- The paper introduces LinkAlign, a framework that resolves schema linking challenges in large-scale, multi-database Text-to-SQL tasks.
- It employs multi-round semantic retrieval and irrelevant information isolation to accurately select databases and extract precise schema components.
- Experimental results on datasets like Spider and AmbiDB demonstrate LinkAlign’s state-of-the-art performance using open-source LLMs.
Introduction
"LinkAlign: Scalable Schema Linking for Real-World Large-Scale Multi-Database Text-to-SQL" (2503.18596) addresses the challenge of schema linking in large-scale, multi-database environments for Text-to-SQL tasks. The paper identifies Database Retrieval and Schema Item Grounding as critical bottlenecks and proposes a framework named LinkAlign to resolve these issues. It offers a novel approach involving multi-round semantic retrieval, isolation of irrelevant schemas, and enhanced schema extraction. The framework aims to streamline the schema linking process, ultimately improving the accuracy of SQL generation in complex database settings.
Schema Linking Challenges
The difficulty in schema linking primarily stems from two challenges. Database Retrieval involves selecting the correct database from a large set, often containing redundant schemas. Effective retrieval must isolate relevant databases while filtering out noise. Schema Item Grounding focuses on accurately identifying the necessary tables and columns within complex schemas. Both tasks are essential for generating accurate SQL queries from natural language inputs.
Figure 1: Overview of the LinkAlign framework including three core components.
LinkAlign Framework
LinkAlign tackles these challenges through a modular approach divided into three key steps. Semantic Enhanced Retrieval focuses on Database Retrieval, employing query rewriting to infer missing schemas and enhance semantic alignment. This step dynamically adjusts retrieval strategies based on feedback, ensuring efficient recall of relevant databases. Irrelevant Information Isolation aims to eliminate schema noise, refining the target database localization process. Schema Extraction Enhancement scales schema linking by precisely identifying tables and columns necessary for SQL generation using advanced reasoning techniques.

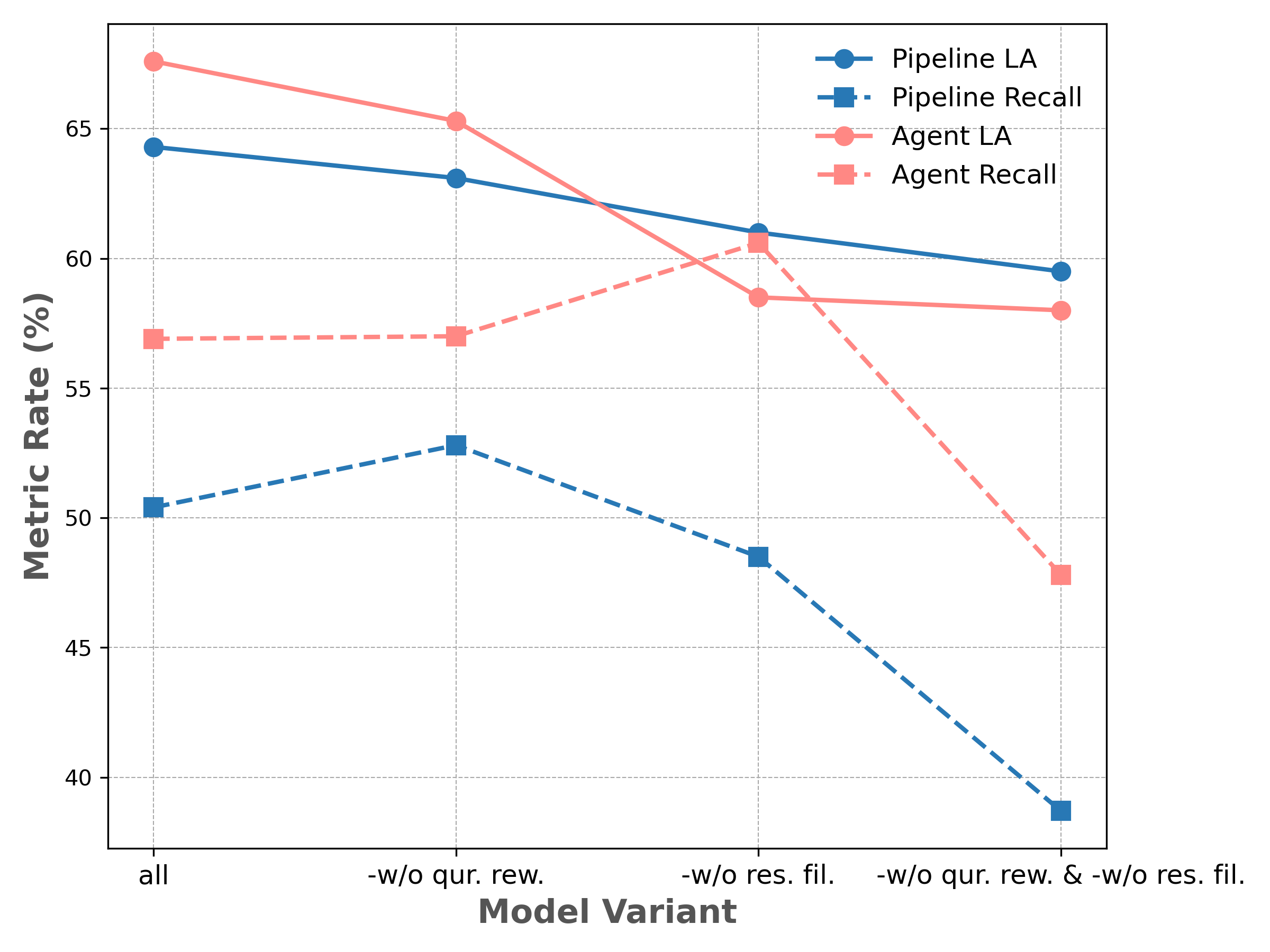
Figure 2: The impact on Error Rates.
Each component offers two execution paradigms—Pipeline and Agent. The Pipeline mode emphasizes efficiency, making it suitable for real-time applications, while the Agent mode prioritizes accuracy through collaborative multi-turn reasoning.
Experimental Evaluation
The framework's effectiveness is validated through comprehensive error analysis and evaluations on datasets like Spider, Bird, and AmbiDB. The introduction of the synthetic AmbiDB dataset allows for realistic testing, simulating large-scale, multi-database scenarios. Experiments show LinkAlign consistently surpasses baseline models, achieving state-of-the-art performance on schema linking metrics and improving the Text-to-SQL pipeline's scores on challenging Spider 2.0 benchmarks. Notably, LinkAlign reaches a top leaderboard score using only open-source LLMs, underscoring its practical viability.
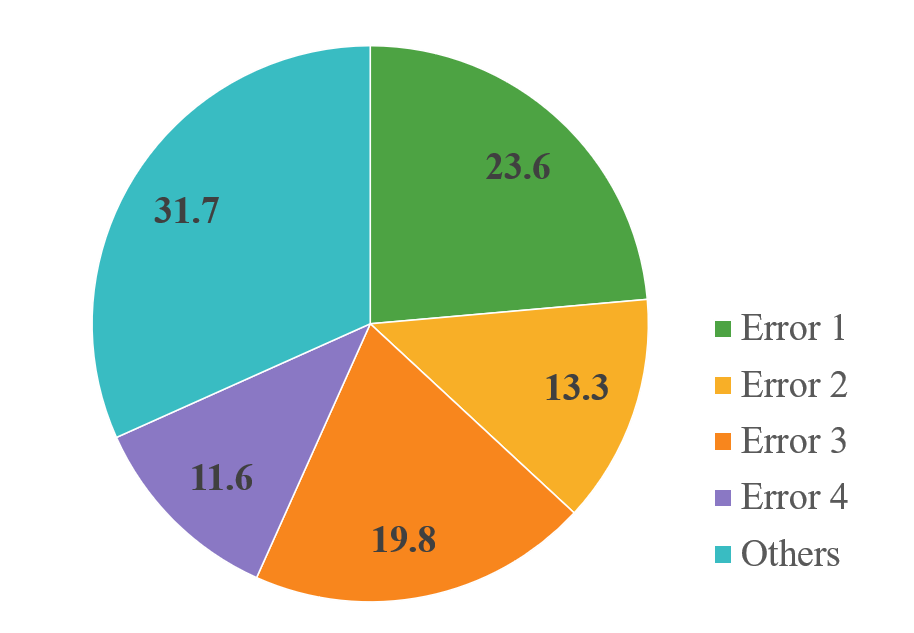
Figure 3: Error Distribution in Failed Cases.
Implications and Future Directions
LinkAlign sets a new precedence in schema linking for complex Text-to-SQL applications, demonstrating significant improvements in handling ambiguous and large-scale database schemas. This framework can facilitate better integration of LLMs in enterprise settings, potentially automating the translation of natural language to SQL with greater precision. Future work may explore enhancing retrieval strategies further or integrating more sophisticated reasoning capabilities to handle increasingly complex queries and schemas.
Conclusion
The LinkAlign framework presents a significant advancement in the field of Text-to-SQL, addressing critical challenges of schema linking in large-scale, multi-database environments. Its modular design and capability to dynamically adjust for efficiency and accuracy make it a robust solution for practical applications. As AI continues to evolve, frameworks like LinkAlign are poised to enable more intuitive and precise data retrieval solutions across diverse database systems.