training correlates with thinking processes, although simply promoting longer responses without context can degrade performance.
Reliability is scrutinized by analyzing model consistency when answer positions are altered, with JudgeLRM showing reduced bias and improved consistency compared to its base models.
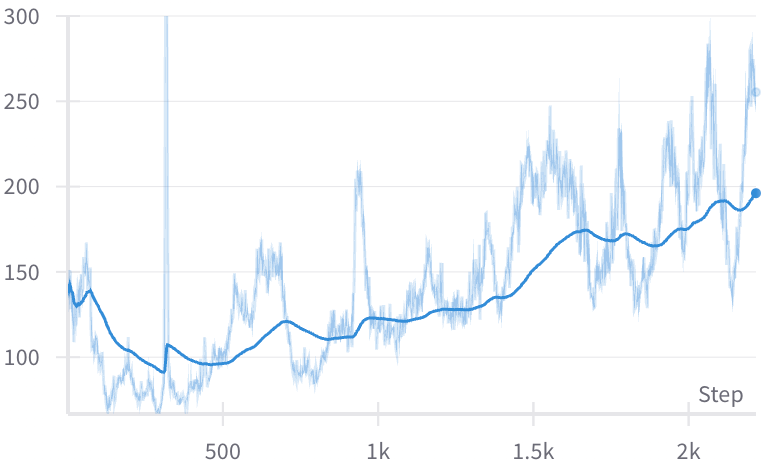
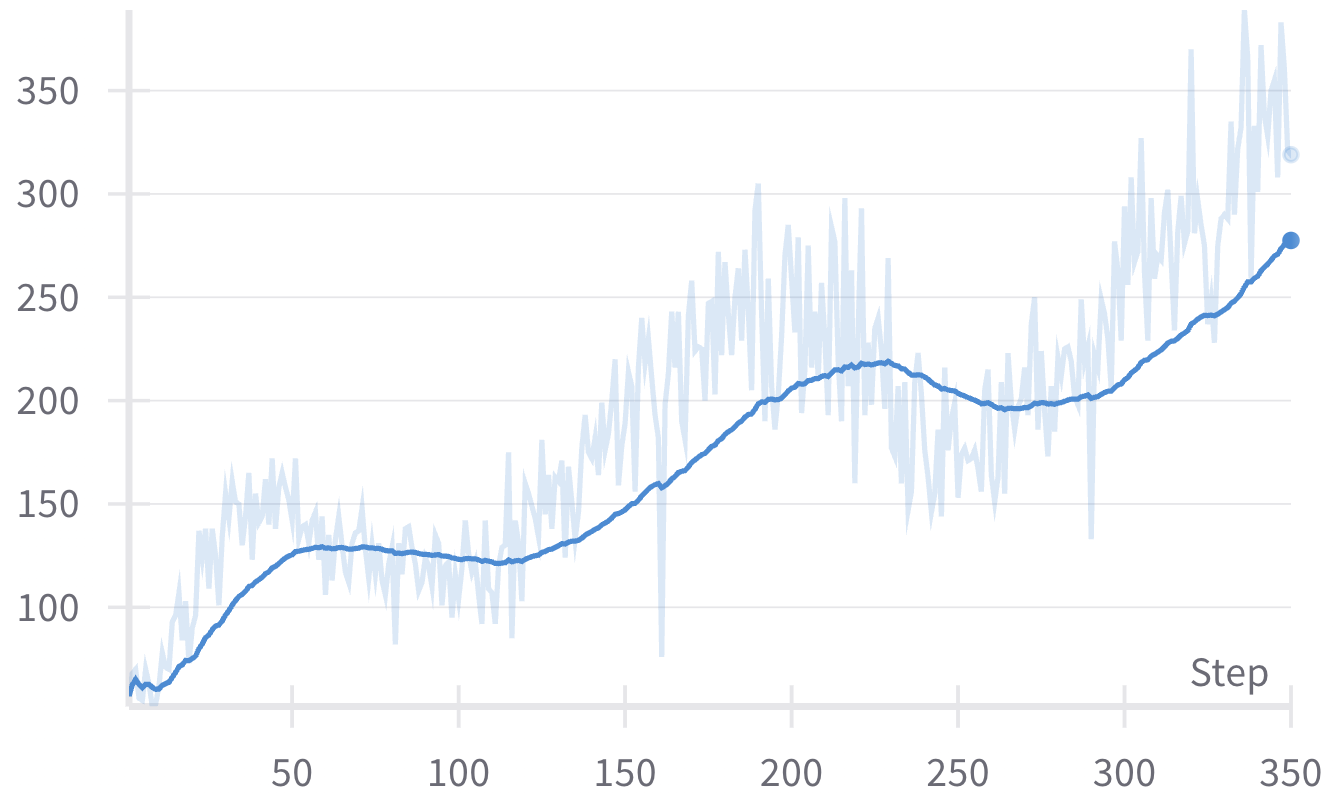
Figure 3: Response length correlation in JudgeLRM-3B and JudgeLRM-7B over training steps, indicating adjustment in thinking and answering strategies.
Conclusion
JudgeLRM exemplifies the potential of using RL to overcome SFT limitations, emphasizing judgment tasks' inherent reasoning-intensive nature. The developed framework highlights the structured reasoning path necessary for effective evaluation, suggesting future directions for large reasoning models that emphasize rigor and reliability in their judgment capabilities. This work exemplifies a strategic leap towards autonomous evaluations, potentially transforming various domains where judgments are crucial.

